Статистически значимые результаты. Основные термины и понятия медицинской статистики. Правило отклонения Hо и принятия h1
Проверка гипотез проводится с помощью статистического анализа. Статистическую значимость находят с помощью Р-значения, которое соответствует вероятности данного события при предположении, что некоторое утверждение (нулевая гипотеза) истинно. Если Р-значение меньше заданного уровня статистической значимости (обычно это 0,05), экспериментатор может смело заключить, что нулевая гипотеза неверна, и перейти к рассмотрению альтернативной гипотезы. С помощью t-критерия Стьюдента можно вычислить Р-значение и определить значимость для двух наборов данных.
Шаги
Часть 1
Постановка эксперимента- Нулевая гипотеза (H 0) обычно утверждает, что между двумя наборами данных нет разницы. Например: те ученики, которые читают материал перед занятиями, не получают более высокие оценки.
- Альтернативная гипотеза (H a) противоположна нулевой гипотезе и представляет собой утверждение, которое нужно подтвердить с помощью экспериментальных данных. Например: те ученики, которые читают материал перед занятиями, получают более высокие оценки.
-
Установите уровень значимости, чтобы определить, насколько распределение данных должно отличаться от обычного, чтобы это можно было считать значимым результатом. Уровень значимости (его называют также α {\displaystyle \alpha } -уровнем) - это порог, который вы определяете для статистической значимости. Если Р-значение меньше уровня значимости или равно ему, данные считаются статистически значимыми.
- Как правило, уровень значимости (значение α {\displaystyle \alpha } ) принимается равным 0,05, и в этом случае вероятность обнаружения случайной разницы между разными наборами данных составляет всего лишь 5%.
- Чем выше уровень значимости (и, соответственно, меньше Р-значение), тем достовернее результаты.
- Если вы хотите получить более достоверные результаты, понизьте Р-значение до 0,01. Как правило, более низкие Р-значения используются в производстве, когда необходимо выявить брак в продукции. В этом случае требуется высокая достоверность, чтобы быть уверенным, что все детали работают так, как положено.
- Для большинства экспериментов с гипотезами достаточно принять уровень значимости равным 0,05.
-
Решите, какой критерий вы будете использовать: односторонний или двусторонний. Одно из предположений в t-критерии Стьюдента гласит, что данные распределены нормальным образом. Нормальное распределение представляет собой колоколообразную кривую с максимальным количеством результатов посередине кривой. t-критерий Стьюдента - это математический метод проверки данных, который позволяет установить, выпадают ли данные за пределы нормального распределения (больше, меньше, либо в “хвостах” кривой).
- Если вы не уверены, находятся ли данные выше или ниже контрольной группы значений, используйте двусторонний критерий. Это позволит вам определить значимость в обоих направлениях.
- Если вы знаете, в каком направлении данные могут выйти за пределы нормального распределения, используйте односторонний критерий. В приведенном выше примере мы ожидаем, что оценки студентов повысятся, поэтому можно использовать односторонний критерий.
-
Определите объем выборки с помощью статистической мощности. Статистическая мощность исследования - это вероятность того, что при данном объеме выборки получится ожидаемый результат. Распространенный порог мощности (или β) составляет 80%. Анализ статистической мощности без каких-либо предварительных данных может представлять определенные сложности, поскольку требуется некоторая информация об ожидаемых средних значениях в каждой группе данных и об их стандартных отклонениях. Используйте для анализа статистической мощности онлайн-калькулятор, чтобы определить оптимальный объем выборки для ваших данных.
- Обычно ученые проводят небольшое пробное исследование, которое позволяет получить данные для анализа статистической мощности и определить объем выборки, необходимый для более расширенного и полного исследования.
- Если у вас нет возможности провести пробное исследование, постарайтесь на основании литературных данных и результатов других людей оценить возможные средние значения. Возможно, это поможет вам определить оптимальный объем выборки.
Часть 2
Вычислите стандартное отклонение-
Запишите формулу для стандартного отклонения. Стандартное отклонение показывает, насколько велик разброс данных. Оно позволяет заключить, насколько близки данные, полученные на определенной выборке. На первый взгляд формула кажется довольно сложной, но приведенные ниже объяснения помогут понять ее. Формула имеет следующий вид: s = √∑((x i – µ) 2 /(N – 1)).
- s - стандартное отклонение;
- знак ∑ указывает на то, что следует сложить все полученные на выборке данные;
- x i соответствует i-му значению, то есть отдельному полученному результату;
- µ - это среднее значение для данной группы;
- N - общее число данных в выборке.
-
Найдите среднее значение в каждой группе. Чтобы вычислить стандартное отклонение, необходимо сначала найти среднее значение для каждой исследуемой группы. Среднее значение обозначается греческой буквой µ (мю). Чтобы найти среднее, просто сложите все полученные значения и поделите их на количество данных (объем выборки).
- Например, чтобы найти среднюю оценку в группе тех учеников, которые изучают материал перед занятиями, рассмотрим небольшой набор данных. Для простоты используем набор из пяти точек: 90, 91, 85, 83 и 94.
- Сложим вместе все значения: 90 + 91 + 85 + 83 + 94 = 443.
- Поделим сумму на число значений, N = 5: 443/5 = 88,6.
- Таким образом, среднее значение для данной группы составляет 88,6.
-
Вычтите из среднего каждое полученное значение. Следующий шаг заключается в вычислении разницы (x i – µ). Для этого следует вычесть из найденной средней величины каждое полученное значение. В нашем примере необходимо найти пять разностей:
- (90 – 88,6), (91- 88,6), (85 – 88,6), (83 – 88,6) и (94 – 88,6).
- В результате получаем следующие значения: 1,4, 2,4, -3,6, -5,6 и 5,4.
-
Возведите в квадрат каждую полученную величину и сложите их вместе. Каждую из только что найденных величин следует возвести в квадрат. На этом шаге исчезнут все отрицательные значения. Если после данного шага у вас останутся отрицательные числа, значит, вы забыли возвести их в квадрат.
- Для нашего примера получаем 1,96, 5,76, 12,96, 31,36 и 29,16.
