Метод моментов нормальное распределение. Общий индекс цен. Сезонные колебания и волны
Ключевые вопросы: определение, предпосылки модели, понятие и формулы моментов, алгоритм расчёта оценок, применение в нормальном распределении, дискуссия о типе и количестве моментов, достоинства и недостатки подхода .
Метод моментов – один из наиболее известных и популярных методов статистического оценивания параметров вероятностных распределений.
Основные предпосылки модели метода моментов следующие:
Суть метода моментов заключается в вычислении того количества теоретических и выборочных моментов случайной величины, которое равно числу исследуемых нами параметров. После вычисления соответствующие друг другу теоретические и выборочные моменты приравниваются, и исходя из получившегося уравнения осуществляется вычисление оценки параметра.
![]() Формула теоретических моментов выглядит так: где μ’ k – есть k-й теоретический момент величины Y.
Формула теоретических моментов выглядит так: где μ’ k – есть k-й теоретический момент величины Y.

Формула выборочных моментов выглядит так: где m’ k – есть k-й выборочный момент величины Y.
После этого приравниванием μ’ k = m’ k добиваемся вычисления значений параметров.
Рассмотрим в качестве примера нормальное распределение. Нахождение оценок параметров по методу моментов выглядит следующим образом.


Следует заметить, что в уравнения также допустимо включать и такие экзотические виды моментов, как асимметрию и эксцесс, но это необходимо только в специализированных исследованиях. Статистическая практика чаще всего не выходит за рамки обозначенного выше алгоритма, поскольку число подлежащих исследованию параметров обыкновенно не превышает 4.
В качестве достоинств метода моментов следует обозначить, во-первых, то, что его вычислительная реализация сравнительно проста, а, во-вторых, то, что оценки, полученные в качестве решений системы, являются функциями от выборочных моментов, что упрощает исследование статистических свойств оценок данного метода. При больших n распределение оценки такого рода асимптотически нормально, среднее значение отличается от истинного на величину, приблизительно равную n -1 , а стандартное отклонение асимптотически равно cn (-1/2) , где c – определённая числовая константа. Фишер в своё время доказал, однако, что асимптотическая эффективность оценок по методу моментов всегда оказывается меньше 1, и поэтому данный метод уступает, например, методу максимального правдоподобия. Впрочем, иногда в статистических исследованиях оценки, полученные по методу моментов, принимаются в качестве первого приближения, по которым можно определять другими методами оценки более высокой эффективности.
В другом изложении:
Введём сначала следующие определения:
Определение 9 . Начальный момент порядка k случайной величины x определяется равенством: m k = M(x k).
В частности, m 1 = M(x) – обычное мат. ожидание, m 2 = M(x 2).
Определение 10 . Центральный момент порядка k случайной величины x определяется равенством: a k = M((x–Mx) k).
В частности, a 2 = D(x) – дисперсия случайной величины.
Эти моменты называют теоретическими . По данным наблюдений можно вычислить соответствующие эмпирические моменты:
Определение 11
. Начальный эмпирический момент порядка k
случайной величины x определяется равенством 
В частности,  – выборочное среднее.
– выборочное среднее.
Определение 12
. Центральный эмпирический момент порядка k
случайной величины x определяется равенством: 
В частности,  – выборочная дисперсия.
– выборочная дисперсия.
Метод моментов построения точечных оценок неизвестных параметров состоит в приравнивании теоретических моментов рассматриваемого распределения соответствующим эмпирическим моментам того же распределения.
Пусть даны: случайная величина ξ, выборка объема n x 1 , x 2 ,…, x n . Необходимо построить оценки неизвестных параметров q * 1, q * 2 ,…,q * k . Описание метода моментов (ММ) разобьём на этапы:
1. Выписываем первые к моментов μ 1, μ 2, … μ n
2. Вычисляем по выборке соответствующие им эмпирические (выборочные) моменты.
3. С оставляем систему уравнений μ i = m i и решаем ее относительно неизвестных параметров.
Замечание 1. Иногда вместо начальных моментов μ i , m i удобно использовать центральные моменты α i , a i .
Замечание 2 . Если на третьем этапе получилась неразрешимая система, то на первом шаге надо добавить новые моменты.
Найдем методом моментов оценки параметров нескольких важнейших распределений.
С какой оценки начинать? Одним из наиболее известных и простых в употреблении методов является метод моментов. Название связано с тем, что этот метод опирается на использование выборочных моментов
где x1, x2,…, xn - выборка, т.е. набор независимых одинаково распределенных случайных величин с числовыми значениями.
В прикладной статистике метод анализа данных называется методом моментов , если он использует статистику
где g : R q > R k - некоторая функция (здесь k - число неизвестных числовых параметров). Чаще всего термин «метод моментов» используют, когда речь идет об оценивании параметров. В этом случае обычно предполагают, что плотность вероятности распределения элементов выборки f (x ) входит в заранее известное статистику параметрическое семейство {f (x ;и), иєИ}, т.е. f (x ) = f (x ;и 0) при некотором и 0 . Здесь И - заранее заданное k -мерное пространство параметров, являющееся подмножеством евклидова пространства R k , а конкретное значение параметра и 0 статистику неизвестно, его и следует оценить. Известно также, что неизвестный параметр определяется с помощью известной статистику функции через начальные моменты элементов выборки:
В методе моментов в качестве оценки и 0 используют статистику Y n вида (1), которая отличается от формулы (1) тем, что теоретические моменты заменены выборочными.
