Построение уравнения тренда. Параметры уравнения тренда. Уравнение линии тренда в Excel
Статистические расчеты содержания влаги
2. Уравнение тренда на основе линейной зависимости.
2.1. Основные элементы временного ряда.
Можно построить эконометрическую модель, используя два типа исходных данных:
Данные, характеризующие совокупность различных объектов в определённый момент времени.
Данные, характеризующие один объект за ряд последовательных моментов времени.
Модели, построенные по данным первого типа, называются пространственными. Модели, построенные на основе второго типа данных, называются временными рядами.
Временной ряд - это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
Факторы, формирующие тенденцию ряда.
Факторы, формирующие циклические колебания ряда.
Случайные факторы.
При различных сочетаниях в изучаемом явлении или процессе этих факторов зависимость уровней ряда от времени может принимать различные формы.
Во-первых, большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Очевидно, что эти факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис. 1. показан временной ряд, содержащий возрастающую тенденцию.
Во-вторых, изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года. При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка, а также с фазой бизнес цикла, в которой находится экономика страны. На рис. 2. представлен временной ряд, содержащий только сезонную компоненту.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень базируется как сумма среднего уровня ряда и некоторой случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведён на рис. 3.
Очевидно, что реальные данные не следуют полностью из каких-либо описанных моделей. Чаще всего они содержат все три компоненты. Каждый их уровень формируется под воздействием тенденции, сезонных колебаний и случайной компоненты.
В большинстве случаев фактический уровень временного ряда можно представить как сумму или произведение трендовой, циклической и случайной компонент. Модель, в которой временной ряд представлен как сумма перечисленных компонент, называется аддитивной моделью. Модель, в которой временной ряд представлен как произведение перечисленных компонент, называется мультипликативной моделью.
2.2. Автокорреляция уровней временного ряда.
При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Корреляционную зависимость между последовательными уровнями временного ряда называют автокорреляцией. Количественно её можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми во времени.
Одна из рабочих формул для расчёта коэффициента корреляции имеет вид:
r xy = (x j - x ) * (y j - y ) .
(x j -x) 2 * (y j -y) 2
В качестве переменной x мы рассмотрим ряд y 2 , y 3 , ... y t ; в качестве переменной y рассмотрим ряд y 1 , y 2 , ... y t -1 . Тогда данная формула примет вид:
r 1 = (y t - y 1 ) * (y t-1 - y 2 ) ; где y 1 = y t ; y 2 = y t-1 .
(y t -y 1) 2 * (y t-1 -y 2) 2 n - 1 n - 1
Эту величину называют коэффициентом автокорреляции уровней ряда первого порядка. Число периодов, по которым рассчитывается коэффициент автокорреляции, называют лагом. С увеличением лага число пар значений, по которым рассчитывается коэффициент автокорреляции, уменьшается.
Свойства коэффициента автокорреляции:
Во-первых, он строится по аналогии с линейным коэффициентом корреляции и таким образом характеризует тесноту только линейной связи текущего и предыдущего уровней ряда. Поэтому по коэффициенту автокорреляции можно судить о наличии линейной тенденции.
Во-вторых, по знаку коэффициента автокорреляции нельзя делать вывод о возрастающей или убывающей тенденции в уровнях ряда.
Последовательность коэффициентов автокорреляции уровней первого, второго, и т.д. порядков называют автокорреляционной функцией временного ряда. График зависимости её значений от величины лага называется коррелограммой. Анализ автокорреляционной функции и коррелограммы позволяет определить лаг, при котором автокорреляция наиболее высокая, а, следовательно, и лаг, при котором связь между текущим и предыдущим уровнями ряда наиболее тесная, т.е. при помощи анализа автокорреляционной функции и коррелограммы можно выявить структуру ряда.
Если наиболее высоким оказался коэффициент автокорреляции первого порядка, исследуемый ряд содержит только тенденцию. Если наиболее высоким оказался коэффициент автокорреляции порядка t, ряд содержит циклические колебания с периодичностью в t моментов времени. Если ни один из коэффициентов автокорреляции не является значимым, можно сделать вывод: либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию, для выявления которой нужно провести дополнительный анализ.
2.3. Моделирование тенденции временного ряда.
Одним из наиболее распространённых способов моделирования тенденции временного ряда является построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда. Этот способ называют аналитическим выравниванием временного ряда.
Т.к. зависимость от времени может принимать разные формы, для её формализации можно использовать различные виды функции. Для построения трендов чаще всего применяются следующие функции:
Линейный тренд: y t = a + b*t ;
Гипербола:y t = a + b/t ;
Экспоненциальный тренд: y t = e a + b * t ;
Тренд в форме степенной функции: y t = a*t ;
Парабола: y t = a + b 1 *t + b 2 *t 2 + ... + b k *t k ;
Параметры каждого из этих трендов можно определить методом наименьших квадратов, используя в качестве независимой переменной время t = 1, 2, ... ,n , а в качестве зависимой переменной - фактические уровни временного ряда y t . Для нелинейных трендов предварительно проводят стандартную процедуру их линеаризации.
Существует несколько способов определения типа тенденции. К числу наиболее распространённых способов относятся качественный анализ изучаемого процесса, построение и визуальный анализ графика зависимости уровней ряда от времени, расчёт некоторых основных показателей динамики. В этих же целях можно использовать и коэффициенты автокорреляции уровней ряда. Тип тенденции можно определить путем сравнения коэффициентов автокорреляция первого порядка, рассчитанных по исходным и преобразованным уровням ряда. Если временной ряд имеет линейную тенденцию, то его соседние уровни y t и y t -1 тесно коррелируют. В этом случае коэффициент автокорреляции первого порядка уровней исходного ряда должен быть высоким. Если временной ряд содержит не6линейную тенденцию, например, в форме экспоненты, то коэффициент автокорреляции первого порядка по логарифмам уровней исходного ряда будет выше, чем соответствующий коэффициент, рассчитанный по уровням ряда. Чем сильнее выражена нелинейная тенденция в изучаемом временном ряде, тем в большей степени будут различаться значения указанных коэффициентов.
Выбор наилучшего уравнения в случае, если ряд содержит нелинейную тенденцию, можно осуществить путем перебора основных форм тренда, расчета по каждому уравнению скорректированного коэффициента детерминации R и выбора уравнения тренда с максимальным значением скорректированного коэффициента детерминации.
Высокие значения коэффициентов автокорреляции первого, второго и третьего порядков свидетельствуют о том, что ряд содержит тенденцию. Приблизительно равные значения коэффициентов автокорреляции по уровням этого ряда и по логарифмам уровней позволяют сделать следующий вывод: если ряд содержит нелинейную тенденцию, то она выражена в неявной форме. Поэтому для моделирования его тенденции в равной мере целесообразно использовать и линейную, и нелинейную функции, например степенной или экспоненциальный тренд. Для выявления наилучшего уравнения тренда необходимо определить параметры основных видов трендов.