- Складываем полученные значения: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Поделите на объем выборки минус 1. В формуле сумма делится на N – 1 из-за того, что мы не учитываем генеральную совокупность, а берем для оценки выборку из числа всех студентов.
- Вычитаем: N – 1 = 5 – 1 = 4
- Делим: 81,2/4 = 20,3
-
Извлеките квадратный корень. После того как вы поделите сумму на объем выборки минус один, извлеките из найденного значения квадратный корень. Это последний шаг в вычислении стандартного отклонения. Есть статистические программы, которые после введения начальных данных производят все необходимые вычисления.
- В нашем примере стандартное отклонение оценок тех учеников, которые читают материал перед занятиями, составляет s =√20,3 = 4,51.
Часть 3
Определите значимость-
Рассчитайте дисперсию между двумя группами данных. До этого шага мы рассматривали пример лишь для одной группы данных. Если вы хотите сравнить две группы, очевидно, следует взять данные для обеих групп. Вычислите стандартное отклонение для второй группы данных, а затем найдите дисперсию между двумя экспериментальными группами. Дисперсия вычисляется по следующей формуле: s d = √((s 1 /N 1) + (s 2 /N 2)).
Определите свою гипотезу. Первый шаг при оценке статистической значимости состоит в том, чтобы выбрать вопрос, ответ на который вы хотите получить, и сформулировать гипотезу. Гипотеза - это утверждение об экспериментальных данных, их распределении и свойствах. Для любого эксперимента существует как нулевая, так и альтернативная гипотеза. Вообще говоря, вам придется сравнивать два набора данных, чтобы определить, схожи они или различны.
Статистическая достоверность имеет существенное значение в расчетной практике ФКС. Ранее было отмечено, что из одной и той же генеральной совокупности может быть избрано множество выборок:
Если они подобраны корректно, то их средние показатели и показатели генеральной совокупности незначительно отличаются друг от друга величиной ошибки репрезентативности с учетом принятой надежности;
Если они избираются из разных генеральных совокупностей, различие между ними оказывается существенным. В статистике повсеместно рассматривается сравнение выборок;
Если они отличаются несущественно, непринципиально, незначительно, т. е. фактически принадлежат одной и той же генеральной совокупности, различие между ними называется статистически недостоверным.
Статистически достоверным различием выборок называется выборка, которая различается значимо и принципиально, т. е. принадлежит разным генеральным совокупностям.
В ФКС оценка статистической достоверности различий выборок означает решение множества практических задач. Например, введение новых методик обучения, программ, комплексов упражнений, тестов, контрольных упражнений связано с их экспериментальной проверкой, которая должна показать, что испытуемая группа принципиально отлична от контрольной. Поэтому применяют специальные статистические методы, называемые критериями статистической достоверности, позволяющие обнаружить наличие или отсутствие статистически достоверного различия между выборками.
Все критерии делятся на две группы: параметрические и непараметрические. Параметрические критерии предусматривают обязательное наличие нормального закона распределения, т.е. имеется в виду обязательное определение основных показателей нормального закона - средней арифметической величины и среднего квадратического отклонения s. Параметрические критерии являются наиболее точными и корректными. Непараметрические критерии основаны на ранговых (порядковых) отличиях между элементами выборок.
Приведем основные критерии статистической достоверности, используемые в практике ФКС: критерий Стьюдента и критерий Фишера.
Критерий Стьюдента назван в честь английского ученого К. Госсета (Стьюдент - псевдоним), открывшего данный метод. Критерий Стьюдента является параметрическим, используется для сравнения абсолютных показателей выборок. Выборки могут быть различными по объему.
Критерий Стьюдента определяется так.
1. Находим критерий Стьюдента t по следующей формуле:
где - средние арифметические сравниваемых выборок; т 1 , т 2 - ошибки репрезентативности, выявленные на основании показателей сравниваемых выборок.
2. Практика в ФКС показала, что для спортивной работы достаточно принять надежность счета Р = 0,95.
Для надежности счета: Р = 0,95 (a = 0,05), при числе степеней свободы
k = n 1 + п 2 - 2 по таблице приложения 4 находим величину граничного значения критерия (t гр ).
3. На основании свойств нормального закона распределения в критерии Стьюдента осуществляется сравнение t и t гр.
Делаем выводы:
если t t гр, то различие между сравниваемыми выборками статистически достоверно;
если t t гр, то различие статистически недостоверно.
Для исследователей в области ФКС оценка статистической достоверности является первым шагом в решении конкретной задачи: принципиально или непринципиально различаются между собой сравниваемые выборки. Последующий шаг заключается в оценке этого различия с педагогической точки зрения, что определяется условием задачи.
Рассмотрим применение критерия Стьюдента на конкретном примере.
Пример 2.14. Группа испытуемых в количестве 18 человек оценена на ЧСС (уд./мин) до х i и после y i разминки.
Оценить эффективность разминки по показателю ЧСС. Исходные данные и расчеты представлены в табл. 2.30 и 2.31.
Таблица 2.30
Обработка показателей ЧСС до разминки
Ошибки по обеим группам совпали, так как объемы выборок равны (исследуется одна и та же группа при различных условиях), а средние квадратические отклонения составили s х = s у = 3 уд./мин. Переходим к определению критерия Стьюдента:
Задаем надежность счета: Р= 0,95.
Число степеней свободы k 1 = n 1 + п 2 - 2=18+18-2 = 34. По таблице приложения 4 находим t гр = 2,02.
Статистический вывод. Поскольку t = 11,62, а граничное t гр = 2,02, то 11,62 > 2,02, т.е. t > t гр, поэтому различие между выборками статистически достоверно.
Педагогический вывод. Установлено, что по показателю ЧСС различие между состоянием группы до и после разминки является статистически достоверным, т.е. значимым, принципиальным. Итак, по показателю ЧСС можно сделать вывод, что разминка эффективна.
Критерий Фишера является параметрическим. Он применяется при сравнении показателей рассеивания выборок. Это, как правило, означает сравнение по показателям стабильности спортивной работы или стабильности функциональных и технических показателей в практике физической культуры и спорта. Выборки могут быть разновеликими.
Критерий Фишера определяется в нижеприведенной последовательности.
1. Находим Критерий Фишера F по формуле
где , - дисперсии сравниваемых выборок.