Статистики Y n вида (1) применяются не только для оценивания параметров, но и для непараметрического оценивания характеристик случайной величины, таких, как коэффициент вариации, и для проверки гипотез. Во всех случаях применения статистики Y n вида (1) говорят о методе моментов.
Распределение вектора Y n во всех практически важных случаях является асимптотически нормальным. Это утверждение опирается на следующий общий факт.
Пусть случайный вектор Z n є R q асимптотически нормален с математическим ожиданием z ? и ковариационной матрицей ||c ij ||/n , а функция h : R q > R 1 достаточно гладкая. Тогда случайная величина h (Z n ) асимптотически нормальна с математическим ожиданием h (z ?) и дисперсией
Для получения асимптотического распределения статистики Y n вида (1) можно применить метод линеаризации к асимптотически нормальному вектору выборочных моментов (M n 1 , M n 2 , …, M n q) и функции g из формулы (1).
Для применения формулы (3) необходимо использовать асимптотические дисперсии и ковариации выборочных моментов, т.е. величины, обозначенные в формуле (3) как c rs . Эти величины имеют вид:
Здесь м r - теоретический центральный момент порядка r , т.е.
Таким образом, для получения асимптотического распределения случайной величины Y n вида (1) достаточно знать теоретические центральные моменты результатов наблюдений и вид функции g .
Однако моменты неизвестны. Их приходится оценивать. В соответствии с теоремами о наследовании сходимости для нахождения асимптотического распределения функции от выборочных моментов можно воспользоваться не теоретическими моментами, а их состоятельными оценками. Эти оценки можно получить разными способами. Можно непосредственно применить формулы (4), заменив теоретические моменты выборочными. Можно выразить моменты через параметры рассматриваемого распределения.
Для оценивания параметров гамма-распределения воспользуемся известной формулой, согласно которой для случайной величины Х , имеющей гамма-распределение с параметрами формы а , масштаба b =1 и сдвига c=0,
Следовательно, M (X ) = a , M (X 2) = a (a +1), D (X ) = M (X 2) - (M (X )) 2 = a (a +1) - a 2 = a . Найдем третий центральный момент M (X - M (X )) 3 . Справедливо равенство
M (X - M (X )) 3 = M (X 3) - 3 M (X 2) M (X ) + 3 M (X) (M (X )) 2 - (M (X )) 3
Из равенства (6) вытекает, что
M (X - M (X )) 3 = a (a +1)(a +2) - 3 a (a +1) a + 3 a a 2 - a 3 = 2a .
Если Y - случайная величина, имеющая гамма-распределение с произвольными параметрами формы a , масштаба b и сдвига c , то Y = bX + c . Следовательно, M (Y ) = ab +c , D (Y ) = ab 2 , M (Y - M (Y )) 3 = 2 a b 3 .
Метод моментов является универсальным. Однако получаемые с его помощью оценки лишь в редких случаях обладают оптимальными свойствами. Поэтому в прикладной статистике применяют и другие виды оценок.
Вариационные ряды распределения состоят их двух элементов вариантов и частот.
Вариантами называются числовые значения колличественного признака в ряду распределения, они могут быть положительными и отрицательными, абсолютными и относительными. Частоты – это численности отдельных вариантов или каждой группы вариационного ряда. Сумма всех частот называется объемом совокупности и определяет число элементов всей совокупности.
Ряды распр-я могут быть образованы по качественному(атрибутивному) и колич-му пр-ку. В первом случае они наз. атрибутивными,а во втором- вариационными.
Вариационные ряды распр-ия по сп-бу постр-ия бывают дискретные и интервальные:
Дискр. вариац. ряд распр-я - группы сост-ны по признаку, изменяющемуся дискретно и приним-му только целые значения. Интервальный вариац. ряд распр-ия - группировачный признак, сост-ий групп-ки, может принимать в опред-ом интервале любые знач-ия. Число ед-ц частоты, приходящиеся на ед-цу инт-ла наз. плотностью распред-я . Ряд накопл-ых частот (кумулятивный)-показ-т число случаев ниже или выше опред-го уровня. Графич изображения ряда распред.: линейные, плоскостные диаграммы, гистограммы, куммулятивная кривая (изображ-ет ряд накопл-х частот)
9. Средняя арифметическая взвешенная.
При расчете средних величин отдельные значения признака, который осредняется, могут повторяться, поэтому расчет средней величины производится по сгруппированным данным. В этом случае речь идет об использовании средней арифметической взвешенной, которая имеет вид: X средн = (EXi*fi)/ Efi
При расчете средней по интервальному вариационному ряду для выполнения необходимых вычислений от интервалов переходят к их серединам.
Расчет средней по способу моментов. Основан на свойствах средней арифметической. В качестве условного ноля – X0 выбирают середину одного из центральных интервалов, обладающего наибольшей частотой.Этот способ используется только в рядах с равными интервалами.
10. Средняя гармоническая простая и взвеш.