Наиболее простую экономическую интерпретацию имеют параметры линейного и экспоненциального трендов. Параметры линейного тренда:
a - начальный уровень временного ряда в момент времени t = 0;
b - средний за период абсолютный прирост уровней ряда.
Расчётные по линейному тренду значения уровней временного ряда определяются двумя способами. Во-первых, можно последовательно подставлять в найденное уравнение тренда значения t = 1, 2, ..., n. Во-вторых, в соответствии с интерпретацией параметров линейного тренда каждый последующий уровень ряда есть сумма предыдущего уровня и среднего цепного абсолютного прироста.
Задача №1
Десять человек различного возраста имеют следующие параметры:
1. Определить результативный признак.
Рассчитаем зависимость роста от возраста:
Фактор (X): возраст.
Результативный признак (Y): рост.
a*x + b*x 2 = x*y
10*a + 248*b = 1812
248*a + 6492*b = 45023
a = 1812 - 248*b => 1812 - 248*b *248 + 6492*b = 45023
r = x*y - ( x* y)/n = 45023 - (248*1812)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (6492 - 248 2 /10)*(328444 - 1812 2 /10)
r = 0.44 - прямая умеренная связь
r 2 = 0.19 - рост на 19% зависит от возраста
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.19 * (10 - 2) = 1.78
F табл = 5.32
F cp < F табл =>
Рассчитаем зависимость веса от возраста:
Фактор (X): возраст.
Определим параметры линейной функции с помощью системы уравнений:
a*x + b*x 2 = x*y
10*a + 248*b = 753
248*a + 6492*b = 18856
a = 753 - 248*b => 1812 - 248*b *248 + 6492*b = 18856
r = x*y - ( x* y)/n = 18856 - (248*753)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (6492 - 248 2 /10)*(56967 - 753 2 /10)
r = 0.6 - заметная прямая связь
r 2 = 0.36 - вес на 36% зависит от возраста
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.36 * (10 - 2) = 4.5
F табл = 5.32
F cp < F табл => нулевая гипотеза подтвердилась, уравнение статистически незначимо.
Рассчитаем зависимость веса от роста:
Фактор (X): рост.
Результативный признак (Y): вес.
Определим параметры линейной функции с помощью системы уравнений:
a*x + b*x 2 = x*y
10*a + 1812*b = 753
1812*a + 328444*b = 136562
a = 753 - 1812*b => 753 - 1812*b *1812 + 328444*b = 136562
r = x*y - ( x* y)/n = 136562 - (1812*753)/10 =>
(x 2 - (x) 2 /n)*(y 2 - (y) 2 /n) (328444 - 1812 2 /10)*(56967 - 753 2 /10)
r = 0.69 - заметная прямая связь
r 2 = 0.47 - вес на 47% зависит от роста
x = 1812/10 = 181.2
Тест Фишера:
F cp = r 2 * (n - 2)
F cp = 0.47 * (10 - 2) = 7.1
F табл = 5.32
F cp > F табл => нулевая гипотеза не подтвердилась, уравнение имеет экономический смысл.
Тест Стьюдента:
Рассчитаем случайные ошибки:
.
m a = (y - y x ) 2 * x 2 .
n - 2 n*(x -x) 2
m b = (y - y x ) 2 / (n - 2)
m r = 1 - r 2
m a = 138.19 * 328444 = 72
m b = 138.19 / (10 - 2) = 1
m r = 1 - 0.47 = 0.26
t a = a/m a = 120/72 = 1.67
t b = b/m b = 1.08/1 = 1.08
t r = r/m r = 0.69/0.26 = 2.65
t табл = 2.3
Для расчёта доверительного интервала рассчитаем предельную ошибку:
a = t табл - t a = 2.3 - 1.67 = 0.63
b = t табл - t b = 2.3 - 1.08 = 1.22
r = t табл - t r = 2.3 - 2.65 = -0.35
Рассчитаем доверительные интервалы:
a = a a = -121.03 119.77
b = b b = -0.14 2.3
r = r r = 0.34 1.04
Задача №2
При контрольной выборочной проверке процента влажности почвы фермерских хозяйств региона получены следующие данные:
1. С вероятностью 0.95 и 0.99 установить предел, в котором находится средний процент содержания влаги.
2. Сделать выводы.
Генеральная средняя: x = x = 31.1 = 3.8875
Генеральная дисперсия: 2 = (x - x ) 2 = 1.8875 = 0.1261
n 8 .
Средняя квадратическая стандартная ошибка: x = 2 = 0.1261 = 0.126
Предельная ошибка выборки: x = t* x
Из таблицы значений t-критерия Стьюдента:
Для вероятности 0.95, предельная ошибка выборки:
x = 2.4469*0.126 = 0.308
Для вероятности 0.99, предельная ошибка выборки:
x = 3.7074*0.126 = 0.467
Доверительные интервалы:
Предел среднего процента содержания влаги с вероятностью 0.95:
Верхний центральный показатель некоторой линейной системы
Пусть дана система (2) и - ее решение. Рассмотрим семейство функций, Определение 5 : Функция R (t) называется верхней для системы (2), если она ограничена, измерима и осуществляет оценку, Где - норма матрицы Коши линейной системы...
Исходя из определения производной сформулируем следующее правило нахождения производной функции в точке: Чтобы вычислить производную функции f(x) в точке x0 нужно: 1) Найти f(x) - f(x0); 2) составить разностное отношение; 3) вычислить предел...
Дифференциальное исчисление
Исходя из определения производной...
Инвариантные подгруппы бипримарных групп
В заметке (1) исправлена ошибка, допущенная Бернсайдом в работе (2). А именно в (3) доказано, что группа порядка, где и - различные простые числа и, либо обладает характеристической -подгруппой порядка...
Использование современной компьютерной техники и программного обеспечения для решения прикладной задачи из инженерно-буровой практики
Зная значения коэффициентов а0, а1 и а2 можно найти значений y` по формуле, в нашем случае. Различие между экспериментальными и теоретическими данными невелико. Полученные данные позволяет нам найти зависимость, 5...
Линейная сложность циклотомических последовательностей
Пусть последовательность четвертого порядка, то есть, тогда, согласно лемме 1.1, она формируется по правилу: (2.1) Заметим, что правило (2.1) задает последовательность только тогда, когда...
Математическая модель цифрового устройства игры "Крестики-нолики" с человеком
Игровое поле игры в крестики-нолики может быть представлено в виде сетки, состоящей из строк и столбцов. Каждый элемент сетки может находиться в трех состояниях: пустое (начальное), отмечено крестиком, отмечено ноликом...
Методы отсечения
Среди совокупности п неделимых предметов, каждый i-и (i=1,2,…, п) из которых обладает по i-й характеристике показателем и полезностью найти такой набор, который позволяет максимизировать эффективность использования ресурсов величины...
Приближенное решение алгебраических и трансцендентных уравнений. Метод Ньютона
Информация о предыдущих приближениях корня используется для нахождения последующих приближений не только в методе касательных. В качестве примера другого такого метода мы приведём метод...
Статистические расчеты содержания влаги
Практические задачи: 1. Десять человек различного возраста имеют следующие параметры: Возраст, лет 18 20 21 22 22 24 25 26 31 39 Рост, см 174 183 182 180 178 179 185 185 184 182 Вес, кг 65 73 69 74 77 75 78 84 79 79 1...
При использовании полиномов разных степеней оценка параметров уравнения тренда производится методом наименьших квадратов (МНК) точно так же, как оценки параметров уравнения регрессии на основе пространственных данных. В качестве зависимой переменной рассматриваются уровни динамического ряда, а в качестве независимой переменной – фактор времени t, который обычно выражается рядом натуральных чисел 1, 2, ..., п.
Оценка параметров нелинейных функций проводится МНК после линеаризации, т.е. приведения их к линейному виду. Рассмотрим применение МНК для некоторых нелинейных функций, которые не излагались подробно в главе, посвященной регрессии.
Для оценки параметров показательной кривой у = ab 1 или экспоненты у = е а+ы (либо у = ае ы) путем логарифмирования функции приводятся к линейному виду lny = ln a + t ln b или экспоненты: lny = a + bt. Далее строится система нормальных уравнений
Пример 5.1
Число зарегистрированных ДТП (на 100 000 человек населения) по Новгородской области за 2000–2008 гг. характеризуется данными:
Исходя из графика была выбрана показательная кривая / Для построения системы нормальных уравнений были рассчитаны вспомогательные величины