Условиями критерия Фишера предусмотрено, что в числителе формулы F находится большая дисперсия, т.е. число F всегда больше единицы.
Задаем надежность счета: Р = 0,95 - и определяем числа степеней свободы для обеих выборок: k 1 = n 1 - 1 , k 2 = п 2 - 1.
По таблице приложения 4 находим граничное значение критерия F гр .
Сравнение критериев F и F гр позволяет сформулировать выводы:
если F > F гр, то различие между выборками статистически достоверно;
если F< F гр, то различие между выборками статически недостоверно.
Приведем конкретный пример.
Пример 2.15. Проанализируем две группы гандболистов: х i (n 1 = 16 человек) и y i (п 2 = 18 человек). Эти группы спортсменов исследованы на время отталкивания (с) при броске мяча в ворота.
Однотипны ли показатели отталкивания?
Исходные данные и основные расчеты представлены в табл. 2.32 и 2.33.
Таблица 2.32
Обработка показателей отталкивания первой группы гандболистов
Определим критерий Фишера:
По данным, представленным в таблице приложения 6, находим Fгр: Fгр = 2,4
Обратим внимание на то, что в таблице приложения 6 перечисление чисел степеней свободы как большей, так и меньшей дисперсии при приближении к большим числам становится грубее. Так, числа степеней свободы большей дисперсии следует в таком порядке: 8, 9, 10, 11, 12, 14, 16, 20, 24 и т.д., а меньшей - 28, 29, 30, 40, 50 и т.д.
Это объясняется тем, что при увеличении объема выборок различия F-критерия уменьшаются и можно использовать табличные значения, приближенные к исходным данным. Так, в примере 2.15 =17 отсутствует и можно принять ближайшее к нему значение k = 16, откуда и получаем Fгр = 2,4.
Статистический вывод. Поскольку критерий Фишера F= 2,5 > F= 2,4, выборки различимы статистически достоверно.
Педагогический вывод. Значения времени отталкивания (с) при броске мяча в ворота у гандболистов обеих групп существенно различаются. Эти группы следует рассматривать как различные.
Дальнейшие исследования должны показать, в чем причина такого различия.
Пример 2.20 .(на статистическую достоверность выборки ). Повысилась ли квалификация футболиста, если время (с) от подачи сигнала до удара по мячу ногой в начале тренировки было x i , а в конце у i .
Исходные данные и основные расчеты приведены в табл. 2.40 и 2.41.
Таблица 2.40
Обработка показателей времени от подачи сигнала до удара по мячу в начале тренировки
Определим различие групп показателей по критерию Стьюдента:
![]()
При надежности Р = 0,95 и степенях свободы k = n 1 + п 2 - 2 = 22 + 22 - 2 = 42 по таблице приложения 4 находим t гр = 2,02. Поскольку t = 8,3 > t гр = 2,02 - различие статистически достоверно.
Определим различие групп показателей по критерию Фишера:
| |
По таблице приложения 2 при надежности Р = 0,95 и степенях свободы k = 22-1=21 значение F гр = 21. Поскольку F= 1,53 < F гр = = 2,1, различие в рассеивании исходных данных статистически недостоверно.
Статистический вывод. По среднему арифметическому показателю различие групп показателей статистически достоверно. По показателю рассеивания (дисперсии) различие групп показателей статистически недостоверно.
Педагогический вывод. Квалификация футболиста существенно повысилась, однако следует уделить внимание стабильности его показаний.
Подготовка к работе
Перед проведением данной лабораторной работы по дисциплине «Спортивная метрология» всем студентам учебной группы необходимо сформировать рабочие бригады по 3-4 студента в каждой , для совместного выполнения рабочего задания всех лабораторных работ.
При подготовке к работе ознакомиться с соответствующими разделами рекомендуемой литературы (см.раздел 6 данных методических указаний) и конспектов лекций. Изучить разделы 1 и 2 на данную лабораторную работу, а также рабочее задание на неё (раздел 4).
Заготовить форму отчета на стандартных листах писчей бумаги формата А4 и занести в нее материалы необходимые для работы.
Отчет должен содержать :
Титульный лист с указанием кафедры (УК и ТР), учебной группы, фамилии, имени, отчества студента, номера и названия лабораторной работы, даты ее выполнения, а также фамилии, учёной степени, учёного звания и должности преподавателя, принимающего работу;
Цель работы;
Формулы с числовыми значениями, поясняющие промежуточные и окончательные результаты вычислений;
Таблицы измеренных и вычисленных величин;
Требуемый по заданию графический материал;
Краткие выводы по результатам каждого из этапов рабочего задания и в целом по выполненной работе.
Все графики и таблицы вычерчиваются аккуратно при помощи чертежных инструментов. Условные графические и буквенные обозначения должны соответствовать ГОСТам. Допускается оформление отчёта с применением вычислительной (компьютерной) техники.
Перед проведением всех измерений каждому члену бригады необходимо изучить правила использования спортивной игры Дартс, приведенные в приложении 7, которые необходимы для проведения нижеприведенных этапов исследований.
I – й этап исследований «Исследование результатов попаданий в мишень спортивной игры Дартс каждым членом бригады на соответствие нормальному закону распределения по критерию χ 2 Пирсона и критерию трёх сигм»
1. провести измерение (испытание) своей (личной) быстроты и координированности действий, путём бросания 30-40 раз дротиков в круговую мишень спортивной игры Дартс.
2. Результаты измерений (испытаний) x i (в очках) оформить в виде вариационного ряда и занести в таблицу 4.1 (столбцы , выполнить все необходимые расчёты, заполнить необходимые таблицы и сделать соответствующие выводы на соответствие полученного эмпирического распределения нормальному закону распределения, по аналогии с аналогичными расчётами, таблицами и выводами примера 2.12, приведенного в разделе 2 данных методических указаний на страницах 7 -10.
Таблица 4.1
Соответствие быстроты и координированности действий испытуемых нормальному закону распределения
| № п/п | округ- ленно | |||||||||
| … | ||||||||||
| … | ||||||||||
| Всего |
II – й этап исследований
«Оценка средних показателей генеральной совокупности попаданий в мишень спортивной игры Дартс всех студентов учебной группы по результатам измерений членов одной бригады»
Оценить средние показатели быстроты и координированности действий всех студентов учебной группы (согласно списка учебной группы классного журнала) по результатам попаданий в мишень спортивной игры Дартс всех членов бригады, полученным на первом этапе исследований данной лабораторной работы.