Средняя гармоническая. Эту среднюю называют обратной средней арифметической, поскольку эта величина используется при k = -1. Простая средняя гармоническая используется тогда, когда веса значений признака одинаковы. Ее формулу можно вывести из базовой формулы, подставив k = -1:
К примеру, нам нужно вычислить среднюю
скорость двух автомашин, прошедших один
и тот же путь, но с разной скоростью:
первая - со скоростью 100 км/ч, вторая - 90
км/ч. Применяя метод средней гармонической,
мы вычисляем среднюю скорость:
примеру, нам нужно вычислить среднюю
скорость двух автомашин, прошедших один
и тот же путь, но с разной скоростью:
первая - со скоростью 100 км/ч, вторая - 90
км/ч. Применяя метод средней гармонической,
мы вычисляем среднюю скорость:
В статист практике чаще исп гармонич взвеш , формула кот имеет вид:
Данная формула используется в тех случаях, когда веса (или объемы явлений) по каждому признаку не равны. В исходном соотношении для расчета средней известен числитель, но неизвестен знаменатель.
Например, при расчете средней цены мы должны пользоваться отношением суммы реализации к количеству реализованных единиц. Нам не известно количество реализованных единиц (речь идет о разных товарах), но известны суммы реализаций этих различных товаров. Допустим, необходимо узнать среднюю цену реализованных товаров: Вид товара Цена за единицу, руб.Сумма реализаций, руб.
Получаем
Е![]() сли
здесь использовать формулу средней
арифметической, то можно получить
среднюю цену, которая будет нереальна:
сли
здесь использовать формулу средней
арифметической, то можно получить
среднюю цену, которая будет нереальна:
11. Упрощенный расчет средней арифм. (ср. ар.) (способ моментов).
Пользуясь св-ми ср. ар., ее можно рассчитать след. образом: 1) вычесть из всех вариант постоянное число (лучше значение серединной варианты); 2) разделить варианты на постоянное число – на величину интервала; 3) частоты выразить в %. Вычисление ср. ар. первыми двумя способами называется способом отсчета от условного начала (способом моментов). Этот способ применяется в рядах с разными интервалами. Ср. ар. в этом случае опред. по ф-ле:
 Где m
– момент первого порядка; х 0
– начало отсчета; К – величина интервала.
Где m
– момент первого порядка; х 0
– начало отсчета; К – величина интервала.
12. Мода и медиана.
Д ля
определения структуры совокупности
используют особые средние показатели,
к которым относятся медиана и мода, или
так называемые структурные средние.
Медиана
(Ме)
- это величина, которая соответствует
варианту, находящемуся в середине
ранжированного ряда. Для ранжированного
ряда с нечетным числом индивидуальных
величин (например, 1, 2, 3, 3, 6, 7, 9, 9, 10)
медианой будет величина, которая
расположена в центре ряда, т.е. пятая
величина. Для ранжированного ряда с
четным числом индивидуальных величин
(например, 1, 5, 7, 10, 11, 14) медианой будет
средняя арифметическая величина, которая
рассчитывается из двух смежных величин.
Для нашего случая медиана равна (7+10) :
2= 8,5. То есть для нахождения медианы
сначала необходимо определить ее
порядковый номер (ее положение в
ранжированном ряду) по формуле Nme=(n+1)/2,
где n - число единиц в совокупности.
Численное значение медианы определяют
по накопленным частотам в дискретном
вариационном ряду. Для этого сначала
следует указать интервал нахождения
медианы в интервальном ряду распределения.
Медианным называют первый интервал,
где сумма накопленных частот превышает
половину наблюдений от общего числа
всех наблюдений. Численное значение
медианы обычно определяют по формуле-----
где xМе - нижняя
граница медианного интервала; i - величина
интервала; S-1 - накопленная частота
интервала, которая предшествует
медианному; f - частота медианного
интервала.
ля
определения структуры совокупности
используют особые средние показатели,
к которым относятся медиана и мода, или
так называемые структурные средние.
Медиана
(Ме)
- это величина, которая соответствует
варианту, находящемуся в середине
ранжированного ряда. Для ранжированного
ряда с нечетным числом индивидуальных
величин (например, 1, 2, 3, 3, 6, 7, 9, 9, 10)
медианой будет величина, которая
расположена в центре ряда, т.е. пятая
величина. Для ранжированного ряда с
четным числом индивидуальных величин
(например, 1, 5, 7, 10, 11, 14) медианой будет
средняя арифметическая величина, которая
рассчитывается из двух смежных величин.
Для нашего случая медиана равна (7+10) :
2= 8,5. То есть для нахождения медианы
сначала необходимо определить ее
порядковый номер (ее положение в
ранжированном ряду) по формуле Nme=(n+1)/2,
где n - число единиц в совокупности.
Численное значение медианы определяют
по накопленным частотам в дискретном
вариационном ряду. Для этого сначала
следует указать интервал нахождения
медианы в интервальном ряду распределения.
Медианным называют первый интервал,
где сумма накопленных частот превышает
половину наблюдений от общего числа
всех наблюдений. Численное значение
медианы обычно определяют по формуле-----
где xМе - нижняя
граница медианного интервала; i - величина
интервала; S-1 - накопленная частота
интервала, которая предшествует
медианному; f - частота медианного
интервала.
Модой (Мо) называют значение признака, которое встречается наиболее часто у единиц совокупности. Для дискретного ряда модой будет являться вариант с наибольшей частотой. Для определения моды интервального ряда сначала определяют модальный интервал (интервал, имеющий наибольшую частоту). Затем в пределах этого интервала находят то значение признака, которое может являться модой. Чтобы найти конкретное значение моды, необходимо использовать формулу

где xМо - нижняя граница модального интервала; iМо - величина модального интервала; fМо - частота модального интервала; fМо-1 - частота интервала, предшествующего модальному; fМо+1 - частота интервала, следующего за модальным.