Система нормальных уравнений составила ![]()
Решая ее, получим значения
![]()
Соответственно имеем экспоненту или показательную кривую
За период с 2000 по 2008 г. число дорожно-транспортных происшествий возрастало в среднем ежегодно на 13,5%. Экспонента достаточно хорошо описывает тенденцию исходного временного ряда: коэффициент детерминации составил 0,9202. Следовательно, данный тренд объясняет 92% колеблемости уровней ряда и лишь 8% ее связаны со случайными факторами.
Некоторую специфику имеет оценка параметров кривых с насыщением: модификационной экспоненты, логистической кривой, кривой Гомперца, гиперболы вида По этим функциям должна быть сначала определена асимптота. Если она может быть задана исследователем на основе анализа временного ряда, то другие параметры могут быть оценены по МНК. В этих случаях данные функции приводятся к линейному виду. Рассмотрим оценку параметров этих кривых на отдельных примерах, начиная с модифицированной экспоненты.
Пример 5.2
Уровень механизации труда (в %) характеризуется динамическим рядом (табл. 5.2)
Таблица 5.2. Расчет параметров модифицированной экспоненты у = с ab" t
|
У = с-у |
|||||||
Так как уровень механизации труда не может превышать 100%, то имеется объективно заданная верхняя асимптота с = 100. Для оценки параметров а и b приведем рассматриваемую функцию к линейному виду ; обозначим (с-у) через Y и прологарифмируем:
![]()
Для нашего примера, исходя из данных итоговой строки табл. 3, имеем систему уравнений
![]()
Решив ее, получим ln а = 3,06311; ln b = -0,19744. Соответственно потенцируя, получим: т.е. уравнение .
Если перейти от Y к исходным уровням ряда, уравнение модифицированной экспоненты составит , где параметр показывает средний коэффициент снижения уровня использования ручного труда за 1998–2005 гг. Расчетные значения у, т.е. могут быть найдены путем подстановки в уравнение 0,8208" соответствующих значений t. Либо на основе уравнения In 7= 3,06311 – 0,19744 г при компьютерной обработке определяется In У и далее 100 – е 1пу. Так, при t = 8 In Y = = 1,48363 и 100 – e1"48363 = 100 – 4,40892 = 95,59108 = 95,6 (см. последнюю графу таблицы). Ввиду некоторой смещенности оценок (так как МНК применяется к логарифмам) Ху, Ф Ху, хотя в примере эти величины достаточно близки друг другу.
Если асимптота с не задана, то оценка параметров модифицированной экспоненты усложняется. В этих случаях могут использоваться разные методы оценивания: метод трех сумм, метод трех точек , с помощью регрессии , метод Брианта . Рассмотрим применение метода регрессии для оценки параметров модифицированной экспоненты вида у = с – ab c.
Пример 5.3
В таблице представлены данные о расходах предприятия на рекламу за 10 мес. года.
Таблица 5.3. Данные о расходах предприятия на рекламу за 10 мес. года (в тыс. руб.)
Найдем по нашему ряду цепные абсолютные приростыг и представим их через параметры нашей функции, T.e.z = c-ab" – с + ab"~ l = ab" 1 (1 – b). Известно, что для модифицированной экспоненты логарифм абсолютных приростов линейно зависит от фактора времени t. Следовательно, можно записать, что lnz = Ιηα + (f – 1) lnb + ln(l – b). Обозначим Ιηα + ln(l – b) через d. Тогда lnz = d + (t- 1) lnb, т.е. линейное в логарифмах уравнение. Применяя МНК, получим оценки параметров d, lnb, а соответственно и параметра Ь. В рассматриваемом примере на основании граф табл. 5.3 lnz и (t – 1) было найдено уравнение регрессии: lnz = 4,519641 – 0,20882 (t – 1). Исходя из него получаем lnb = -0,20882; b = 0,811538. 4,519641 = In a + In (1 – b) = In [α (1 – b)]. Тогда α (1 – b) = e4,519641, откуда параметра =91,80264/(1-0,811538) = 487,1145.
Далее можно найти оценку параметра с как среднее значение из величин с = у + ab", найденных для каждого месяца (см. последнюю графу табл. 5.3). Предельная величина расходов на рекламу составит 516,4 тыс. руб. Искомое уравнение тренда примет вид
Рассмотренный метод применим, если абсолютные приросты – величины положительные. Если же некоторые приросты окажутся меньше нуля, то нужно проводить сглаживание уровней временного ряда методом скользящей средней.
Для логистической кривой Перла – Рида аналогично параметры а и b могут быть найдены МНК, если асимптота с задана. Тогда данная функция преобразовывается в линейную из логарифмов ![]() обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
обозначим через Y
и прологарифмируем, т.е. ). Далее параметры а и b
определяются МНК, как и в примере по табл. 5.3.
Для логистической кривой вида параметры а и b могут быть оценены МНК, если асимптота с задана, так как в этом случае функция линеаризуема: ; обозначим через Y величину и прологарифмируем: Далее, применяя МНК, оцениваем параметры а и b.
При практических расчетах значение верхней асимптоты логистической кривой может быть определено исходя из существа развития явления, различного рода ограничений для его роста (нормативы потребления, законодательные акты), а также графически.
Если верхняя асимптота не задана, то для оценки параметров могут использоваться разные методы: Фишера, Юла, Родса, Нейра и др. Сравнительная оценка и обзор этих методов изложены в работе E. М. Четыркина .
Покажем на примере расчет параметров логистической кривой по методу Фишера.
Пример 5.4
Производство продукции характеризуется данными, представленными в табл. 5.4.
Таблица 5.4. Расчет параметров логистической кривой
Метод Фишера основан на определении производной для логистической кривой. Дифференцируя данную функцию по t, получим уравнение
Обозначим темп прироста логистической кривой через . Тогда , т.е. для z,
имеем линейную функцию с параметрами а
и . Чтобы найти решение, необходимо оценить z,. Предполагая, что интервалы между уровнями в ряду динамики равны, Фишер предложил приближенно оценивать в виде уравнения , где п
- 1. Для нашего примера значения z, представлены в графе 3 табл. 5.4. Далее применяем МНК к уравнению: , т.е. строим регрессию z(оту(, беря данные от t = 2 до f = 8. Уравнение регрессии запишется в виде Исходя из него находим параметры а и с для логистической кривой. Параметр а =
0,806. Данное уравнение статистически значимо: F-критерий равен 689,6; R
2 = 0,996. Соответственно для него значимы и параметры: f-критерий для параметра а
равен 47,2 и для параметра – равен -26,2. Так как , то и ![]() т.е. верхняя асимптота производства продукции составляет 403 ед.
т.е. верхняя асимптота производства продукции составляет 403 ед.
После того, как найдены параметры а и с, находим параметр b . Для этого функциюпредставим как Обозначим через Y выражение в левой части равенства, т.е..-Тогда имеем уравнение Прологарифмируем его:. В этом уравнении свободным членом является In Ь. Его можно определить из первого уравнения системы нормальных уравнений, а именно Для нашего примера имеем уравнение . Соответственно Таким образом, логистическая кривая запишется в виде
![]()
Теоретические значения данной функции представлены в графе 6 табл. 5.4 (найдены путем подстановки соответствующих значений t). Они достаточно близко подходят к исходным данным: коэффициент корреляции между ними равен 0,999; ввиду того, что в расчетах использовались логарифмы. Если предположить, что предельное значение объема производства продукции равно 400 ед., т.е. применить МНК к уравнению , то получим и b = =67,5; параметр а при компьютерной обработке определяется как -а = -0,8. Соответственно уравнение тренда запишется в виде . Результаты двух уравнений достаточно близки.
Параметры кривой Гомперца также могут быть оценены МНК, если асимптота с задана, так как в этом случае данная функция сводима к линейному виду Прологарифмировав ее, получим уравнение .
Вторично прологарифмировав, получим уравнение ![]() , Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
, Обозначив через у*, lgb через В
и Ig(lga) через А, запишем кривую Гомперца в линейном виде , для оценки параметров которой применим МНК.
При практическом применении кривой Гомперца могут возникнуть некоторые сложности по динамическому ряду с повышающейся тенденцией. В этом случае задается верхняя асимптота с и логарифмы При повторном логарифмировании в расчетах используются лишь положительные значения Продемонстрируем возможность оценки параметров кривой Гомперца с верхней асимптотой на примере динамики по предприятию товарных запасов на начало каждого месяца (тыс. долл.).
Таблица 5.5. Расчет параметров кривой Гомперца
Покажем пример подробного расчета параметров уравнения тренда на основе следующих данных (см. таблицу) с использованием калькулятора .
Линейное уравнение тренда имеет вид y = at + b.
1. Находим параметры уравнения методом наименьших квадратов
.
Система уравнений МНК:
a 0 n + a 1 ∑t = ∑y
a 0 ∑t + a 1 ∑t 2 = ∑y t
| t | y | t 2 | y 2 | t y | y(t) | (y-y cp) 2 | (y-y(t)) 2 | (t-t p) 2 | (y-y(t)) : y |
| 1 | 17.4 | 1 | 302.76 | 17.4 | 12.26 | 895.01 | 26.47 | 30.25 | 0.3 |
| 2 | 26.9 | 4 | 723.61 | 53.8 | 18.63 | 416.84 | 68.39 | 20.25 | 0.31 |
| 3 | 23 | 9 | 529 | 69 | 25 | 591.3 | 4.02 | 12.25 | 0.0872 |
| 4 | 23.7 | 16 | 561.69 | 94.8 | 31.38 | 557.75 | 58.98 | 6.25 | 0.32 |
| 5 | 27.2 | 25 | 739.84 | 136 | 37.75 | 404.68 | 111.4 | 2.25 | 0.39 |
| 6 | 34.5 | 36 | 1190.25 | 207 | 44.13 | 164.27 | 92.72 | 0.25 | 0.28 |
| 7 | 50.7 | 49 | 2570.49 | 354.9 | 50.5 | 11.45 | 0.0383 | 0.25 | 0.0039 |
| 8 | 61.4 | 64 | 3769.96 | 491.2 | 56.88 | 198.34 | 20.44 | 2.25 | 0.0736 |
| 9 | 69.3 | 81 | 4802.49 | 623.7 | 63.25 | 483.27 | 36.56 | 6.25 | 0.0872 |
| 10 | 94.4 | 100 | 8911.36 | 944 | 69.63 | 2216.84 | 613.62 | 12.25 | 0.26 |
| 11 | 61.1 | 121 | 3733.21 | 672.1 | 76 | 189.98 | 222.11 | 20.25 | 0.24 |
| 12 | 78.2 | 144 | 6115.24 | 938.4 | 82.38 | 953.78 | 17.46 | 30.25 | 0.0534 |
| 78 | 567.8 | 650 | 33949.9 | 4602.3 | 567.8 | 7083.5 | 1272.21 | 143 | 2.41 |
Для наших данных система уравнений имеет вид:
12a 0 + 78a 1 = 567.8
78a 0 + 650a 1 = 4602.3
Из первого уравнения выражаем а 0 и подставим во второе уравнение
Получаем a 0 = 6.37, a 1 = 5.88
Примечание: значения столбца №6 y(t) рассчитываются на основе полученного уравнения тренда. Например, t = 1: y(1) = 6.37*1 + 5.88 = 12.26
Уравнение тренда
y = 6.37 t + 5.88Оценим качество уравнения тренда с помощью ошибки абсолютной аппроксимации.
![]()
Поскольку ошибка больше 15%, то данное уравнение не желательно использовать в качестве тренда.
Средние значения:
![]()
![]()
![]()
Дисперсия
![]()
Среднеквадратическое отклонение
Коэффициент эластичности
![]()
Коэффициент эластичности меньше 1. Следовательно, при изменении Х на 1%, Y изменится менее чем на 1%. Другими словами - влияние Х на Y не существенно.
Коэффициент детерминации