1. Оформить результаты измерений быстроты и координированности действий при бросании дротиков в круговую мишень спортивной игры Дартс всех членов Вашей бригады (2 – 4 человека), которые представляют собой выборку результатов измерений из генеральной совокупности (результаты измерений всех студентов учебной группы – например, 15 человек), занеся их во второй и третий столбцы таблицы 4.2.
Таблица 4.2
Обработка показателей быстроты и координированности действий
членов бригады
| № п/п | ||||||
| … | ||||||
| … | ||||||
| Всего |
В таблице 4.2 под следует понимать , совпавшее среднее количество баллов (см. результаты расчётов по таблице 4.1) членами Вашей бригады ( , полученное на первом этапе исследований. Следует заметить, что, как правило, в таблице 4.2 есть рассчитанное среднее значение результатов измерений полученное одним членом бригады на первом этапе исследований , так как вероятность, того что результаты измерений различными членами бригады совпадут очень мала. Тогда, как правило, значения в столбце таблицы 4.2 для каждой из строк - равны 1, а в строке «Всего » графы « », записывается число членов Вашей бригады.
2. Выполнить все необходимые расчёты по заполнению таблицы 4.2, а также другие расчёты и выводы, аналогичные расчётам и выводам примера 2.13, приведенным в 2-ом разделе данной методической разработки на страницах 13-14. Следует иметь ввиду, при расчёте ошибки репрезентативности «m» необходимо использовать формулу 2.4, приведенную на странице 13 данной методической разработки, так как выборка мала (n , а число элементов генеральной совокупности N известно, и равно числу студентов учебной группы, согласно списка журнала учебной группы.
III – й этап исследований
Оценка эффективности разминки по показателю «Быстрота и координированность действий» каждым членом бригады с помощью критерия Стьюдента
Оценить эффективность разминки по бросанию дротиков в мишень спортивной игры «Дартс», выполненную на первом этапе исследований данной лабораторной работы, каждым членом бригады по показателю «Быстрота и координированность действий», с помощью критерия Стьюдента - параметрического критерия статистической достоверности эмпирического закона распределения нормальному закону распределения.
2. дисперсии и СКО , результатов измерений показателя «Быстрота и координированность действий» по результатам разминки, приведенных в таблице 4.3, (см. аналогичные расчёты приведенные сразу после таблицы 2.30 примера 2.14 на странице 16 данной методической разработки).
3. Каждому члену рабочей бригады провести измерение (испытание) своей (личной) быстроты и координированности действий после разминки,
5. Произвести вычисления среднего значения дисперсии и СКО , результатов измерений показателя «Быстрота и координированность действий» после разминки, приведенных в таблице 4.4, записать в целом результат измерений по результатам разминки (см. аналогичные расчеты, приведенные сразу после таблицы 2.31 примера 2.14 на странице 17 данной методической разработки).
6. Выполнить все необходимые расчёты и выводы, аналогичные расчётам и выводам примера 2.14, приведенным в 2-ом разделе данной методической разработки на страницах 16-17. Следует иметь ввиду, при расчёте ошибки репрезентативности «m» необходимо использовать формулу 2.1, приведенную на странице 12 данной методической разработки, так как выборка n , а число элементов генеральной совокупности N ( неизвестно.
IV – й этап исследований
Оценка однотипности (стабильности) показателей «Быстрота и координированность действий» двух членов бригады с помощью критерия Фишера
Оценить однотипность (стабильность) показателей «Быстрота и координированность действий» двух членов бригады с помощью критерия Фишера, по результатам измерений, полученным на третьем этапе исследований данной лабораторной работы.
Для этого необходимо выполнить следующее.
Используя данные таблиц 4.3 и 4.4, результаты расчётов дисперсий по этим таблицам , полученные на третьем этапе исследований, а также методику расчёта и применения критерия Фишера для оценки однотипности (стабильности) спортивных показателей, приведенную в примере 2.15 на страницах 18-19 данной методической разработки, сделать соответствующие статистический и педагогический выводы.
V – й этап исследований
Оценка групп показателей «Быстрота и координированность действий» одного члена бригады до и после разминки
Статистическая значимость или р-уровень значимости - основной результат проверки
статистической гипотезы. Говоря техническим языком, это вероятность получения данного
результата выборочного исследования при условии, что на самом деле для генеральной
совокупности верна нулевая статистическая гипотеза - то есть связи нет. Иначе говоря, это
вероятность того, что обнаруженная связь носит случайный характер, а не является свойством
совокупности. Именно статистическая значимость, р-уровень значимости является
количественной оценкой надежности связи: чем меньше эта вероятность, тем надежнее связь.
Предположим, при сравнении двух выборочных средних было получено значение уровня
статистической значимости р=0,05. Это значит, что проверка статистической гипотезы о
равенстве средних в генеральной совокупности показала, что если она верна, то вероятность
случайного появления обнаруженных различий составляет не более 5%. Иначе говоря, если бы
две выборки многократно извлекались из одной и той же генеральной совокупности, то в 1 из
20 случаев обнаруживалось бы такое же или большее различие между средними этих выборок.
То есть существует 5%-ная вероятность того, что обнаруженные различия носят случайный
характер, а не являются свойством совокупности.
В отношении научной гипотезы уровень статистической значимости – это количественный
показатель степени недоверия к выводу о наличии связи, вычисленный по результатам
выборочной, эмпирической проверки этой гипотезы. Чем меньше значение р-уровня, тем выше
статистическая значимость результата исследования, подтверждающего научную гипотезу.
Полезно знать, что влияет на уровень значимости. Уровень значимости при прочих равных
условиях выше (значение р-уровня меньше), если:
Величина связи (различия) больше;
Изменчивость признака (признаков) меньше;
Объем выборки (выборок) больше.