Мода имеет широкое распространение в маркетинговой деятельности при изучении покупательского спроса, особенно при определении пользующихся наибольшим спросом размеров одежды и обуви, при регулировании ценовой политики.
13. Свойства средней ариф. (ср. ар.)
1.Если
из всех вариантов ряда (-) или ко всем
вариантам (+) постоянное число, то ср.
ар. соответственно уменьшится или
увеличится на это число.
 .2.Если
все варианты ряда умножить или разделить
на постоянное число, то ср. ар. соответственно
увеличится или уменьшится в это число
раз.
.2.Если
все варианты ряда умножить или разделить
на постоянное число, то ср. ар. соответственно
увеличится или уменьшится в это число
раз.
 3.Если
все частоты увеличить или уменьшить в
постоянное число раз, то средняя от
этого не изменится.
3.Если
все частоты увеличить или уменьшить в
постоянное число раз, то средняя от
этого не изменится.
 .
.
4.Сумма
отклонений всех вариантов ряда от ср.
ар. = 0. (Нулевое свойство средней).
.
5. Σf i =Σfix i
.
Произведение
средней на сумму частот всегда равно
сумме произведений вариант на частоты.
Σf i =Σfix i
.
Произведение
средней на сумму частот всегда равно
сумме произведений вариант на частоты.
6
 .Сумма
квадратов отклонений всех вариантов
ряда от ср. ар.
.Сумма
квадратов отклонений всех вариантов
ряда от ср. ар.
Данное св-во положено в основу метода наименьших квадратов, кот. широко применяется в исследовании стат. взаимосвязей.
14. Виды дисперсий. Правило их сложения .
Р азличают
три вида дисперсий: общая; средняя
внутригрупповая; межгрупповая. Общая
дисперсия (
2
о
)
характеризует вариацию признака всей
совокупности под влиянием всех тех
факторов, которые обусловили данную
вариацию. Эта величина определяется по
формуле 2
о = (X
– Xо
средн) 2 *f
/ f,
где Xо
средн - общая средняя арифметическая
всей исследуемой совокупности. Средняя
внутригрупп дисперс
(
2
средн
) свидетельствует
о случайной вариации, которая может
возникнуть под влиянием каких-либо
неучтенных факторов и которая не зависит
от признака-фактора, положенного в
основу группировки. Данная дисперсия
рассчитывается следующим образом:
сначала рассчитываются дисперсии по
отдельным группам (
2
i
),
затем рассчитывается средняя
внутригрупповая дисперсия (
2
i
cредн):
где ni - число единиц в группе. Межгрупповая
дисперсия
характеризует
систематическую вариацию, т.е. различия
в величине исследуемого признака,
возникающие под влиянием признака-фактора,
который положен в основу группировки.
Эта дисперсия рассчитывается по формуле
азличают
три вида дисперсий: общая; средняя
внутригрупповая; межгрупповая. Общая
дисперсия (
2
о
)
характеризует вариацию признака всей
совокупности под влиянием всех тех
факторов, которые обусловили данную
вариацию. Эта величина определяется по
формуле 2
о = (X
– Xо
средн) 2 *f
/ f,
где Xо
средн - общая средняя арифметическая
всей исследуемой совокупности. Средняя
внутригрупп дисперс
(
2
средн
) свидетельствует
о случайной вариации, которая может
возникнуть под влиянием каких-либо
неучтенных факторов и которая не зависит
от признака-фактора, положенного в
основу группировки. Данная дисперсия
рассчитывается следующим образом:
сначала рассчитываются дисперсии по
отдельным группам (
2
i
),
затем рассчитывается средняя
внутригрупповая дисперсия (
2
i
cредн):
где ni - число единиц в группе. Межгрупповая
дисперсия
характеризует
систематическую вариацию, т.е. различия
в величине исследуемого признака,
возникающие под влиянием признака-фактора,
который положен в основу группировки.
Эта дисперсия рассчитывается по формуле
г де
- средняя величина по отдельной группе.
Все три вида дисперсии связаны между
собой: общая дисперсия равна сумме
средней внутригрупповой дисперсии и
межгрупповой дисперсии:
де
- средняя величина по отдельной группе.
Все три вида дисперсии связаны между
собой: общая дисперсия равна сумме
средней внутригрупповой дисперсии и
межгрупповой дисперсии:
Д![]() анное
соотношение отражает закон, который
называют правилом сложения дисперсий.
Согласно этому закону (правилу), общая
дисперсия, которая возникает под влиянием
всех факторов, равна сумме дисперсий,
которые появляются как под влиянием
признака-фактора, положенного в основу
группировки, так и под влиянием других
факторов. Благодаря правилу сложения
дисперсий можно определить, какая часть
общей дисперсии находится под влиянием
признака-фактора, положенного в основу
группировки.
анное
соотношение отражает закон, который
называют правилом сложения дисперсий.
Согласно этому закону (правилу), общая
дисперсия, которая возникает под влиянием
всех факторов, равна сумме дисперсий,
которые появляются как под влиянием
признака-фактора, положенного в основу
группировки, так и под влиянием других
факторов. Благодаря правилу сложения
дисперсий можно определить, какая часть
общей дисперсии находится под влиянием
признака-фактора, положенного в основу
группировки.
