Статистическая значимость формула. Статистическая значимость. Вычисление статистической значимости
Сегодня это действительно слишком просто: вы можете подойти к компьютеру и практически без знания того, что вы делаете, создавать разумное и бессмыслицу с поистине изумительной быстротой. (Дж. Бокс)
Основные термины и понятия медицинской статистики
В данной статье мы приведем некоторые ключевые понятия статистики, актуальные при проведении медицинских исследований. Более подробно термины разбираются в соответствующих статьях.
Вариация
Определение. Степень рассеяния данных (значений признака) по области значений
Вероятность
Определение . Вероятность(probability) - степень возможности проявления какого - либо определённого события в тех или иных условиях.
Пример. Поясним определение термина на предложении «Вероятность выздоровления при применении лекарственного препарата Aримидекс равна 70%». Событием является «выздоровление больного», условием «больной принимает Аримидекс», степенью возможности - 70% (грубо говоря, из 100 человек, принимающих Аримидекс, выздоравливают 70).
Кумулятивная вероятность
Определение. Кумулятивная вероятность выживания (Cumulative Probability of surviving) в момент времени t - это то же самое, что доля выживших пациентов к этому моменту времени.
Пример. Если говорится, что кумулятивная вероятность выживания после проведения пятилетнего курса лечения равна 0.7, то это значит, что из рассматриваемой группы пациентов в живых осталось 70% от начального количества, а 30% умерло. Другими словами, из каждой сотни человек 30 умерло в течение первых 5 лет.
Время до события
Определение. Время до события - это время, выраженное в некоторых единицах, прошедшее с некоторого начального момента времени до наступления некоторого события.
Пояснение. В качестве единиц времени в медицинских исследованиях выступают дни, месяцы и годы.
Типичные примеры начальных моментов времени:
начало наблюдения за пациентом
проведение хирургического лечения
Типичные примеры рассматриваемых событий:
прогрессирование болезни
возникновение рецидива
смерть пациента
Выборка
Определение. Часть популяции, полученная путем отбора.
По результатам анализа выборки делают выводы о всей популяции, что правомерно только в случае, если отбор был случайным. Поскольку случайный отбор из популяции осуществить практически невозможно, следует стремиться к тому, чтобы выборка была по крайней мере репрезентативна по отношению к популяции.
Зависимые и независимые выборки
Определение. Выборки, в которые объекты исследования набирались независимо друг от друга. Альтернатива независимым выборкам - зависимые (связные, парные) выборки.
Гипотеза
Двусторонняя и односторонняя гипотезы
Сначала поясним применение термина гипотеза в статистике.
Цель большинства исследований - проверка истинности некоторого утверждения. Целью тестирования лекарственных препараторов чаще всего является проверка гипотезы, что одно лекарство эффективнее другого (например, Аримидекс эффективнее Тамоксифена).
Для предания строгости исследования, проверяемое утверждение выражают математически. Например, если А - это количество лет, которое проживёт пациент, принимающий Аримидекс, а Т -это количество лет, которое проживёт пациент, принимающий Тамоксифен, то проверяемую гипотезу можно записать как А>Т.
Определение. Гипотеза называется двусторонней (2-sided), если она состоит в равенстве двух величин.
Пример двусторонней гипотезы: A=T.
Определение. Гипотеза называется односторонней (1-sided),если она состоит в неравенстве двух величин.
Примеры односторонних гипотез:
Дихотомические (бинарные) данные
Определение. Данные, выражаемые только двумя допустимыми альтернативными значениями
Пример: Пациент «здоров» - «болен». Отек "есть" - "нет".
Доверительный интервал
Определение. Доверительный интервал (confidence interval) для некоторой величины - это диапазон вокруг значения величины, в котором находится истинное значение этой величины (с определенным уровнем доверия).
Пример. Пусть исследуемой величиной является количество пациентов в год. В среднем их количество равно 500, а 95% -доверительный интервал - (350, 900). Это означает, что, скорее всего (с вероятностью 95%), в течение года в клинику обратятся не менее 350 и не более 900 человек.
Обозначение. Очень часто используются сокращение: ДИ 95 % (CI 95%) - это доверительный интервал с уровнем доверия 95%.
Достоверность, статистическая значимость (P - уровень)
Определение. Статистическая значимость результата - это мера уверенности в его "истинности".