Односторонние еpи двусторонние критерии проверки значимости
Если цель исследования том, чтобы выявить различие параметров двух генеральных
совокупностей, которые соответствуют различным ее естественным условиям (условия жизни,
возраст испытуемых и т. п.), то часто неизвестно, какой из этих параметров будет больше, а
какой меньше.
Например, если интересуются вариативностью результатов в контрольной и
экспериментальной группах, то, как правило, нет уверенности в знаке различия дисперсий или
стандартных отклонений результатов, по которым оценивается вариативность. В этом случае
нулевая гипотеза состоит в том, что дисперсии равны между собой, а цель исследования -
доказать обратное, т.е. наличие различия между дисперсиями. При этом допускается, что
различие может быть любого знака. Такие гипотезы называются двусторонними.
Но иногда задача состоит в том, чтобы доказать увеличение или уменьшение параметра;
например, средний результат в экспериментальной группе выше, чем контрольной. При этом
уже не допускается, что различие может быть другого знака. Такие гипотезы называются
Односторонними.
Критерии значимости, служащие для проверки двусторонних гипотез, называются
Двусторонними, а для односторонних - односторонними.
Возникает вопрос о том, какой из критериев следует выбирать в том или ином случае. Ответ
На этот вопрос находится за пределами формальных статистических методов и полностью
Зависит от целей исследования. Ни в коем случае нельзя выбирать тот или иной критерий после
Проведения эксперимента на основе анализа экспериментальных данных, поскольку это может
Привести к неверным выводам. Если до проведения эксперимента допускается, что различие
Сравниваемых параметров может быть как положительным, так и отрицательным, то следует
Как вы думаете, что делает вашу «вторую половинку» особенной, значимой? Это связано с ее (его) личностью или с вашими чувствами, которые вы испытываете к этому человеку? А может, с простым фактом, что гипотеза о случайности вашей симпатии, как показывают исследования, имеет вероятность менее 5%? Если считать последнее утверждение достоверным, то успешных сайтов знакомств не существовало бы в принципе:
Когда вы проводите сплит-тестирование или любой другой анализ вашего сайта, неверное понимание «статистической значимости» может привести к неправильной интерпретации результатов и, следовательно, ошибочным действиям в процессе оптимизации конверсии. Это справедливо и для тысяч других статистических тестов, проводимых ежедневно в любой существующей отрасли.
Чтобы разобраться, что же такое «статистическая значимость», необходимо погрузиться в историю появления этого термина, познать его истинный смысл и понять, как это «новое» старое понимание поможет вам верно трактовать результаты своих исследований.
Немного истории
Хотя человечество использует статистику для решения тех или иных задач уже много веков, современное понимание статистической значимости, проверки гипотез, рандомизации и даже дизайна экспериментов (Design of Experiments (DOE) начало формироваться только в начале 20-го столетия и неразрывно связано с именем сэра Рональда Фишера (Sir Ronald Fisher, 1890-1962):

Рональд Фишер был эволюционным биологом и статистиком, который имел особую страсть к изучению эволюции и естественного отбора в животном и растительном мире. В течение своей прославленной карьеры он разработал и популяризировал множество полезных статистических инструментов, которыми мы пользуемся до сих пор.
Фишер использовал разработанные им методики, чтобы объяснить такие процессы в биологии, как доминирование, мутации и генетические отклонения. Те же инструменты мы можем применить сегодня для оптимизации и улучшения контента веб-ресурсов. Тот факт, что эти средства анализа могут быть задействованы для работы с предметами, которых на момент их создания даже не существовало, кажется довольно удивительным. Столь же удивительно, что раньше сложнейшие вычисления люди выполняли без калькуляторов или компьютеров.
Для описания результатов статистического эксперимента как имеющих высокую вероятность оказаться истиной Фишер использовал слово «значимость» (от англ. significance).
Также одной из наиболее интересных разработок Фишера можно назвать гипотезу «сексуального сына». Согласно этой теории, женщины отдают свое предпочтение неразборчивым в половых связях мужчинам (гулящим), потому что это позволит рожденным от этих мужчин сыновьям иметь такую же предрасположенность и произвести на свет больше своих отпрысков (обращаем внимание, что это всего лишь теория).
Но никто, даже гениальные ученые, не застрахованы от совершения ошибок. Огрехи Фишера досаждают специалистам и по сей день. Но помните слова Альберта Эйнштейна: «Кто никогда не ошибался, тот не создавал ничего нового».
Прежде чем перейти к следующему пункту, запомните: статистическая значимость — это ситуация, когда разница в результатах при проведении тестирования настолько велика, что эту разницу нельзя объяснить влиянием случайных факторов.
Какова ваша гипотеза?
Чтобы понять, что значит «статистическая значимость», сначала нужно разобраться с тем, что такое «проверка гипотез», поскольку два этих термина тесно переплетаются.
Гипотеза — это всего лишь теория. Как только вы разработаете какую-либо теорию, вам будет необходимо установить порядок сбора достаточного количества доказательств и, собственно, собрать эти доказательства. Существует два типа гипотез.

Яблоки или апельсины — что лучше?
Нулевая гипотеза
Как правило, именно в этом месте многие испытывают трудности. Нужно иметь в виду, что нулевая гипотеза — это не то, что нужно доказать, как, например, вы доказываете, что определенное изменение на сайте приведет к повышению конверсии, а наоборот. Нулевая гипотеза — это теория, которая гласит, что при внесении каких-либо изменений на сайт ничего не произойдет. И цель исследователя — опровергнуть эту теорию, а не доказать.
Если обратиться к опыту раскрытия преступлений, где следователи также строят гипотезы в отношении того, кто является преступником, нулевая гипотеза принимает вид так называемой презумпции невиновности, концепта, согласно которому обвиняемый считается невиновным до тех пор, пока его вина не будет доказана в суде.
Если нулевая гипотеза заключается в том, что два объекта равны в своих свойствах, а вы пытаетесь доказать, что один из них все же лучше (например, A лучше B), вам нужно отказаться от нулевой гипотезы в пользу альтернативной. Например, вы сравниваете между собой тот или иной инструмент для оптимизации конверсии. В нулевой гипотезе они оба оказывают на объект воздействия одинаковый эффект (или не оказывают никакого эффекта). В альтернативной — эффект от одного из них лучше.