т.е. в 82.04 % случаев влияет на изменение данных. Другими словами - точность подбора уравнения тренда - высокая
2. Анализ точности определения оценок параметров уравнения тренда
.
Дисперсия ошибки уравнения.
где m = 1 - количество влияющих факторов в модели тренда.
Стандартная ошибка уравнения.
3. Проверка гипотез относительно коэффициентов линейного уравнения тренда
.
1) t-статистика. Критерий Стьюдента.
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (10;0.025) = 2.228
>
Статистическая значимость коэффициента a 0 подтверждается. Оценка параметра a 0 является значимой и тренд у временного ряда существует..
Статистическая значимость коэффициента a 1 не подтверждается.
Доверительный интервал для коэффициентов уравнения тренда
.
Определим доверительные интервалы коэффициентов тренда, которые с надежность 95% будут следующими:
(a 1 - t набл S a 1 ;a 1 + t набл S a 1)
(6.375 - 2.228*0.943; 6.375 + 2.228*0.943)
(4.27;8.48)
(a 0 - t набл S a 0 ;a 0 + t набл S a 0)
(5.88 - 2.228*6.942; 5.88 + 2.228*6.942)
(-9.59;21.35)
Так как точка 0 (ноль) лежит внутри доверительного интервала, то интервальная оценка коэффициента a 0 статистически незначима.
2) F-статистика. Критерий Фишера.
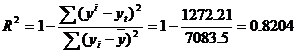
Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
Проверка на наличие автокорреляции остатков
.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
определяется как корреляция между наблюдаемыми показателями, упорядоченными во времени (временные ряды) или в пространстве (перекрестные ряды). Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
В экономических задачах значительно чаще встречается положительная автокорреляция
, нежели отрицательная автокорреляция
. В большинстве случаев положительная автокорреляция вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов.
Отрицательная автокорреляция
фактически означает, что за положительным отклонением следует отрицательное и наоборот. Такая ситуация может иметь место, если ту же зависимость между спросом на прохладительные напитки и доходами рассматривать по сезонным данным (зима-лето).
Среди основных причин, вызывающих автокорреляцию
, можно выделить следующие:
1. Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводят к системным отклонениям точек наблюдения от линии регрессии, что может обусловить автокорреляцию.
2. Инерция. Многие экономические показатели (инфляция, безработица, ВНП и т.д.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Поэтому изменение показателей происходит не мгновенно, а обладает определенной инертностью.
3. Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом).
4. Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его интервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может служить причиной автокорреляции.
Последствия автокорреляции схожи с последствиями гетероскедастичности
: выводы по t- и F-статистикам, определяющие значимость коэффициента регрессии и коэффициента детерминации, возможно, будут неверными.
Обнаружение автокорреляции
1. Графический метод
Есть ряд вариантов графического определения автокорреляции. Один из них увязывает отклонения e i с моментами их получения i. При этом по оси абсцисс откладывают либо время получения статистических данных, либо порядковый номер наблюдения, а по оси ординат – отклонения e i (либо оценки отклонений).
Естественно предположить, что если имеется определенная связь между отклонениями, то автокорреляция имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии автокорреляции.
Автокорреляция становится более наглядной, если построить график зависимости e i от e i-1
Критерий Дарбина-Уотсона
.
Этот критерий является наиболее известным для обнаружения автокорреляции.
При статистическом анализе уравнения регрессии на начальном этапе часто проверяют выполнимость одной предпосылки: условия статистической независимости отклонений между собой. При этом проверяется некоррелированность соседних величин e i .
| y | y(x) | e i = y-y(x) | e 2 | (e i - e i-1) 2 |
| 17.4 | 12.26 | 5.14 | 26.47 | 0 |
| 26.9 | 18.63 | 8.27 | 68.39 | 9.77 |
| 23 | 25 | -2 | 4.02 | 105.57 |
| 23.7 | 31.38 | -7.68 | 58.98 | 32.2 |
| 27.2 | 37.75 | -10.55 | 111.4 | 8.26 |
| 34.5 | 44.13 | -9.63 | 92.72 | 0.86 |
| 50.7 | 50.5 | 0.2 | 0.0384 | 96.53 |
| 61.4 | 56.88 | 4.52 | 20.44 | 18.71 |
| 69.3 | 63.25 | 6.05 | 36.56 | 2.33 |
| 94.4 | 69.63 | 24.77 | 613.62 | 350.63 |
| 61.1 | 76 | -14.9 | 222.11 | 1574.09 |
| 78.2 | 82.38 | -4.18 | 17.46 | 115.03 |
| 1272.21 | 2313.98 |
Для анализа коррелированности отклонений используют статистику Дарбина-Уотсона
:

![]()
Критические значения d 1 и d 2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n = 12 и количества объясняющих переменных m=1.
Автокорреляция отсутствует, если выполняется следующее условие:
d 1 < DW и d 2 < DW < 4 - d 2 .
Не обращаясь к таблицам, можно пользоваться приблизительным правилом и считать, что автокорреляция остатков отсутствует, если 1.5 < DW < 2.5. Поскольку 1.5 < 1.82 < 2.5, то автокорреляция остатков отсутствует
.
Для более надежного вывода целесообразно обращаться к табличным значениям.
По таблице Дарбина-Уотсона для n=12 и k=1 (уровень значимости 5%) находим: d 1 = 1.08; d 2 = 1.36.
Поскольку 1.08 < 1.82 и 1.36 < 1.82 < 4 - 1.36, то автокорреляция остатков отсутствует
.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена
.
Коэффициент ранговой корреляции Спирмена
.
Присвоим ранги признаку Y и фактору X. Найдем сумму разности квадратов d 2 .
По формуле вычислим коэффициент ранговой корреляции Спирмена.
![]()
| t | e i | ранг X, d x | ранг e i , d y | (d x - d y) 2 |
| 1 | -5.14 | 1 | 4 | 9 |
| 2 | -8.27 | 2 | 2 | 0 |
| 3 | 2 | 3 | 7 | 16 |
| 4 | 7.68 | 4 | 9 | 25 |
| 5 | 10.55 | 5 | 11 | 36 |
| 6 | 9.63 | 6 | 10 | 16 |
| 7 | -0.2 | 7 | 6 | 1 |
| 8 | -4.52 | 8 | 5 | 9 | t табл (n-m-1;α/2) = (10;0.05/2) = 2.228
Линейное уравнение тренда имеет вид y = at + b.
Параметры уравнений функции тренда находят с помощью теории корреляции методом наименьших квадратов.
1.Метод наименьших квадратов.
Метод наименьших квадратов МНК), является одним из способов противостоять ошибкам измерений.(Как в Физике погрешность отклонений)
Этот метод как правило используют для нахождения параметров уравнений (Линий, гипербол парабол и т.д.)
Этот способ заключается в минимизации суммы квадратов отклонений.
Смысл МНК можно выразить через вот этот график
2. Анализ точности определения оценок параметров уравнения тренда(по таблице стьюдента находим ТТабл и делаем интервальный прогноз,т.е. выявляем реднеквадратическую ошибку)
3.Проверка гипотез относительно коэффициентов линейного уравнения тренда(статистика критерий стьюдента,фишера)
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена.
Коэффициент ранговой корреляции Спирмена.
36. Методы измерения устойчивости тенденций динамики (коэффициент рангов Спирмена).
Понятие «устойчивость» используется в весьма различных смыслах. По отношению кстатистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивостькак категория, противоположная колеблемости; 2) устойчивость направленности изменений, т.е. устойчивость тенденции.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс ихнаправленного изменения. Можно узнать, например, насколько устойчив процесс сокращенияудельных затрат ресурсов на производство единицы продукции, является ли устойчивойтенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостьюнаправленного изменения уровней динамического ряда следует считать такое изменение, впроцессе которого каждый следующий уровень либо выше всех предшествующих (устойчивыйрост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строгоранжированной последовательности уровней свидетельствует о неполной устойчивостиизменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя.В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч.Спирмэна (Spearman) - rx.
где п - число уровней;
I - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов)времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Этозначение соответствует случаю полной устойчивости возрастания уровней. При полнойпротивоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означаетполную устойчивость процесса сокращения уровней. При хаотическом чередовании ранговуровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции.
Отрицательное значение rx указывает на наличие тенденции снижения уровней, причемустойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в рядудинамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокийкоэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. Вцелом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большаяустойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
37. Моделирование тенденции ряда динамики при наличии структурных изменений.
От сезонных и циклических колебаний следует отличать единовременные изменения характера тенденции временного ряда, вызванные структурными изменениями в экономике или иными факторами. В этом случае, начиная с некоторого момента времени t, происходит изменение характера динамики изучаемого показателя, что приводит к изменению параметров тренда, описывающего эту динамику.
Момент t сопровождается значительными изменениями ряда факторов, оказывающих сильное воздействие на изучаемый показатель Моделирование тенденции временного ряда при наличии структурных изменений.. Чаще всего эти изменения вызваны изменениями в общеэкономической ситуации или событиями глобального характера, приведшими к изменению структуры экономики. Если исследуемый временной ряд включает в себя соответствующий момент времени, то одной из задач его изучения становится выяснение вопроса о том, значительно ли повлияли общие структурные изменения на характер этой тенденции.
Если это влияние значимо, то для моделирования тенденции данного временного ряда следует использовать кусочно-линейные модели регрессии, т.е. разделить исходную совокупность на 2 подсовокупности (до момента времени t и после) и строить отдельно по каждой подсовокупности уравнения линейной регрессии.
Если структурные изменения незначительно повлияли на характер тенденции ряда Моделирование тенденции временного ряда при наличии структурных изменений., то ее можно писать с помощью единого для всей совокупности данных уравнения тренда.
Каждый из описанных выше подходов имеет свои положительные и отрицательные стороны. При построении кусочно-линейной модели снижается остаточная сумма квадратов по сравнению с единым для всей совокупности уравнением тренда. Но разделение совокупности на части ведет к потере числа наблюдений, и к снижению числа степеней свободы в каждом уравнении кусочно-линейной модели. Построение единого уравнения тренда позволяет сохранить число наблюдений исходной совокупности, но остаточная сумма квадратов по этому уравнению будет выше по сравнению с кусочно-линейной моделью. Очевидно, что выбор модели зависит от соотношения между снижением остаточной дисперсии и потерей числа степеней свободы при переходе от единого уравнения регрессии к кусочно-линейной модели.
38. Регрессионный анализ связных динамических рядов.
Многомерные временные ряды, показывающие зависимость результативного признака от одного или нескольких факторных, называютсвязными рядами динамики. Применение методов наименьших квадратов для обработки рядов динамики не требует выдвижения никаких предположений о законах распределения исходных данных. Однако при использовании метода наименьших квадратов для обработки связных рядов следует учитывать наличие автокорреляции (авторегрессии), которая не учитывалась при обработке одномерных рядов динамики, поскольку ее наличие способствовало более плотному и четкому выявлению тенденции развития рассматриваемого социально – экономического явления во времени.
Выявление автокорреляции в уровнях ряда динамики
В рядах динамики экономических процессов между уровнями, особенно близко расположенными, существует взаимосвязь. Ее удобно представить в виде корреляционной зависимости между рядами y1,y2,y3,…..yn h y1+h, y2+h,…, yn+h. Временное смещение L называется сдвигом,а само явление взаимосвязи – автокорреляцией.
Автокорреляционная зависимость особенно существенна между последующими и предшествующими уровнями ряда динамики.
Различают два вида автокорреляции:
Автокорреляция в наблюдениях за одной или более переменными;
Автокорреляция ошибок или автокорреляция в отклонениях от тренда.
Наличие последней приводит к искажению величин средних квадратических ошибок коэффициентов регрессии, что затрудняет построение доверительных интервалов для коэффициентов регрессии, а так же проверку их значимости.
Автокорреляцию измеряют при помощи циклического коэффициента автокорреляции, который может рассчитываться не только между соседними уровнями, т.е. сдвинутыми на один период, но и между сдвинутыми на любое число единиц времени (L). Этот сдвиг, именуемыйвременным лагом, определяет и порядок коэффициентов автокорреляции: первого порядка (при L=1), второго порядка (при L=2) и т.д. Однако наибольший интерес для исследования представляет вычисление нециклического коэффициента (первого порядка), так как наиболее сильные искажения результатов анализа возникают при корреляции между исходными уровнями ряда и теми же уровнями, сдвинутыми на одну единицу времени.
Для суждения о наличии или отсутствия автокорреляции в исследуемом ряду фактическое значение коэффициентов автокорреляции сопоставляется с табличным (критическим) для 5% - го или 1% - го уровня значимости.