Любое исследование проходит на основе лишь части объектов. Исследование эффективности лекарственного препарата проводится на основе не вообще всех больных на планете, а лишь некоторой группы пациентов (провести анализ на основе всех больных просто невозможно).
Предположим, что в результате анализа был сделан некоторый вывод (например, использование в качестве адекватной терапии препарата Аримидекс в 2 раза эффективнее, чем препарата Тамоксифен).
Вопрос, который необходимо при этом задавать: "Насколько можно доверять этому результату?".
Представьте, что мы проводили исследование на основе только двух пациентов. Конечно же, в этом случае к результатам нужно относиться с опасением. Если же были обследовано большое количество больных (численное значение «большого количества» зависит от ситуации), то сделанным выводам уже можно доверять.
Так вот, степень доверия и определяется значением p-уровня (p-value).
Более высокий p- уровень соответствует более низкому уровню доверия к результатам, полученным при анализе выборки. Например, p- уровень, равный 0.05 (5%) показывает, что сделанный при анализе некоторой группы вывод является лишь случайной особенностью этих объектов с вероятностью только 5%.
Другими словами, с очень большой вероятностью (95%) вывод можно распространить на все объекты.
Во многих исследованиях 5% рассматривается как приемлемое значение p-уровня. Это значит, что если, например, p= 0.01, то результатам доверять можно, а если p=0.06, то нельзя.
Исследование
Проспективное исследование - это исследование, в котором выборки выделяются на основе исходного фактора, а в выборках анализируется некоторый результирующий фактор.
Ретроспективное исследование - это исследование, в котором выборки выделяются на основе результирующего фактора, а в выборках анализируется некоторый исходный фактор.
Пример. Исходный фактор - беременная женщина моложе/старше 20 лет. Результирующий фактор - ребёнок легче/тяжелее 2,5 кг. Анализируем, зависит ли вес ребёнка от возраста матери.
Если мы набираем 2 выборки, в одной - матери моложе 20 лет, в другой - старше, а затем анализируем массу детей в каждой группе, то это проспективное исследование.
Если мы набираем 2 выборки, в одной - матери, родившие детей легче 2,5 кг, в другой - тяжелее, а затем анализируем возраст матерей в каждой группе, то это ретроспективное исследование (естественно, такое исследование можно провести, только когда опыт закончен, т.е. все дети родились).
Исход
Определение. Клинически значимое явление, лабораторный показатель или признак, который служит объектом интереса исследователя. При проведении клинических испытаний исходы служат критериями оценки эффективности лечебного или профилактического воздействия.
Клиническая эпидемиология
Определение. Наука, позволяющая осуществлять прогнозирование того или иного исхода для каждого конкретного больного на основании изучения клинического течения болезни в аналогичных случаях с использованием строгих научных методов изучения больных для обеспечения точности прогнозов.
Когорта
Определение. Группа участников исследования, объединенных каким-либо общим признаком в момент ее формирования и исследуемых на протяжении длительного периода времени.
Контроль
Контроль исторический
Определение. Контрольная группа, сформированная и обследованная в период, предшествующий исследованию.
Контроль параллельный
Определение. Контрольная группа, формируемая одновременно с формированием основной группы.
Корреляция
Определение. Статистическая связь двух признаков (количественных или порядковых), показывающая, что большему значению одного признака в определенной части случаев соответствует большее - в случае положительной (прямой) корреляции - значение другого признака или меньшее значение - в случае отрицательной (обратной) корреляции.
Пример. Между уровнем тромбоцитов и лейкоцитов в крови пациента обнаружена значимая корреляция. Коэффициент корреляции равен 0,76.
Коэффициент риска (КР)
Определение. Коэффициент риска (hazard ratio) - это отношение вероятности наступления некоторого («нехорошего») события для первой группы объектов к вероятности наступления этого же события для второй группы объектов.
Пример. Если вероятность появления рака лёгких у некурящих равна 20%, а у курильщиков - 100%, то КР будет равен одной пятой. В этом примере первой группой объектов являются некурящие люди, второй группой - курящие, а в качестве «нехорошего» события рассматривается возникновение рака лёгких.