Ваша альтернативная гипотеза может содержать числовое значение, например, B - A > 20%. В таком случае нулевая гипотеза и альтернативная могут принять следующий вид:

Другое название для альтернативной гипотезы — это исследовательская гипотеза, поскольку исследователь всегда заинтересован в доказательстве именно этой гипотезы.
Статистическая значимость и значение «p»
Вновь вернемся к Рональду Фишеру и его понятию о статистической значимости.
Теперь, когда у вас есть нулевая гипотеза и альтернативная, как вы можете доказать одно и опровергнуть другое?
Поскольку статистические данные по самой своей природе предполагают изучение определенной совокупности (выборки), вы никогда не можете быть на 100% уверены в полученных результатах. Наглядный пример: зачастую результаты выборов расходятся с результатами предварительных опросов и даже эксит-пулов.
Доктор Фишер хотел создать определитель (dividing line), который позволял бы понять, удался ли ваш эксперимент или нет. Так и появился индекс достоверности. Достоверность — это тот уровень, который мы принимаем для того, чтобы сказать, что мы считаем «значимым», а что нет. Если «p», индекс достоверности, равен 0,05 или меньше, то результаты достоверны.
Не волнуйтесь, в действительности все не так запутано, как кажется.

Распределение вероятностей Гаусса. По краям — менее вероятные значения переменной, в центре — наиболее вероятные. P-показатель (закрашенная зеленым область) — это вероятность наблюдаемого результата, возникающего случайно.
Нормальное распределение вероятностей (распределение Гаусса) — это представление всех возможных значений некой переменной на графике (на рисунке выше) и их частот. Если вы проведете свое исследование правильно, а затем расположите все полученные ответы на графике, вы получите именно такое распределение. Согласно нормальному распределению, вы получите большой процент похожих ответов, а оставшиеся варианты разместятся по краям графика (так называемые «хвосты»). Такое распределение величин часто встречается в природе, поэтому оно и носит название «нормального».
Используя уравнение на основе вашей выборки и результатов теста, вы можете вычислить то, что называется «тестовой статистикой», которая укажет, насколько отклонились полученные результаты. Она также подскажет, насколько близко вы к тому, чтобы нулевая гипотеза оказалась верной.
Чтобы не забивать свою голову, используйте онлайн-калькуляторы для вычисления статистической значимости:

Один из примеров таких калькуляторов
Буква «p» обозначает вероятность того, что нулевая гипотеза верна. Если число будет небольшим, это укажет на разницу между тестовыми группами, тогда как нулевая гипотеза будет заключаться в том, что они одинаковы. Графически это будет выглядеть так, что ваша тестовая статистика окажется ближе к одному из хвостов вашего колоколообразного распределения.
Доктор Фишер решил установить порог достоверности результатов на уровне p ≤ 0,05. Однако и это утверждение спорное, поскольку приводит к двум затруднениям:
1. Во-первых, тот факт, что вы доказали несостоятельность нулевой гипотезы, не означает, что вы доказали альтернативную гипотезу. Вся эта значимость всего лишь значит, что вы не можете доказать ни A, ни B.
2. Во-вторых, если p-показатель будет равен 0,049, это будет означать, что вероятность нулевой гипотезы составит 4,9%. Это может означать, что в одно и то же время результаты ваших тестов могут быть одновременно и достоверными, и ошибочными.
Вы можете использовать p-показатель, а можете отказаться от него, но тогда вам будет необходимо в каждом отдельном случае высчитывать вероятность осуществления нулевой гипотезы и решать, достаточно ли она большая, чтобы не вносить тех изменений, которые вы планировали и тестировали.
Наиболее распространенный сценарий проведения статистического теста сегодня — это установление порога значимости p ≤ 0,05 до запуска самого теста. Только не забудьте внимательно изучить p-значение при проверке результатов.
Ошибки 1 и 2
Прошло так много времени, что ошибки, которые могут возникнуть при использовании показателя статистической значимости, даже получили собственные имена.
Ошибка 1 (Type 1 Errors)
Как было упомянуто выше, p-значение, равное 0,05, означает: вероятность того, что нулевая гипотеза окажется верной, равняется 5%. Если вы откажетесь от нее, вы совершите ошибку под номером 1. Результаты говорят, что ваш новый веб-сайт повысил показатели конверсии, но существует 5%-ная вероятность, что это не так.
Ошибка 2 (Type 2 Errors)
Эта ошибка является противоположной ошибке 1: вы принимаете нулевую гипотезу, в то время как она является ложной. К примеру, результаты тестов говорят вам, что внесенные изменения в сайт не принесли никаких улучшений, тогда как изменения были. Как итог: вы упускаете возможность повысить свои показатели.
Такая ошибка распространена в тестах с недостаточным размером выборки, поэтому помните: чем больше выборка, тем достовернее результат.
Заключение
Пожалуй, ни один термин среди исследователей не пользуется такой популярностью, как статистическая значимость. Когда результаты тестов не признаются статистически значимыми, последствия бывают самые разные: от роста показателя конверсии до краха компании.
И раз уж маркетологи используют этот термин при оптимизации своих ресурсов, нужно знать, что же он означает на самом деле. Условия проведения тестов могут меняться, но размер выборки и критерий успеха важен всегда. Помните об этом.
Совсем недавно Владимир Давыдов написал пост в facebook про A/B- или MVT-тестирование, который вызвал массу вопросов.
Обычно проведение A/B- или MVT-тестирований на сайтах — вещь очень сложная. Хотя «посадочникам» кажется, что это элементарно, ведь «этсамое, есть же специальные программы, гыг».
Если вы решили тестировать веб-содержимое, помните:
1. Для начала нужно изолировать равнозначную, равновеликую, равнокачественную аудиторию. Провести A/A-тесты. Подавляющее большинство тестов, которые проводят агентства на потоке или неопытные интернет-маркетологи, не верны. Именно по той причине, что тестируется содержимое на разных аудиториях.
2. Проводите десятки или лучше сотни тестов в течение нескольких месяцев. Тестировать недельку 2-3 варианта странички не стоит.
3. Помните, что тестировать можно и в формате MVT (то есть много вариантов), а не только A и B.