Если фактическое значение коэффициента автокорреляции меньше табличного, то гипотеза об отсутствии автокорреляции в ряду может быть принята. Когда же фактическое значение больше табличного, можно сделать вывод о наличии автокорреляции в ряду динамики.
Ряда. Уравнение тренда.
Кривые роста, описывающие закономерности развития явлений во времени, - это результат аналитического выравнивания динамических рядов. Выравнивание ряда с помощью тех или иных функций (т. е. их подгонка к данным) в большинстве случаев оказывается удобным средством описания эмпирических данных. Это средство при соблюдении ряда условий можно применить и для прогнозирования. Процесс выравнивания состоит из следующих основных этапов:
Выбора типа кривой, форма которой соответствует характеру изменения динамического ряда;
Определения численных значений (оценивание) параметров кривой;
Апостериорного контроля качества выбранного тренда.
В современных ППП все перечисленные этапы реализуются одновременно, как правило, в рамках одной процедуры.
Аналитическое сглаживание с использованием той или иной функции позволяет получить выравненные, или, как их иногда не вполне правомерно называют, теоретические значения уровней динамического ряда, т. е. те уровни, которые наблюдались бы, если бы динамика явления полностью совпадала с кривой. Эта же функция с некоторой корректировкой или без нее, применяется в качестве модели для экстраполяции (прогноза).
Вопрос о выборе типа кривой является основным при выравнивании ряда. При всех прочих равных условиях ошибка в решении этого вопроса оказывается более значимой по своим последствиям (особенно для прогнозирования), чем ошибка, связанная со статистическим оцениванием параметров.
Поскольку форма тренда объективно существует, то при выявлении ее следует исходить из материальной природы изучаемого явления, исследуя внутренние причины его развития, а также внешние условия и факторы на него влияющие. Только после глубокого содержательного анализа можно переходить к использованию специальных приемов, разработанных статистикой.
Весьма распространенным приемом выявления формы тренда является графическое изображение временного ряда. Но при этом велико влияние субъективного фактора, даже при отображении выровненных уровней.
Наиболее надежные методы выбора уравнения тренда основаны на свойствах различных кривых, применяемых при аналитическом выравнивании. Такой подход позволяет увязать тип тренда с теми или иными качественными свойствами развития явления. Нам представляется, что в большинстве случаев практически приемлемым является метод, который основывается на сравнении характеристик изменения приростов исследуемого динамического ряда с соответствующими характеристиками кривых роста. Для выравнивания выбирается та кривая, закон изменения прироста которой наиболее близок к закономерности изменения фактических данных.
В табл. 4 приводится перечень наиболее употребительных при анализе экономических рядов видов кривых и указываются соответствующие «симптомы», по которым можно определить, какой вид кривых подходит для выравнивания.
При выборе формы кривой надо иметь в виду еще одно обстоятельство. Рост сложности кривой в целом ряде случаев может действительно увеличить точность описания тренда в прошлом, однако в связи с тем, что более сложные кривые содержат большее число параметров и более высокие степени независимой переменной, их доверительные интервалы будут в общем существенно шире, чем у более простых кривых при одном и том же периоде упреждения.
Таблица 4
Характер изменения показателей, основанных
на средних приростах для различных видов кривых
| Показатель | Характер изменения показателей во времени | Вид кривой |
| Примерно одинаковые | Прямая | |
| Линейно изменяются | Парабола второй степени | |
| Линейно изменяются | Парабола третьей степени | |
| Примерно одинаковые | Экспонента | |
| Линейно изменяются | Логарифмическая парабола | |
| Линейно изменяются | Модифицированная экспонента | |
| Линейно изменяются | Кривая Гомперца |
В настоящее время, когда использование специальных программ без особых усилий позволяет одновременно строить несколько видов уравнений, широко эксплуатируются формальные статистические критерии для определения лучшего уравнения тренда.
Из сказанного выше, по-видимому, можно сделать вывод о том, что выбор формы кривой для выравнивания представляет собой задачу, которая не решается однозначно, а сводится к получению ряда альтернатив. Окончательный выбор не может лежать в области формального анализа, тем более, если предполагается с помощью выравнивания не только статистически описать закономерность поведения уровня в прошлом, но и экстраполировать найденную закономерность в будущее. Вместе с тем различные статистические приемы обработки данных наблюдения могут принести существенную пользу, по крайней мере, с их помощью можно отвергнуть заведомо непригодные варианты и тем самым существенно ограничить поле выбора.
Рассмотрим наиболее используемые типы уравнений тренда:
1.Линейная форма тренда:
где - уровень ряда, полученный в результате выравнивания по прямой;
Начальный уровень тренда;
Средний абсолютный прирост; константа тренда.
Для линейной формы тренда характерно равенство так называемых первых разностей (абсолютных приростов) и нулевые вторые разности, т. е. ускорения.
2.Параболическая (полином 2-ой степени) форма тренда:
![]()
Для данного типа кривой постоянными являются вторые разности (ускорение), а нулевыми – третьи разности.
Параболическая форма тренда соответствует ускоренному или замедленному изменению уровней ряда с постоянным ускорением. Если < 0 и > 0, то квадратическая парабола имеет максимум, если > 0 и < 0 – минимум. Для отыскания экстремума первую производную параболы по t приравнивают 0 и решают уравнение относительно t.
3.Экспоненциальная форма тренда:
где - константа тренда; средний темп изменения уровня ряда.
При > 1 данный тренд может отражать тенденцию ускоренного и все более ускоряющегося возрастания уровней ряда. При < 1 – тенденцию постоянно, все более замедляющегося снижения уровней временного ряда.
4.Гиперболическая форма тренда (1 типа):
Данная форма тренда может отображать тенденцию процессов, ограниченных предельным значением уровня.
5.Логарифмическая форма тренда:
где - константа тренда.
Логарифмическим трендом может быть описана тенденция, проявляющаяся в замедлении роста уровней ряда динамики при отсутствии предельно возможного значения. При достаточно большом t логарифмическая кривая становится мало отличимой от прямой линии.
6.Обратнологарифмическая форма тренда:
![]()
7.Мультипликативная (степенная) форма тренда:
8.Обратная (гиперболическая 2 типа) форма тренда:
9.Гиперболическая форма тренда 3 типа:
10.Полином 3-ей степени:
![]()
Для всех нелинейных, относительно исходных переменных моделей (уравнений регрессии), а их здесь большинство, требуется провести вспомогательные преобразования, представленные в таблице ниже.
Таблица 5
Модели, сводящиеся к линейному тренду
| Модель | Уравнение | Преобразование |
| Мультипликативная (Степенная) | ||
| Гиперболическая I типа | ||
| Гиперболическая II типа | ||
| Гиперболическая III типа | ||
| Логарифмическая | ||
| Обратнологарифмическая |
В формулах, перечисленных в таблице, как и во всех формулах, описывающих модель тренда, есть коэффициенты уравнений.
Однако, при практическом использовании линеаризации с помощью преобразования исследуемых переменных следует иметь ввиду, что оценки параметров, полученных линеаризацией с помощью М.Н.К. (метод наименьших квадратов), минимизируют сумму квадратов отклонений для преобразованных, а не исходных переменных. Поэтому полученные с помощью линеаризации зависимостей оценки нуждаются в уточнении.
Для решения поставленной задачи по аналитическому сглаживанию динамических рядов в системе STATISTICA нам потребуется создать несколько новых дополнительных переменных, необходимых для выполнения дальнейшей работы, а также осуществить некоторые вспомогательные операции по преобразованию нелинейных моделей тренда в линейные.
Итак, нам предстоит построить уравнение тренда, которое по существу является уравнением регрессии, в котором в качестве фактора выступает «время». Прежде всего, мы создадим переменную «Т», содержащую моменты времени четвертого периода. Так как четвертый период включает 12 лет, то переменная «Т» будет состоять из натуральных чисел от 1 до 12, соответствующих месяцам года.
Кроме того, для работы с некоторыми моделями тренда нам потребуется еще несколько переменных, содержание которых можно понять из их обозначения. Это переменные, получаемые из временного ряда: «Т^2», «Т^3», «1/Т» и «ln T». А также переменные, получаемые из исходных данных за четвертый период: «1/Import4» и «ln Import4». Также необходимо создать такую же таблицу для экспорта. Все это предлагается сделать на новом рабочем листе, скопировав туда данные за 4-й период.
Для этого воспользуемся уже известным нам меню Workbook/Insert.
В итоге получаем следующие электронные таблицы.