Очевидно, что:
1) если КР=1, то вероятность наступления события в группах одинаковая
2) если КР>1, то событие чаще происходит с объектами из первой группы, чем из второй
3) если КР<1, то событие чаще происходит с объектами из второй группы, чем из первой
Мета-анализ
Определение. С
татистический анализ, обобщающий результаты нескольких исследований, исследующих одну и ту же проблему (обычно эффективность методов лечения, профилактики, диагностики). Объединение исследований обеспечивает большую выборку для анализа и большую статистическую мощность объединяемых исследований. Используется для повышения доказательности или уверенности в заключении об эффективности исследуемого метода.
Метод Каплана - Мейера (Множительные оценки Каплана - Мейера)
Этот метод был придуман статистиками Е.Л.Капланом и Полем Мейером.
Метод используется для вычисления различных величин, связанных с временем наблюдения за пациентом. Примеры таких величин:
вероятность выздоровления в течении одного года при применении лекарственного препарата
шанс возникновения рецидива после операции в течении трёх лет после операции
кумулятивная вероятность выживания в течение пяти лет среди пациентов с раком простаты при ампутации органа
Поясним преимущества использования метода Каплана - Мейера.
Значение величин при «обычном» анализе (не использующем метод Каплана-Мейера) рассчитываются на основе разбиения рассматриваемого временного интервала на промежутки.
Например, если мы исследуем вероятность смерти пациента в течение 5 лет, то временной интервал может быть разделён как на 5 частей (менее 1 года, 1-2 года, 2-3 года, 3-4 года, 4-5 лет), так и на 10 (по полгода каждый), или на другое количество интервалов. Результаты же при разных разбиениях получатся разные.
Выбор наиболее подходящего разбиения - непростая задача.
Оценки значений величин, полученных по методу Каплана- Мейера не зависят от разбиения времени наблюдения на интервалы, а зависят только от времени жизни каждого отдельного пациента.
Поэтому исследователю проще проводить анализ, да и результаты нередко оказываются качественней результатов «обычного» анализа.
Кривая Каплана -Мейера (Kaplan - Meier curve)- это график кривой выживаемости, полученной по методу Каплана-Мейера.
Модель Кокса
Эта модель была придумана сэром Дэвидом Роксби Коксом (р.1924), известным английским статистиком, автором более 300 статей и книг.
Модель Кокса используется в ситуациях, когда исследуемые при анализе выживаемости величины зависят от функций времени. Например, вероятность возникновения рецидива через t лет (t=1,2,…), может зависеть от логарифма времени log(t).
Важным достоинством метода, предложенного Коксом, является применимость этого метода в большом количестве ситуаций (модель не накладывает жестких ограничений на природу или форму распределения вероятностей).
На основе модели Кокса можно проводить анализ (называемый анализом Кокса (Cox analysis)), результатом проведения которого является значение коэффициента риска и доверительного интервала для коэффициента риска.
Непараметрические методы статистики
Определение. Класс статистических методов, которые используются главным образом для анализа количественных данных, не образующих нормальное распределение, а также для анализа качественных данных.
Пример. Для выявления значимости различий систолического давления пациентов в зависимости от типа лечения воспользуемся непараметрическим критерием Манна-Уитни.
Признак (переменная)
Определение. Х арактеристика объекта исследования (наблюдения). Различают качественные и количественные признаки.
Рандомизация
Определение. Способ случайного распределения объектов исследования в основную и контрольную группы с использованием специальных средств (таблиц или счетчика случайных чисел, подбрасывания монеты и других способов случайного назначения номера группы включаемому наблюдению). С помощью рандомизации сводятся к минимуму различия между группами по известным и неизвестным признакам, потенциально влияющим на изучаемый исход.
Риск
Атрибутивный - дополнительный риск возникновения неблагоприятного исхода (например, заболевания) в связи с наличием определенной характеристики (фактора риска) у объекта исследования. Это часть риска развития болезни, которая связана с данным фактором риска, объясняется им и может быть устранена, если этот фактор риска устранить.
Относительный риск - отношение риска возникновения неблагоприятного состояния в одной группе к риску этого состояния в другой группе. Используется в проспективных и наблюдательных исследованиях, когда группы формируются заранее, а возникновение исследуемого состояния ещё не произошло.
Скользящий экзамен
Определение. Метод проверки устойчивости, надежности, работоспособности (валидности) статистической модели путем поочередного удаления наблюдений и пересчета модели. Чем более сходны полученные модели, тем более устойчива, надежна модель.