4. Статистически проанализируйте массив данных с результатами тестов (в Excel абсолютно окей, можно ещё SPSS использовать). Находятся ли результаты в рамках погрешности, насколько сильно отклоняются и как зависят от времени. Если, например, в первом пункте A/A-теста вы получили сильные отклонения одного варианта от другого — это провал, и дальше тестировать нельзя.
5. Не надо тестировать все подряд. Это не развлечение (только если вам реально больше нечего делать). Тестировать имеет смысл только то, что с точки зрения маркетингового и бизнес-анализа способно привести к заметным результатам. А также то, результат от чего можно реально измерить. Например, вы решили увеличить размер шрифта на сайте, потестировали пару недель страницу с большим шрифтом — продажи выросли. О чем это говорит? Вот и мне ни о чем (см. предыдущие пункты).
6. Тестировать нужно пути целиком. То есть недостаточно взять и протестировать страницу покупки (или какого-то действия на сайте) — нужно тестировать и те страницы и шаги, которые подводят к этой финальной конверсионной странице.
В комментариях был задан вопрос:
«Как устанавливать победителя? Вот протестировали мы заголовок на странице, продающей «в лоб». Какая разница в конверсии должна быть между А и B, чтобы признать победителя?»
Ответ Владимира:
Во-первых, нужно проводить длительные изолированные эксперименты (базовое правило любой статистической оценки). Во-вторых, все неминуемо сводится к статистике и математике (поэтому и рекомендую excel и spss или аналоги бесплатные) Нам нужно посчитать доверительную вероятность того, что разница в значениях чего-то значит. Есть хорошая статья (одна из многих). Там берут транзакции из GA по проводимым Optimizely-тестам https://www.distilled.net/uploads/ga_transactions.png , сравнивают транзакции (покупки) обычным колокольным распределением и смотрят, попадает ли среднее значение в рамки доверительного интервала погрешности https://www.distilled.net/uploads/t-test_tool.png
Хотите получить предложение от нас?
Начать сотрудничествоРоль статистической значимости при повышении конверсии: 6 вещей, которые нужно знать
1. Именно то, что это значит

«Изменение позволило достичь повышения конверсии на 20% с доверительной вероятностью 90%». К сожалению, это утверждение вовсе не равнозначно другому, очень похожему: «Шансы повысить конверсию на 20% составляют 90%». Так о чем же речь на самом деле?
20% — это рост, который мы зафиксировали по результатам тестов на одном из образцов. Если бы мы начали фантазировать и строить догадки, мы бы могли предположить, что этот рост может сохраняться постоянно – если мы будем продолжать тестирование до бесконечности. Но это никак не означает, что с вероятностью 90% мы получим двадцатипроцентный рост конверсии или рост «как минимум» в 20%, или «приблизительно» в 20%.
90% — это вероятность проявления каких бы то ни было изменений в конверсии. Другими словами, если бы мы проводили десять А/B-тестов, чтобы получить этот результат, и решили бы проводить все десять до бесконечности, то один из них (так как вероятность изменений 90%, то 10% остаётся на неизменный исход), вероятно, закончился бы приближением результата «после теста» к первоначальной конверсии – то есть, без изменений. Из остающихся девяти тестов некоторые могли бы показать рост, составляющий куда меньше 20%. В других результат мог бы превысить эту планку.
Если неверно интерпретировать эти данные, мы сильно рискуем, «выкатывая» тест. Легко обрадоваться, когда тест показывает высокие показатели роста конверсии с доверительной вероятностью в 95%, но мудрее было бы не ожидать слишком многого, пока тест не доведен до логического завершения.
2. Когда использовать
Самые очевидные кандидаты – сплит-тесты «А/В», но они далеко не единственные. Можно также проводить тестирование статистически значимой разницы между сегментами (например, посещениями через обычный и через оплаченный поиск) или временными промежутками (например, апрелем 2013 года и апрелем 2014 года).
Однако стоит заметить, что эта корреляция не подразумевает причинно-следственную связь. Проводя сплит-тесты, мы знаем, что можем приписать любые изменения результатов тем элементам, которыми различаются страницы – ведь особое внимание уделяется тому, чтобы в остальном страницы были совершенно идентичны. Если вы сравниваете такие группы, как посетители, пришедшие из обычного и платного поиска, сработать могут любые другие факторы – к примеру, из обычного поиска может быть много посещений по ночам, а конверсия среди ночных посетителей весьма высока. Тесты на значимость помогают установить, есть ли у изменений причина, но они не смогут сказать, в чем именно она заключается.
3. Как тестировать изменения показателей конверсии, отказов и выходов (exit rate)
Когда мы смотрим на «показатели», на самом деле мы видим усредненные значения двоичных переменных – кто-то либо выполнил целевые действия, либо нет. Если у нас есть выборка в 10 человек с показателем конверсии в 40%, на самом деле мы смотрим на подобную таблицу:

Эта таблица потребуется нам вкупе со средним показателем, чтобы вычислить среднее отклонение – ключевой компонент статистической значимости. Однако тот факт, что каждое значение в таблице является либо нулем, либо единицей, облегчает нам задачу – мы можем обойтись без необходимости копировать огромный список цифр, воспользовавшись калькулятором для подсчета доверительной вероятности А/B-тестов, и отталкиваясь от знания среднего показателя и размеров выборки. Это инструмент от KissMetrics .
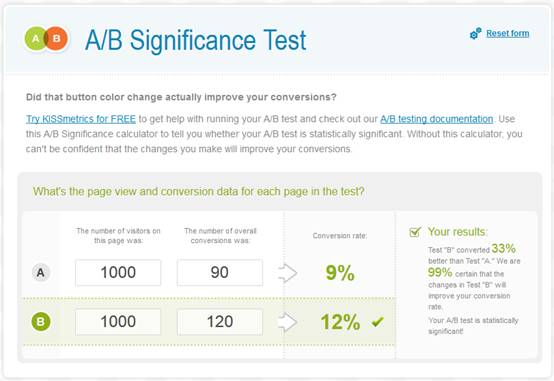
(Важно! Этот инструмент в расчетах принимает во внимание только одну сторону “колокола” распределения вероятности . Чтобы использовать обе стороны и перевести результат в двустороннюю значимость, нужно удвоить дистанцию от 100% — например, односторонние 95% становятся двусторонними 90%).