15 . Виды средних. Их исчисление .

16. Показатели вариации, применяемые в статистике.
Вариация, т.е. несовпадение уровней одного и того же показателя у разных объектов, имеет объективный характер и помогает познать сущность изучаемого явления. Для измерения вариации в статистике применяют несколько способов. Наиболее простым явл расчет показателя размаха вариации Н как разницы между Xmax и Xmin: H=Xmax - Xmin. Но размах вариации показывает лишь крайние значения признака. Повторяемость промежуточных значений здесь не учитывается. Среднее линейное отклонение d - среднее арифметическое значение абсолютных отклонений признака от его среднего уровня: d = (Xi – X средн) / n. При повторяемости отдельных значений Х используют формулу средней арифметической взвешенной. В статистических научных исследованиях для измерения вариации чаще всего применяют показатель дисперсии: δ = (Xi – X средн) 2 / n. Показатель s, равный √δ 2 , называется средним квадратическим отклонением. Величина Mx = √(δ 2 /n)-средняя ошибка выборки и явля хар-кой отклонения выборочного среднего значения призн от его истинной средней величины. Показатель средней ошибки использ при оценке достоверности результатов выборочн наблюд. Коэфф осцилляции отражает относит колеблемость крайних значений признака вокруг средней: Ko = (R/X средн)*100%. Относительное линейное отключение характеризует долю усредненного значения признака абсолютных отклонений от средней величины Kd = (d средн/ X средн)*100%. Коэффициент вариации: V = (δ/X средн)*100%
17. Простейшие приёмы обработки рядов динамики.
Простейшими видами обработки рядов динамики являются: укрупнение интервалов, метод скользящей средней, аналитическое выравнивание, экстраполяция и интерполяция.
Укрупнение интервалов. Ряд динамики разделяют на достаточно большое число равных интервалов. Если средн уровни по интервалам не позволяют увидеть тенденцию разв, переходят к расчету уровней за большие промежутки времени, увеличивая длину каждого интервала (уменьшая количество интервалов). Скользящая средняя. В этом методе исходные уровни ряда заменяются средними величинами, которые получают из данного уровня и нескольких симметрично его окружающих. Целое число уровней, по которым рассчитывается среднее значение, называют интервалом сглаживания. Для того чтобы создать модель, выражающую основную тенденцию изменения уровней динамического ряда во времени, используется аналитическое выравнивание ряда динамики. Простейшими моделями, выражающими тенденцию развития, являются: линейная функция прямой, показательная функция, парабола, парабола n-порядка, гипербола, экспонента. Иногда возникает необходимость предвидеть будущий уровень ряда динамики. В таких случаях прибегают к приему обработки рядов динамики, называемому экстраполяцией : y n +1 = y n + ∆y n +∆∆y n , где y n +1 - неизвестный уровень ряда, y n - последний известный уровень ряда, ∆y n - цепной абсолютный прирост последнего уровня ряда (∆y n = y n - y n -1), ∆∆y n - изменение прироста последнего уровня ряда. Наряду с экстраполяцией иногда применяется такой прием обработки рядов динамики, как интерполяция - искусственное нахождение отсутствующих членов внутри динамического ряда. Неизвестный уровень ряда находится по формуле: y i = (y i +1 + y i -1) / 2. Где: y i - неизвестный уровень ряда, y i +1 - последующий за неизвестным уровень ряда, y i -1 - предыдущий уровень ряда.
Пусть, как и прежде, - исследуемая -мерная случайная величина, подчиняющаяся закону распределения где функция - плотность вероятности, если непрерывна, и вероятность если дискретна, зависит от некоторого, вообще говоря, многомерного параметра . И пусть мы хотим оценить неизвестное значениехэтого параметра, т. е. построить оценку 0 по имеющейся в нашем распоряжении выборке, состоящей из независимых наблюдений где
Метод моментов заключается в приравнивании определенного количества выборочных моментов к соответствующим теоретическим (т. е. вычисленным с использованием функции моментам исследуемой случайной величины, причем последние, очевидно, являются функциями от неизвестных параметров Рассматривая количество моментов, равное числу k подлежащих оценке параметров, и решая полученные уравнения относительно этих параметров, мы получаем искомые оценки. Таким образом, оценки по методу моментов неизвестных параметров являются решениями системы уравнений:

(очевидно, если анализируемая случайная величина дискретна, интегралы в левых частях (8.25) следует заменить соответствующими суммами типа
Число уравнений в системе (8.25) должно быть равным числу k оцениваемых параметров. Вопрос о том, какие именно моменты включать в систему (8.25) (начальные, центральные или их некоторые модификации типа коэффициентов асимметрии или эксцесса), следует решать, руководствуясь конкретными целями исследования и сравнительной простотой формы зависимости альтернативных теоретических характеристик от оцениваемых параметров . В статистической практике дело редко доходит даже до моментов четвертого порядка (исключение составляет, пожалуй, практика эксплуатации так называемой «системы кривых Пирсона», см., например, , однако этот чисто формальный аппарат подгонки эмпирического распределения под одну из теоретических кривых практически не в состоянии, с нашей точки зрения, решать сколь-нибудь интересные задачи содержательного статистического анализа данных).