Событие
Определение. Клинический исход, наблюдаемый в исследовании, например возникновение осложнения, рецидива, наступление выздоровления, смерти.
Стратификация
Определение. М етод формирования выборки, при котором совокупность всех участников, соответствующих критериям включения в исследование, сначала разделяется на группы (страты) на основе одной или нескольких характеристик (обычно пола, возраста), потенциально влияющих на изучаемый исход, а затем из каждой из этих групп (страт) независимо проводится набор участников в экспериментальную и контрольную группы. Это позволяет исследователю соблюдать баланс важных характеристик между экспериментальной и контрольной группами.
Таблица сопряженности
Определение. Таблица абсолютных частот (количества) наблюдений, столбцы которой соответствуют значениям одного признака, а строки - значениям другого признака (в случае двумерной таблицы сопряженности). Значения абсолютных частот располагаются в клетках на пересечении рядов и колонок.
Приведем пример таблицы сопряженности. Операция на аневризме была сделана 194 пациентам. Известен показатель выраженности отека у пациентов перед операцией.
|
Отек\ Исход | |||
|---|---|---|---|
| нет отека | 20 | 6 | 26 |
| умеренный отек | 27 | 15 | 42 |
| выраженный отек | 8 | 21 | 29 |
| m j | 55 | 42 | 194 |
Таким образом, из 26 пациентов, не имеющих отека, после операции выжило 20 пациентов, умерло - 6 пациентов. Из 42 пациентов, имеющих умеренный отек выжило 27 пациентов, умерло - 15 и т.д.
Критерий хи-квадрат для таблиц сопряженности
Для определения значимости (достоверности) различий одного признака в зависимости от другого (например, исхода операции в зависимости от выраженности отека) применяется критерий хи-квадрат для таблиц сопряженности:

Шанс
Пусть вероятность некоторого события равна p. Тогда вероятность того, что событие не произойдёт равна 1-p.
Например, если вероятность того, что больной останется жив спустя пять лет равна 0.8 (80%), то вероятность того, что он за этот временной промежуток умрёт равна 0.2 (20%).
Определение. Шанс - это отношение вероятности того, что события произойдёт к вероятности того, что событие не произойдёт.
Пример. В нашем примере (про больного) шанс равен 4, так как 0.8/0.2=4
Таким образом, вероятность выздоровления в 4 раза больше вероятности смерти.
Интерпретация значения величины.
1) Если Шанс=1, то вероятность наступления события равна вероятности того, что событие не произойдёт;
2) если Шанс >1, то вероятность наступления события больше вероятности того, что событие не произойдёт;
3) если Шанс <1, то вероятность наступления события меньше вероятности того, что событие не произойдёт.
Отношение шансов
Определение. Отношение шансов (odds ratio) - это отношение шансов для первой группы объектов к отношению шансов для второй группы объектов.
Пример. Допустим, что некоторое лечение проходят и мужчины, и женщины.
Вероятность того, что больной мужского пола останется жив спустя пять лет равна 0.6 (60%); вероятность того, что он за этот временной промежуток умрёт равна 0.4 (40%).
Аналогичные вероятности для женщин равны 0.8 и 0.2.
Отношение шансов в этом примере равно
Интерпретация значения величины.
1) Если отношение шансов =1, то шанс для первой группы равен шансу для второй группы
2) Если отношение шансов >1, то шанс для первой группы больше шанса для второй группы
3) Если отношение шансов <1, то шанс для первой группы меньше шанса для второй группы
Проверка гипотез проводится с помощью статистического анализа. Статистическую значимость находят с помощью Р-значения, которое соответствует вероятности данного события при предположении, что некоторое утверждение (нулевая гипотеза) истинно. Если Р-значение меньше заданного уровня статистической значимости (обычно это 0,05), экспериментатор может смело заключить, что нулевая гипотеза неверна, и перейти к рассмотрению альтернативной гипотезы. С помощью t-критерия Стьюдента можно вычислить Р-значение и определить значимость для двух наборов данных.
Шаги
Часть 1
Постановка эксперимента- Нулевая гипотеза (H 0) обычно утверждает, что между двумя наборами данных нет разницы. Например: те ученики, которые читают материал перед занятиями, не получают более высокие оценки.