Несмотря на то, что в описании значится «инструмент тестирования достоверности А/B-тестов», его также можно использовать для любого другого сравнения показателей – просто замените конверсию на показатель отказов или выходов. Кроме того, его можно использовать и для сравнения сегментов или промежутков времени – вычисления будут те же.
Также, он хорошо подходит для мультивариантных тестирований (MVT) – просто сравнивайте с оригиналом каждое изменение по отдельности.
4. Как тестировать изменения среднего чека
Чтобы тестировать средние значение недвоичных переменных, нам потребуется полный набор данных, так что здесь все немного сложнее. Например, мы хотим установить, есть ли значимые различия средней суммы заказа для сплит-теста А/В – этот момент часто опускают при оптимизации конверсии, хотя для бизнес-показателей он так же важен, как и сама конверсия.
Первое, что нам нужно, это получить из Google Analytics полный список транзакций для каждого варианта теста — для А и B (было, стало). Простейший способ это сделать – создать пользовательские сегменты, базирующиеся на переменных (custom variables) для вашего сплит-теста, а затем экспортировать отчет по транзакциям в таблицу Excel. Убедитесь, что туда войдут все транзакции, а не только 10 строк, указанных по умолчанию.

Когда у вас есть два списка транзакций, их можно скопировать в подобный инструмент :
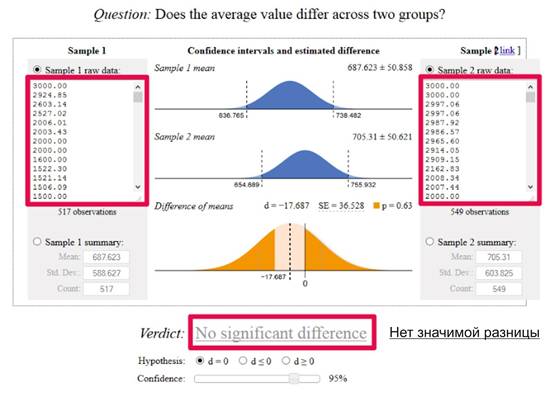
В вышеозначенном случае у нас нет доверительной вероятности на выбранном уровне в 95%. На самом деле, если мы взглянем на показатель «p» над нижним графиком, составляющий 0,63, станет ясно, что у нас нет даже 50% значимости – существует вероятность в 63%, что разница между показателями страниц является чистой случайностью.
5. Как предугадать необходимую продолжительность сплит-теста А/В
На Evanmiller.org есть еще один удобный инструмент для оптимизации конверсии – калькулятор размера выборки .
Этот инструмент позволяет дать ответ на вопрос «Сколько потребуется времени, чтобы получить достоверные результаты теста?», и этот ответ не стоит пытаться угадать.

Стоит отметить несколько моментов. Во-первых, у инструмента есть переключатель «абсолютное/относительное» — если вы хотите выяснить разницу между базовым показателем конверсии в 5% и переменным показателем конверсии в 6%, он составит 1% в абсолютном выражении (6-5=1) или 20% в относительном выражении (6/5=1,2). Во-вторых, внизу страницы есть два «бегунка». Нижний отвечает за требуемый уровень значимости – если вашей целью является получение значимости в 95%, то бегунок нужно выставить на 5%. Верхний бегунок показывает вероятность того, что количество требуемых посещений страницы окажется достаточным – к примеру, если вы хотите узнать количество визитов, необходимых для достижения восьмидесяти процентного шанса обнаружить значимость в 95%, выставьте верхний бегунок на 80%, а нижний на 5%.
6. Чего не нужно делать
Есть несколько простых путей выявить непригодность сплит-теста, которые, однако, далеко не всегда очевидны с первого взгляда:
А) Сплит-тестирование недвоичных порядковых значений
Например, ваша цель – выяснить, имеет ли место значимая разница вероятностей того, что посетители из групп «первоначальная» и «после изменений» купят определенные продукты. Вы помечаете три продукта «1», «2» и «3», а затем вводите эти значения в поля теста на значимость. К сожалению, этот подход не сработает – продукт 2 не является средним значением продуктов 1 и 3.
Б) Настройки распределения трафика

В начале теста вы решаете не рисковать и выставляете распределение трафика 90/10. Спустя какое-то время вы видите, что изменение не привело к заметным изменениям в конверсии, и перемещаете бегунок к значению 50/50. Но возвращающиеся посетители по-прежнему принадлежат к своей первоначальной группе, поэтому вы оказываетесь в ситуации, где версия «до изменений» отличается большей долей вернувшихся посетителей, показывающих высокую вероятность конверсии. Все очень быстро усложняется, и единственный простой путь получить данные, на которые можно положиться, заключается в том, чтобы по отдельности рассматривать новых и вернувшихся посетителей. Однако в этом случае на получение значимых результатов уйдет больше времени. И даже если обе подгруппы покажут значимые результаты, что, если одна из них на самом деле генерирует больше вернувшихся посетителей? В общем, не нужно этого делать и менять в течение теста распределение трафика.
В) Планирование
Выглядит очевидным, но не стоит сравнивать данные, собранные в одно и то же время дня, с данными, собранными в течение суток или в другое время дня. Если вы хотите провести тест в отношении конкретного времени дня, у вас есть два варианта.
1. Обрабатывать запросы посетителей, как и всегда, в течение дня, но показывать им оригинальную версию страницы в то время дня, в котором вы не заинтересованы.
2. Сравнивать яблоки с яблоками – если вы рассматриваете только данные по изменениям за первую половину дня, сравнивайте их с первоначальными данными за первую половину дня.
Надеюсь, что-то из вышеизложенного окажется полезным для оптимизации вашей конверсии . Если у вас есть свои ноу-хау, пожалуйста, излагайте их в комментариях.
 Тире в сложном предложении
Тире в сложном предложении Нападение на нацгвардию в Чечне: “китайский расстрел” или атака ИГ?
Нападение на нацгвардию в Чечне: “китайский расстрел” или атака ИГ? Химические реакции алюминия
Химические реакции алюминия