Рис. 38. Таблица со вспомогательными переменными для импорта

Рис. 39. Таблица со вспомогательными переменными для экспорта
Для аналитического выравнивания рядов динамики мы будем использовать модуль Multiple Regression в меню Statistics. Рассмотрим пример построения графического изображения и определение численных параметров тренда, выраженного линейной зависимостью.

Рис. 40. Модуль Multiple Regression в меню Statistics
Для выбора зависимых и независимых переменных воспользуемся кнопкой Variables.
В открывшемся окне в левом информационном поле мы выбираем зависимую переменную Y t , (в нашем случае это Import 4 – данные по четвертому периоду). Номера выбранных зависимых переменных отображаются внизу в поле Dependent var. (or list for batch). Соответственно в правом поле мы выбираем независимые переменные (в нашем случае одну – время «Т»). Номера выбранных независимых переменных высвечиваются внизу в поле Independent variable list.
После того, как завершен выбор переменных, нажимаем ОК. Система выдает окно с обобщенными результатами расчета параметров тренда (далее они будут рассмотрены более подробно) и возможностью выбора направления для последующего детального анализа. Заметим, что значение оценки, высвеченное красным цветом, указывает на статистическую значимость результатов.

Рис. 41. Закладка Advanced
На закладке располагается несколько кнопок, позволяющих получить максимально детализированные сведения по интересующему нас направлению анализа. При нажатии на нее получаем две таблицы с результатами регрессионного анализа. В первой представлены результаты расчета параметров уравнения регрессии, во второй – основные показатели уравнения.

Рис. 42. Основные показатели уравнения для данных импорта за четвертый период (линейный тренд)
Здесь N = – объем результативной переменной. В верхнем поле расположены показатели R, , Adjusted R, F, p, Std.Error of Estimate , означающие соответственно теоретическое корреляционное отношение, коэффициент детерминации, уточненный коэффициент детерминации, расчетное значение критерия Фишера (в скобках дано число степеней свободы), уровень значимости, стандартная ошибка уравнения (эти же показатели можно увидеть во второй таблице). В самой таблице нас интересуют столбец В , в котором расположены коэффициенты уравнения, столбец t и столбец p-level , обозначающие расчетное значение t-критерия и расчетный уровень значимости, необходимые для оценки значимости параметров уравнения. При этом система помогает пользователю: когда процедура предполагает проверку на значимость, STATISTICA выделяет значимые элементы красным цветом (т.е. отвергается нулевая гипотеза о равенстве параметров нулю). В нашем случае |t факт | > t табл для обоих параметров, следовательно они значимы.

Рис. 43. Параметры уравнения регрессии для данных импорта за четвертый период (линейный тренд)
Для оценки статистической значимости уравнения в целом на закладке Advanced воспользуемся кнопкой ANOVA (Goodness Of Fit), позволяющей получить таблицу дисперсионного анализа и значение F-критерия Фишера.

Рис. 44. Таблица дисперсионного анализа
Sums of Squares – сумма квадратов отклонений: на пересечении со строкой Regression – сумма квадратов отклонений теоретических (полученных по уравнению регрессии) значений признака от средней величины. Эта сумма квадратов используется для расчета факторной, объясненной дисперсии зависимой переменной. На пересечении со строкой Residual – сумма квадратов отклонений теоретических и фактических значений переменной (для расчета остаточной, необъясненной дисперсии), Total – отклонений фактических значений переменной от средней величины (для расчета общей дисперсии). Столбец df – число степеней свободы, Means Squares обозначает дисперсию: на пересечении со строкой Regression – факторную, со строкой Residual - остаточную, F – критерий Фишера, используемый для оценки общей значимости уравнения и коэффициента детерминации, p-level – уровень значимости.
Параметры уравнения тренда в STATISTICA, как и в большинстве других программ, рассчитываются по метод наименьших квадратов (МНК).
Метод позволяет получить значения параметров, при которых обеспечивается минимизация суммы квадратов отклонений фактических уровней от сглаженных, т. е. полученных в результате аналитического выравнивания.
Математический аппарат метода наименьших квадратов описан в большинстве работ по математической статистике, поэтому нет необходимости подробно на нем останавливаться. Напомним только некоторые моменты. Так, для нахождения параметров линейного тренда (2.10) необходимо решить систему уравнений:

Данная система уравнений упрощается, если значения t подобрать таким образом, чтобы их сумма равнялась нулю, т. е. начало отсчета времени перенести в середину рассматриваемого периода. Очевидно, что перенос начала координат имеет смысл только при ручной обработке динамического ряда.
Если , то , .
В общем виде систему уравнений для нахождения параметров полинома ![]() можно записать как
можно записать как

При сглаживании временного ряда по экспоненте (которая часто используется в экономических исследованиях) для определения параметров следует применить метод наименьших квадратов к логарифмам исходных данных.
![]()
После переноса начала отсчета времени в середину ряда получают:
![]()
следовательно:

Если наблюдаются более сложные изменения уровней временного ряда и выравнивание осуществляется по показательной функции вида , то параметры определяются в результате решения следующей системы уравнений:

В практике исследования социально-экономических явлений исключительно редко встречаются динамические ряды, характеристики которых полностью соответствуют признакам эталонных математических функций. Это обусловлено значительным числом факторов разного характера, влияющих на уровни ряда и тенденцию их изменения.
На практике чаще всего строят целый ряд функций, описывающих тренд, а затем выбирают лучшую на основе того или иного формального критерия.

Рис. 45. Закладка Residuals/Assumptions/Prediction
Здесь воспользуемся кнопкой Perform Residual Analysis, открывающую модуль анализа остатков. Под остатками (Residuals) в данном случае понимается отклонение исходных значений динамического ряда от прогнозируемых, в соответствии с выбранным уравнением тренда. Сразу же переходим к закладке Advanced.

Рис. 46. Закладка Advanced в Perform Residual Analysis
Воспользуемся кнопкой Summary: Residuals & Predicted, позволяющую получить одноименную таблицу, которая содержит исходные значения динамического ряда Observed Value, прогнозируемые значения по выбранной модели тренда Predicted Value, отклонения прогнозных значений от исходных Residual Value, а также различные специальные показатели и стандартизированные значения. Также в таблице представлены максимальное, минимальное значения, средняя и медиана по каждому столбцу.

Рис. 47. Таблица, содержащая показатели и специальные значения для линейного тренда
В данной таблицы наибольший интерес для нас представляет столбец Residual Value, значения которого в дальнейшем используются для характеристики качества подбора тренда, а также столбец Predicted Value, который содержит прогнозные значения динамического ряда в соответствии с выбранной моделью тренда (в нашем случае – линейной).
Далее построим график исходного временного ряда совместно с вычисленными в соответствии с линейным уравнением тренда прогнозными значениями для четвертого периода. Для этого лучше всего скопировать значения из столбца Predicted Value в таблицу, в которой были созданы переменные для построения трендов.