- Альтернативная гипотеза (H a) противоположна нулевой гипотезе и представляет собой утверждение, которое нужно подтвердить с помощью экспериментальных данных. Например: те ученики, которые читают материал перед занятиями, получают более высокие оценки.
-
Установите уровень значимости, чтобы определить, насколько распределение данных должно отличаться от обычного, чтобы это можно было считать значимым результатом. Уровень значимости (его называют также α {\displaystyle \alpha } -уровнем) - это порог, который вы определяете для статистической значимости. Если Р-значение меньше уровня значимости или равно ему, данные считаются статистически значимыми.
- Как правило, уровень значимости (значение α {\displaystyle \alpha } ) принимается равным 0,05, и в этом случае вероятность обнаружения случайной разницы между разными наборами данных составляет всего лишь 5%.
- Чем выше уровень значимости (и, соответственно, меньше Р-значение), тем достовернее результаты.
- Если вы хотите получить более достоверные результаты, понизьте Р-значение до 0,01. Как правило, более низкие Р-значения используются в производстве, когда необходимо выявить брак в продукции. В этом случае требуется высокая достоверность, чтобы быть уверенным, что все детали работают так, как положено.
- Для большинства экспериментов с гипотезами достаточно принять уровень значимости равным 0,05.
-
Решите, какой критерий вы будете использовать: односторонний или двусторонний. Одно из предположений в t-критерии Стьюдента гласит, что данные распределены нормальным образом. Нормальное распределение представляет собой колоколообразную кривую с максимальным количеством результатов посередине кривой. t-критерий Стьюдента - это математический метод проверки данных, который позволяет установить, выпадают ли данные за пределы нормального распределения (больше, меньше, либо в “хвостах” кривой).
- Если вы не уверены, находятся ли данные выше или ниже контрольной группы значений, используйте двусторонний критерий. Это позволит вам определить значимость в обоих направлениях.
- Если вы знаете, в каком направлении данные могут выйти за пределы нормального распределения, используйте односторонний критерий. В приведенном выше примере мы ожидаем, что оценки студентов повысятся, поэтому можно использовать односторонний критерий.
-
Определите объем выборки с помощью статистической мощности. Статистическая мощность исследования - это вероятность того, что при данном объеме выборки получится ожидаемый результат. Распространенный порог мощности (или β) составляет 80%. Анализ статистической мощности без каких-либо предварительных данных может представлять определенные сложности, поскольку требуется некоторая информация об ожидаемых средних значениях в каждой группе данных и об их стандартных отклонениях. Используйте для анализа статистической мощности онлайн-калькулятор, чтобы определить оптимальный объем выборки для ваших данных.
- Обычно ученые проводят небольшое пробное исследование, которое позволяет получить данные для анализа статистической мощности и определить объем выборки, необходимый для более расширенного и полного исследования.
- Если у вас нет возможности провести пробное исследование, постарайтесь на основании литературных данных и результатов других людей оценить возможные средние значения. Возможно, это поможет вам определить оптимальный объем выборки.
Часть 2
Вычислите стандартное отклонение-
Запишите формулу для стандартного отклонения. Стандартное отклонение показывает, насколько велик разброс данных. Оно позволяет заключить, насколько близки данные, полученные на определенной выборке. На первый взгляд формула кажется довольно сложной, но приведенные ниже объяснения помогут понять ее. Формула имеет следующий вид: s = √∑((x i – µ) 2 /(N – 1)).
- s - стандартное отклонение;
- знак ∑ указывает на то, что следует сложить все полученные на выборке данные;
- x i соответствует i-му значению, то есть отдельному полученному результату;
- µ - это среднее значение для данной группы;
- N - общее число данных в выборке.
-
Найдите среднее значение в каждой группе. Чтобы вычислить стандартное отклонение, необходимо сначала найти среднее значение для каждой исследуемой группы. Среднее значение обозначается греческой буквой µ (мю). Чтобы найти среднее, просто сложите все полученные значения и поделите их на количество данных (объем выборки).
- Например, чтобы найти среднюю оценку в группе тех учеников, которые изучают материал перед занятиями, рассмотрим небольшой набор данных. Для простоты используем набор из пяти точек: 90, 91, 85, 83 и 94.