К достоинствам метода моментов следует отнести его сравнительно простую вычислительную реализацию, а также то, что оценки, полученные в качестве решений системы (8.25), являются функциями от выборочных моментов. Это упрощает исследование статистических свойств оценок метода моментов: можно показать (см. ), что при довольно общих условиях распределение оценки такого рода при больших асимптотически-нормально, среднее значение такой оценки отличается от истинного значения параметра на величину порядка , а стандартное
отклонение асимптотически имеет вид , где с - некоторая постоянная величина.
В то же время, как показал Р. Фишер (см. ), асимптотическая эффективность оценок, полученных методом моментов, оказывается, как правило, меньше единицы, и в этом отношении они уступают оценкам, полученным методом максимального правдоподобия. Тем не менее метод моментов часто очень удобен на практике. Иногда оценки, получаемые с помощью метода моментов, принимаются в качестве первого приближения, по которому можно определять другими методами оценки более высокой эффективности.
Вернемся к нашим примерам.
В примере 8.3 в качестве системы (8.25) имеем:

что дает уже знакомые нам по методу максимального правдоподобия оценки для параметров:

Нормальное распределение, так же как и распределение Пуассона (в чем легко убедиться, обратившись к примеру 8.4), относится к тем редким случаям, когда оценки по методу моментов совпадают с оценками по методу максимального правдоподобия.
Построение системы (8.25) в примере 8.5 дает:

Откуда легко получаем оценки:

Можно сравнить асимптотическую эффективность оценок, полученных методом максимального правдоподобия и методом моментов: учитывая, что дисперсия оценок (8.26) как дисперсия функций выборочных моментов имеет порядок (см. ), и принимая во внимание соотношение (8.22), в соответствии с которым дисперсии оценок по методу максимального правдоподобия тех же параметров имеют порядок получаем, что эффективность в сравнении с эффективностью и стремится к нулю при
Реализация метода моментов в примере 8.6 дает
Признаки единиц статистических совокупностей различны по своему значению, например, заработная плата рабочих одной профессии какого-либо предприятия не одинакова за один и тот же период времени, различны цены на рынке на одинаковую продукцию, урожайность сельскохозяйственных культур в хозяйствах района и т.д. Поэтому, чтобы определить значение признака, характерное для всей изучаемой совокупности единиц, рассчитывают средние величины.
Средняя величина
–
это обобщающая характеристика множества индивидуальных значений некоторого количественного признака.
Совокупность, изучаемая по количественному признаку, состоит из индивидуальных значений; на них оказывают влияние, как общие причины, так и индивидуальные условия. В среднем значении отклонения, характерные для индивидуальных значений, погашаются. Средняя, являясь функцией множества индивидуальных значений, представляет одним значением всю совокупность и отражает то общее, что присуще всем ее единицам.
Средняя, рассчитываемая для совокупностей, состоящих из качественно однородных единиц, называется типической средней . Например, можно рассчитать среднемесячную заработную плату работника той или иной профессиональной группы (шахтера, врача библиотекаря). Разумеется, уровни месячной заработной платы шахтеров в силу различия их квалификации, стажа работы, отработанного за месяц времени и многих других факторов отличаются друг от друга, так и от уровня средней заработной платы. Однако в среднем уровне отражены основные факторы, которые влияют на уровень заработной платы, и взаимно погашаются различия, которые возникают вследствие индивидуальных особенностей работника. Средняя заработная плата отражает типичный уровень оплаты труда для данного вида работников. Получению типической средней должен предшествовать анализ того, насколько данная совокупность качественно однородна. Если совокупность состоит их отдельных частей, следует разбить ее на типические группы (средняя температура по больнице).
Средние величины, используемые в качестве характеристик для неоднородных совокупностей, называются системными средними . Например, средняя величина валового внутреннего продукта (ВВП) на душу населения, средняя величина потребления различных групп товаров на человека и другие подобные величины, представляющие обобщающие характеристики государства как единой экономической системы.
Средняя должна вычисляться для совокупностей, состоящих из достаточно большого числа единиц. Соблюдение этого условия необходимо для того, чтобы вошел в силу закон больших чисел, в результате действия которого случайные отклонения индивидуальных величин от общей тенденции взаимно погашаются.
Виды средних и способы их вычисления
Выбор вида средней определяется экономическим содержанием определенного показателя и исходных данных. Однако любая средняя величина должна вычисляться так, чтобы при замене ею каждой варианты осредняемого признака не изменился итоговый, обобщающий, или, как его принято называть, определяющий показатель
, который связан с осредняемым показателем. Например, при замене фактических скоростей на отдельных отрезках пути их средней скоростью не должно измениться общее расстояние, пройденное транспортным средством за одно и тоже время; при замене фактических заработных плат отдельных работников предприятия средней заработной платой не должен измениться фонд заработной платы. Следовательно, в каждом конкретном случае в зависимости от характера имеющихся данных, существует только одно истинное среднее значение показателя, адекватное свойствам и сущности изучаемого социально-экономического явления.
Наиболее часто применяются средняя арифметическая, средняя гармоническая, средняя геометрическая, средняя квадратическая и средняя кубическая.
Перечисленные средние относятся к классу степенных
средних и объединяются общей формулой:
,
где – среднее значение исследуемого признака;
m – показатель степени средней;
– текущее значение (варианта) осредняемого признака;
n – число признаков.