Рис. 48. Третий период динамического ряда импорта (млрд. $) и линейный тренд
Итак, мы получили все необходимые результаты расчета параметров тренда, выраженного линейной моделью, для четвертого периода исходного динамического ряда, а также построили график данного ряда, совмещенный с линией тренда. Далее будут представлены остальные модели трендов.
Следует заметить, что в результате линеаризации степенной и экспоненциальной функций STATISTICA возвращает значение линеаризованной функции равное , поэтому для дальнейшего использования их надо преобразовать с помощью следующей элементарной транзакции , в том числе и для построения графических изображений. Для гиперболических функций, а также для обратнологарифмической функции необходимо выполнить преобразование вида .
Для этого также целесообразно создать дополнительные переменные и получить их с помощью формул на основе уже имеющихся переменных.
Итак, при решении задачи с помощью процедуры Multiple Regression, необходимо в качестве переменных выбрать натуральные логарифмы исходного ряда и оси времени.

Рис. 49. Основные показатели уравнения для данных импорта за третий период (степенная модель)

Рис. 50. Параметры уравнения регрессии для данных импорта за третий период (степенная модель)

Рис. 51. Таблица дисперсионного анализа

Рис. 52. Таблица, содержащая показатели и специальные значения для степенной модели
Затем, как и в случае с линейным трендом, копируем значения из столбца Predicted Value в таблицу, но там для этого строим еще одну переменную, в которой получаем прогнозные значения по степенной функции с помощью преобразования .

Рис. 53. Создание дополнительной переменной

Рис. 54. Таблица со всеми переменными

Рис. 55. Третий период динамического ряда импорта (млрд. $) и степенная модель

Рис.56. Основные показатели уравнения для данных импорта за третий период (экспоненциальная модель)

Рис. 57. Третий период динамического ряда импорта (млрд. $) и экспоненциальная модель

Рис.58. Основные показатели уравнения для данных импорта за третий период (обратная модель)

Рис. 59. Третий период динамического ряда импорта (млрд. $) и обратная модель

Рис. 60. Основные показатели уравнения для данных импорта за третий период (полином второй степени)

Рис. 61. Третий период динамического ряда импорта (млрд. $) и полином второй степени

Рис. 62. Основные показатели уравнения для данных импорта за третий период (полином 3-й степени)

Рис. 63. Третий период динамического ряда импорт (млрд. $) и полином 3-й степени

Рис. 64. Основные показатели уравнения для данных импорта за третий период (гипербола 1-ого вида)

Рис. 65. Третий период динамического ряда импорт (млрд. $) и гипербола 1-ого вида

Рис. 66. Основные показатели уравнения для данных импорта за третий период (гипербола 3 типа)

Рис. 67. Третий период динамического ряда импорт и гипербола 3 типа

Рис. 68. Основные показатели уравнения для данных импорта за третий период (логарифмическая модель)

Рис. 69. Третий период динамического ряда импорт (млрд. $) и логарифмическая модель

Рис. 70. Основные показатели уравнения для данных импорта за третий период (обратнологарифмическая модель)

Рис. 71. Третий период динамического ряда импорт (млрд. $) и обратнологарифмическая модель
Затем построим таблицу со вспомогательными переменными для построения трендов для экспорта.

Рис. 72. Таблица со вспомогательными переменными
Проделаем те же операции что и для четвертого период импорта.

Рис. 73. Основные показатели уравнения для данных экспорта за третий период (линейная модель)

Рис. 74. Третий период динамического ряда экспорта (млрд. $) и линейная модель

Рис. 75. Основные показатели уравнения для данных экспорта за третий период (степенная модель тренда)

Рис. 76. Третий период динамического ряда экспорта и степенная модель

Рис. 77. Основные показатели уравнения для данных экспорта за третий период (экспоненциальная модель тренда)

Рис. 78. Третий период динамического ряда экспорта (млрд. $) и экспоненциальная модель

Рис. 79. Основные показатели уравнения для данных экспорта за третий период (обратная модель тренда)
 Рис. 80. Третий период динамического ряда экспорта (млрд. $) и обратная модель
Рис. 80. Третий период динамического ряда экспорта (млрд. $) и обратная модель

Рис. 81. Основные показатели уравнения для данных экспорта за третий период (полином второй степени)

Рис. 82. Третий период динамического ряда экспорта (млрд. $) и полином второй степени

Рис. 83. Основные показатели уравнения для данных экспорта за третий период (полином третей степени)

Рис. 84. Третий период динамического ряда экспорта (млрд. $) и полином третей степени

Рис. 85. Основные показатели уравнения для данных экспорта за третий период (гипербола 1-ого вида)

Рис. 86. Третий период динамического ряда экспорта и гипербола 1-ого типа

Рис. 87. Основные показатели уравнения для данных экспорта за третий период (гипербола 3-ого вида)

Рис. 88. Третий период динамического ряда экспорта (млрд. $) и гипербола 3-ого типа

Рис. 89. Основные показатели уравнения для данных экспорта за третий период (логарифмическая модель)

Рис. 90. Третий период динамического ряда экспорта (млрд. $) и логарифмическая модель

Рис. 91. Основные показатели уравнения для данных экспорта за третий период (обратнологарифмическая модель)

Рис. 91. Третий период динамического ряда экспорта (млрд. $) и обратнологарифмическая модель
Выбор наилучшего тренда
Как уже отмечалось, проблема выбора формы кривой - одна из основных проблем, с которой сталкиваются при выравнивании ряда динамики. Решение этой проблемы во многом определяет результаты экстраполяции тренда. В большинстве специализированных программ для выбора лучшего уравнения тренда предоставляется возможность воспользоваться следующими критериями:
Минимальное значение среднеквадратической ошибки тренда:
 ,
,
где - фактические уровни ряда динамики;
Уровни ряда, определенные по уравнению тренда;
n - число уровней ряда;
p - число факторовв уравнении тренда.
- минимальное значение остаточной дисперсии:
![]()
Минимальное значение средней ошибки аппроксимации;
Минимальное значение средней абсолютной ошибки;
Максимальное значение коэффициента детерминации;
Максимальное значение F- критерия Фишера:
 : ,
: ,
где k – число степеней свободы факторной дисперсии,равное числу независимых переменных (признаков-факторов) в уравнении;
n-k-1 - число степеней свободы остаточной дисперсии.
Применение формального критерия для выбора формы кривой, по-видимому, даст практически пригодные результаты в том случае, если отбор будет проходить в два этапа. На первом этапе отбираются зависимости, пригодные с позиции содержательного подхода к задаче, в результате чего происходит ограничение круга потенциально приемлемых функций. На втором этапе для этих функций подсчитываются значения критерия и выбирается та из кривых, которой соответствует минимальное его значение.
В данном пособии для идентификации тренда используется формальный метод, который основывается на использовании численного критерия. В качестве такого критерия рассматривается максимальный коэффициент детерминации:
 .
.
Расшифровка обозначений и формулы данных показателей даны в предыдущих разделах. Коэффициент детерминации показывает, какая доля общей дисперсии результативного признака обусловлена вариацией признака – фактора. В таблицах STATISTICA он обозначается как R?.
В следующей ниже таблице будут представлены уравнения моделей трендов и коэффициенты детерминации данных импорта.
Таблица 6
Уравнения моделей трендов и коэффициенты детерминации Import.
Сопоставив значения коэффициентов детерминации для различных типов кривых можно сделать вывод о том, что для исследуемого третьего периода лучшей формой тренда будет полином третей степени для импорта и для экспорта.
Далее необходимо проанализировать выбранную модель тренда с точки зрения ее адекватности реальным тенденциям исследуемого временного ряда через оценку надежности полученных уравнений трендов по F-критерию Фишера. В данном случае расчетное значение критерия Фишера для импорта равно 16,573; для экспорта – 13,098, а табличное значение при уровне значимости равно 3,07. Следовательно, эта модель тренда признается адекватно отражающей реальную тенденцию изучаемого явления.
 Education in Great Britain - Образование в Великобритании (5), устная тема по английскому языку с переводом
Education in Great Britain - Образование в Великобритании (5), устная тема по английскому языку с переводом Иван петрович павлов, открытия
Иван петрович павлов, открытия Мария значение имени - характер и судьба
Мария значение имени - характер и судьба