- Сложим вместе все значения: 90 + 91 + 85 + 83 + 94 = 443.
- Поделим сумму на число значений, N = 5: 443/5 = 88,6.
- Таким образом, среднее значение для данной группы составляет 88,6.
-
Вычтите из среднего каждое полученное значение. Следующий шаг заключается в вычислении разницы (x i – µ). Для этого следует вычесть из найденной средней величины каждое полученное значение. В нашем примере необходимо найти пять разностей:
- (90 – 88,6), (91- 88,6), (85 – 88,6), (83 – 88,6) и (94 – 88,6).
- В результате получаем следующие значения: 1,4, 2,4, -3,6, -5,6 и 5,4.
-
Возведите в квадрат каждую полученную величину и сложите их вместе. Каждую из только что найденных величин следует возвести в квадрат. На этом шаге исчезнут все отрицательные значения. Если после данного шага у вас останутся отрицательные числа, значит, вы забыли возвести их в квадрат.
- Для нашего примера получаем 1,96, 5,76, 12,96, 31,36 и 29,16.
- Складываем полученные значения: 1,96 + 5,76 + 12,96 + 31,36 + 29,16 = 81,2.
-
Поделите на объем выборки минус 1. В формуле сумма делится на N – 1 из-за того, что мы не учитываем генеральную совокупность, а берем для оценки выборку из числа всех студентов.
- Вычитаем: N – 1 = 5 – 1 = 4
- Делим: 81,2/4 = 20,3
-
Извлеките квадратный корень. После того как вы поделите сумму на объем выборки минус один, извлеките из найденного значения квадратный корень. Это последний шаг в вычислении стандартного отклонения. Есть статистические программы, которые после введения начальных данных производят все необходимые вычисления.
- В нашем примере стандартное отклонение оценок тех учеников, которые читают материал перед занятиями, составляет s =√20,3 = 4,51.
Часть 3
Определите значимость-
Рассчитайте дисперсию между двумя группами данных. До этого шага мы рассматривали пример лишь для одной группы данных. Если вы хотите сравнить две группы, очевидно, следует взять данные для обеих групп. Вычислите стандартное отклонение для второй группы данных, а затем найдите дисперсию между двумя экспериментальными группами. Дисперсия вычисляется по следующей формуле: s d = √((s 1 /N 1) + (s 2 /N 2)).
Определите свою гипотезу. Первый шаг при оценке статистической значимости состоит в том, чтобы выбрать вопрос, ответ на который вы хотите получить, и сформулировать гипотезу. Гипотеза - это утверждение об экспериментальных данных, их распределении и свойствах. Для любого эксперимента существует как нулевая, так и альтернативная гипотеза. Вообще говоря, вам придется сравнивать два набора данных, чтобы определить, схожи они или различны.
В любой научно-практической ситуации эксперимента (обследования) исследователи могут исследовать не всех людей (генеральную совокупность, популяцию), а только определенную выборку. Например, даже если мы исследуем относительно небольшую группу людей, например страдающих определенной болезнью, то и в этом случае весьма маловероятно, что у нас имеются соответствующие ресурсы или необходимость тестировать каждого больного. Вместо этого обычно тестируют выборку из популяции, поскольку это удобнее и занимает меньше времени. В таком случае, откуда нам известно, что результаты, полученные на выборке, представляют всю группу? Или, если использовать профессиональную терминологию, можем ли мы быть уверены, что наше исследование правильно описывает всю популяцию , выборку из которой мы использовали?
Чтобы ответить на этот вопрос, необходимо определить статистическую значимость результатов тестирования. Статистическая значимость {Significant level , сокращенно Sig.), или /7-уровень значимости (p-level) - это вероятность того, что данный результат правильно представляет популяцию, выборка из которой исследовалась. Отметим, что это только вероятность - невозможно с абсолютной гарантией утверждать, что данное исследование правильно описывает всю популяцию. В лучшем случае по уровню значимости можно лишь заключить, что это весьма вероятно. Таким образом, неизбежно встает следующий вопрос: каким должен быть уровень значимости, чтобы можно было считать данный результат правильной характеристикой популяции?