В зависимости от значения показателя степени m различают следующие виды степенных средних:
при m = -1 – средняя гармоническая ;
при m = 0 – средняя геометрическая ;
при m = 1 – средняя арифметическая ;
при m = 2 – средняя квадратическая ;
при m = 3 – средняя кубическая .
При использовании одних и тех же исходных данных, чем больше показатель степени m в вышеприведенной формуле, тем больше значение средней величины:
.
Это свойство степенных средних возрастать с повышением показателя степени определяющей функции называется правилом мажорантности средних
.
Каждая из отмеченных средних может приобретать две формы: простую
и взвешенную
.
Простая форма средней
применяется, когда средняя вычисляется по первичным (несгруппированными) данным. Взвешенная форма
– при расчете средней по вторичным (сгруппированным) данным.
Средняя арифметическая
Средняя арифметическая применяется, когда объем совокупности представляет собой сумму всех индивидуальных значений варьирующего признака. Следует отметить, что если вид средней величины не указывается, подразумевается средняя арифметическая. Ее логическая формула имеет вид:![]()
Средняя арифметическая простая
рассчитывается по несгруппированным данным
по формуле:![]() или ,
или ,
где – отдельные значения признака;
j – порядковый номер единицы наблюдения, которая характеризуется значением ;
N – число единиц наблюдения (объем совокупности).
Пример.
В лекции «Сводка и группировка статистических данных» рассматривались результаты наблюдения стажа работы бригады из 10 человек. Рассчитаем средний стаж работы рабочих бригады. 5, 3, 5, 4, 3, 4, 5, 4, 2, 4.
По формуле средней арифметической простой вычисляются также средние в хронологическом ряду
, если интервалы времени, за которое представлены значения признака, равны.
Пример.
Объем реализованной продукции за первый квартал составил 47 ден. ед., за второй 54, за третий 65 и за четвертый 58 ден. ед. Среднеквартальный оборот составляет (47+54+65+58)/4 = 56 ден. ед.
Если в хронологическом ряду приведены моментные показатели, то при вычислении средней они заменяются полусуммами значений на начало и конец периода.
Если моментов больше двух и интервалы между ними равны, то средняя вычисляется по формуле средней хронологической
 ,
,
где n- число моментов времени
В случае, когда данные сгруппированы по значениям признака
(т. е. построен дискретный вариационный ряд распределения) средняя арифметическая взвешенная
рассчитывается с использовании либо частот , либо частостей наблюдения конкретных значений признака , число которых (k) значительно меньше числа наблюдений (N) .
,
,
где k – количество групп вариационного ряда,
i – номер группы вариационного ряда.
Поскольку , а , получаем формулы, используемые для практических расчетов:
и
Пример.
Рассчитаем средний стаж рабочих бригад по сгруппированному ряду.
а) с использованием частот:
б) с использованием частостей:
В случае, когда данные сгруппированы по интервалам
, т.е. представлены в виде интервальных рядов распределения, при расчете средней арифметической в качестве значения признака принимают середину интервала, исходя из предположения о равномерном распределении единиц совокупности на данном интервале. Расчет ведется по формулам:
и
где - середина интервала: ,
где и – нижняя и верхняя границы интервалов (при условии, что верхняя граница данного интервала совпадает с нижней границей следующего интервала).
Пример.
Рассчитаем среднюю арифметическую интервального вариационного ряда, построенного по результатам исследования годовой заработной платы 30 рабочих (см. лекцию «Сводка и группировка статистических данных»).
Таблица 1 – Интервальный вариационный ряд распределения.
Интервалы, грн. |
Частота, чел. |
Частость, |
Середина интервала, |
||
600-700 |
3 |
0,10 |
(600+700):2=650 |
1950 |
65 |
![]() грн. или
грн. или ![]() грн.
грн.
Средние арифметические, вычисленные на основе исходных данных и интервальных вариационных рядов, могут не совпадать из-за неравномерности распределения значений признака внутри интервалов. В этом случае для более точного вычисления средней арифметической взвешенной следует использовать не средины интервалов, а средние арифметические простые, рассчитанные для каждой группы (групповые средние
). Средняя, вычисленная по групповым средним с использованием взвешенной формулы расчета, называется общей средней
.
Средняя арифметическая обладает рядом свойств.
1. Сумма отклонений вариант от средней равна нулю:
.
2. Если все значения вариант увеличиваются или уменьшаются на величину А, то и средняя величина увеличивается или уменьшается на ту же величину А:![]()
3. Если каждую варианту увеличить или уменьшить в В раз, то средняя величина также увеличится или уменьшатся в то же количество раз:
или ![]()
4. Сумма произведений вариант на частоты равна произведению средней величины на сумму частот:![]()
5. Если все частоты разделить или умножить на какое-либо число, то средняя арифметическая не изменится:
6) если во всех интервалах частоты равны друг другу, то средняя арифметическая взвешенная равна простой средней арифметической:![]() ,
,
где k – количество групп вариационного ряда.
Использование свойств средней позволяет упростить ее вычисление.
Допустим, что все варианты (х) сначала уменьшены на одно и то же число А, а затем уменьшены в В раз. Наибольшее упрощение достигается, когда в качестве А выбирается значение середины интервала, обладающего наибольшей частотой, а в качестве В – величина интервала (для рядов с одинаковыми интервалами). Величина А называется началом отсчета, поэтому этот метод вычисления средней называется спосо
бом отсчета от условного нуля
или способом моментов
.