Например, при каком значении вероятности вы готовы сказать, что таких шансов достаточно, чтобы рискнуть? Если шансы будут 10 из 100 или 50 из 100? А что если эта вероятность выше? Что можно сказать о таких шансах, как 90 из 100, 95 из 100 или 98 из 100? Для ситуации, связанной с риском, этот выбор довольно проблематичен, ибо зависит от личностных особенностей человека.
В психологии же традиционно считается, что 95 или более шансов из 100 означают, что вероятность правильности результатов достаточна высока для того, чтобы их можно было распространить на всю популяцию. Эта цифра установлена в процессе научно-практической деятельности - нет никакого закона, согласно которому следует выбрать в качестве ориентира именно ее (и действительно, в других науках иногда выбирают другие значения уровня значимости).
В психологии оперируют этой вероятностью несколько необычным образом. Вместо вероятности того, что выборка представляет популяцию, указывается вероятность того, что выборка не представляет популяцию. Иначе говоря, это вероятность того, что обнаруженная связь или различия носят случайный характер и не являются свойством совокупности. Таким образом, вместо того чтобы утверждать, что результаты исследования правильны с вероятностью 95 из 100, психологи говорят, что имеется 5 шансов из 100, что результаты неправильны (точно так же 40 шансов из 100 в пользу правильности результатов означают 60 шансов из 100 в пользу их неправильности). Значение вероятности иногда выражают в процентах, но чаще его записывают в виде десятичной дроби. Например, 10 шансов из 100 представляют в виде десятичной дроби 0,1; 5 из 100 записывается как 0,05; 1 из 100 - 0,01. При такой форме записи граничным значением является 0,05. Чтобы результат считался правильным, его уровень значимости должен быть ниже этого числа (вы помните, что это вероятность того, что результат неправильно описывает популяцию). Чтобы покончить с терминологией, добавим, что «вероятность неправильности результата» (которую правильнее называть уровнем значимости) обычно обозначается латинской буквой р. В описание результатов эксперимента обычно включают резюмирующий вывод, такой как «результаты оказались значимыми на уровне достоверности (р (р) менее 0,05 (т.е. меньше 5%).
Таким образом, уровень значимости (р ) указывает на вероятность того, что результаты не представляют популяцию. По традиции в психологии считается, что результаты достоверно отражают общую картину, если значение р меньше 0,05 (т.е. 5%). Тем не менее это лишь вероятностное утверждение, а вовсе не безусловная гарантия. В некоторых случаях этот вывод может оказаться неправильным. На самом деле, мы можем подсчитать, как часто это может случиться, если посмотрим на величину уровня значимости. При уровне значимости 0,05 в 5 из 100 случаев результаты, вероятно, неверны. 11а первый взгляд кажется, что это не слишком часто, однако если задуматься, то 5 шансов из 100 - это то же самое, что 1 из 20. Иначе говоря, в одном из каждых 20 случаев результат окажется неверным. Такие шансы кажутся не особенно благоприятными, и исследователи должны остерегаться совершения ошибки первого рода. Так называют ошибку, которая возникает, когда исследователи считают, что обнаружили реальные результаты, а на самом деле их нет. Противоположные ошибки, состоящие в том, что исследователи считают, будто они не обнаружили результата, а на самом деле он есть, называют ошибками второго рода.
Эти ошибки возникают потому, что нельзя исключить возможность неправильности проведенного статистического анализа. Вероятность ошибки зависит от уровня статистической значимости результатов. Мы уже отмечали, что, для того чтобы результат считался правильным, уровень значимости должен быть ниже 0,05. Разумеется, некоторые результаты имеют более низкий уровень, и нередко можно встретить результаты с такими низкими /?, как 0,001 (значение 0,001 говорит о том, что результаты могут быть неправильными с вероятностью 1 из 1000). Чем меньше значение р, тем тверже наша уверенность в правильности результатов .
В табл. 7.2 приведена традиционная интерпретация уровней значимости о возможности статистического вывода и обосновании решения о наличии связи (различий).
Таблица 7.2
Традиционная интерпретация уровней значимости, используемых в психологии
На основе опыта практических исследований рекомендуется: чтобы по возможности избежать ошибок первого и второго рода, при ответственных выводах следует принимать решения о наличии различий (связи), ориентируясь на уровень р п признака.
Статистический критерий (Statistical Test) - это инструмент определения уровня статистической значимости. Это решающее правило, обеспечивающее принятие истинной и отклонение ложной гипотезы с высокой вероятностью .