После такого преобразования получим новый вариационный ряд распределения, варианты которого равны . Их средняя арифметическая, называемая моментом первого порядка,
выражаетсяформулой и согласно второго и третьего свойств средней арифметической равна средней из первоначальных вариант, уменьшенной сначала на А, а потом в В раз, т. е. .
Для получения действительной средней
(средней первоначального ряда)нужно момент первого порядка умножить на В и прибавить А:
Расчет средней арифметической по способу моментов иллюстрируется данными табл. 2.
Таблица 2 – Распределение работников цеха предприятия по стажу работы
Стаж работников, лет |
Количество работников |
Середина интервала |
|||
0 – 5 |
12 |
2,5 |
15 |
3 |
36 |
Находим момент первого порядка ![]() . Затем, зная, что А=17,5, а В=5, вычисляем средний стаж работы работников цеха:
. Затем, зная, что А=17,5, а В=5, вычисляем средний стаж работы работников цеха:
лет
Средняя гармоническая
Как было показано выше, средняя арифметическая применяется для расчета среднего значения признака в тех случаях, когда известны его варианты x и их частоты f.
Если статистическая информация не содержит частот f по отдельным вариантам x совокупности, а представлена как их произведение , применяется формула средней гармонической взвешенной
. Чтобы вычислить среднюю, обозначим , откуда . Подставив эти выражения в формулу средней арифметической взвешенной, получим формулу средней гармонической взвешенной: ,
,
где - объем (вес) значений признака показателя в интервале с номером i (i=1,2, …, k).
Таким образом, средняя гармоническая применяется в тех случаях, когда суммированию подлежат не сами варианты, а обратные им величины: ![]() .
.
В тех случаях, когда вес каждой варианты равен единице, т.е. индивидуальные значения обратного признака встречаются по одному разу, применяется средняя гармоническая простая
: ,
,
где – отдельные варианты обратного признака, встречающиеся по одному разу;
N – число вариант.
Если по двум частям совокупности численностью и имеются средние гармонические, то общая средняя по всей совокупности рассчитывается по формуле: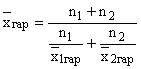
и называется взвешенной гармонической средней из групповых средних
.
Пример.
В ходе торгов на валютной бирже за первый час работы заключены три сделки. Данные о сумме продажи гривны и курсе гривны по отношению к доллару США приведены в табл. 3 (графы 2 и 3). Определить средний курс гривны по отношению к доллару США за первый час торгов.
Таблица 3 – Данные о ходе торгов на валютной бирже
Средний курс доллара определяется отношением суммы проданных в ходе всех сделок гривен к сумме приобретенных в результате этих же сделок долларов. Итоговая сумма продажи гривны известна из графы 2 таблицы, а количество купленных в каждой сделке долларов определяется делением суммы продажи гривны к ее курсу (графа 4). Всего в ходе трех сделок куплено 22 млн. дол. Значит, средний курс гривны за один доллар составил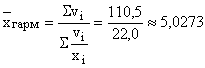 .
.
Полученное значение является реальным, т.к. замена им фактических курсов гривны в сделках не изменит итоговой суммы продаж гривны, выступающей в качестве определяющего показателя
: млн. грн.
Если бы для расчета была использована средняя арифметическая, т.е. ![]() гривны, то по обменному курсу на покупку 22 млн. дол. нужно было бы затратить 110,66 млн. грн., что не соответствует действительности.
гривны, то по обменному курсу на покупку 22 млн. дол. нужно было бы затратить 110,66 млн. грн., что не соответствует действительности.
Средняя геометрическая
Средняя геометрическая используется для анализа динамики явлений и позволяет определить средний коэффициент роста. При расчете средней геометрической индивидуальные значения признака представляют собой относительные показатели динамики, построенные в виде цепных величин, как отношения каждого уровня к предыдущему.
Средняя геометрическая простая рассчитывается по формуле: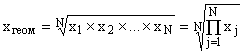 ,
,
где – знак произведения,
N – число осредняемых величин.
Пример.
Количество зарегистрированных преступлений за 4 года возросло в 1,57 раза, в т. ч. за 1-й – в 1,08 раза, за 2-й – в 1,1 раза, за 3-й – в 1,18 и за 4-й – в 1,12 раза. Тогда среднегодовой темп роста количества преступлений составляет: , т.е. число зарегистрированных преступлений ежегодно росло в среднем на 12%.
1,8
-0,8
0,2
1,0
1,4
1
3
4
1
1
3,24
0,64
0,04
1
1,96
3,24
1,92
0,16
1
1,96
Для расчета средней квадратической взвешенной определяем и заносим в таблицу и . Тогда средняя величина отклонений длины изделий от заданной нормы равна: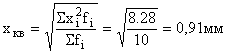
Средняя арифметическая в данном случае была бы непригодна, т.к. в результате мы получили бы нулевое отклонение.
Применение средней квадратической будет рассмотрено далее в показателях вариации.
 Координатная плоскость: что это такое?
Координатная плоскость: что это такое? Факторы, влияющие на рН и рОН буферных растворов
Факторы, влияющие на рН и рОН буферных растворов Ребусы и кроссворды по русскому языку материал по русскому языку (7 класс) на тему Ребусы по русскому языку сложные
Ребусы и кроссворды по русскому языку материал по русскому языку (7 класс) на тему Ребусы по русскому языку сложные