Статистические критерии обозначают также метод расчета определенного числа и само это число. Все критерии используются с одной главной целью: определить уровень значимости анализируемых с их помощью данных (т.е. вероятность того, что эти данные отражают истинный эффект, правильно представляющий популяцию, из которой сформирована выборка).
Некоторые критерии можно использовать только для нормально распределенных данных (и если признак измерен по интервальной шкале) - эти критерии обычно называют параметрическими. С помощью других критериев можно анализировать данные практически с любым законом распределения - их называют непараметрическими.
Параметрические критерии - критерии, включающие в формулу расчета параметры распределения, т.е. средние и дисперсии (^-критерий Стью- дента, F-критерий Фишера и др.).
Непараметрические критерии - критерии, не включающие в формулу расчета параметров распределения и основанные на оперировании частотами или рангами (критерий Q Розенбаума, критерий U Манна - Уитни
Например, когда мы говорим, что достоверность различий определялась по ^-критерию Стьюдента, то имеется в виду, что использовался метод ^-критерия Стьюдента для расчета эмпирического значения, которое затем сравнивается с табличным (критическим) значением.
По соотношению эмпирического (нами вычисленного) и критического значений критерия (табличного) мы можем судить о том, подтверждается или опровергается наша гипотеза. В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, хотя есть критерии (например, критерий Манна - Уитни или критерий знаков), в которых мы должны придерживаться противоположного правила.
В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как п. По специальной таблице мы определяем, какому уровню статистической значимости различий соответствует данная эмпирическая величина. В большинстве случаев одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в исследуемой выборке (п ) или от так называемого количества степеней свободы , которое обозначается как v (г>) или как df (иногда d).
Зная п или число степеней свободы, мы по специальным таблицам (основные из них приводятся в приложении 5) можем определить критические значения критерия и сопоставить с ними полученное эмпирическое значение. Обычно это записывается так: «при п = 22 критические значения критерия составляют t St = 2,07» или «при v (d ) = 2 критические значения критерия Стьюдента составляют = 4,30» и т.н.
Обычно предпочтение оказывается все же параметрическим критериям, и мы придерживаемся этой позиции. Считается, что они более надежны, и с их помощью можно получить больше информации и провести более глубокий анализ. Что касается сложности математических вычислений, то при использовании компьютерных программ эта сложность исчезает (но появляются некоторые другие, впрочем, вполне преодолимые).
- В настоящем учебнике мы подробно не рассматриваем проблему статистических
- гипотез (нулевой - Я0 и альтернативной - Нj) и принимаемые статистические решения,поскольку студенты-психологи изучают это отдельно по дисциплине «Математическиеметоды в психологии». Кроме того, необходимо отметить, что при оформлении исследовательского отчета (курсовой или дипломной работы, публикации) статистические гипотезыи статистические решения, как правило, не приводятся. Обычно при описании результатовуказывают критерий, приводят необходимые описательные статистики (средние, сигмы,коэффициенты корреляции и т.д.), эмпирические значения критериев, степени свободыи обязательно р-уровень значимости. Затем формулируют содержательный вывод в отношении проверяемой гипотезы с указанием (обычно в виде неравенства) достигнутого илинедостигнутого уровня значимости.
ПЛАТНАЯ ФУНКЦИЯ. Функция статистической значимости доступна только в некоторых тарифных планах. Проверьте, есть ли она в .
Можно узнать, есть ли статистически значимые отличия в ответах, полученных от разных групп респондентов на вопросы в опросе. Для работы с функцией статистической значимости в SurveyMonkey необходимо:
- Включить функцию статистической значимости при добавлении правила сравнения к вопросу в Вашем опросе. Выбрать группы респондентов для сравнения, чтобы отсортировать результаты опроса по группам для наглядного сравнения.
- Изучить таблицы с данными по вопросам Вашего опроса, чтобы выявить наличие статистически значимых отличий в ответах, полученных от различных групп респондентов.
Просмотр статистической значимости
Выполнив нижеописанные действия, Вы сможете создать опрос, отображающий статистическую значимость.
1. Добавьте в опрос вопросы закрытого типа
Для того, чтобы отобразить статистическую значимость во время анализа результатов, Вам понадобится применить правило сравнения к какому-либо вопросу из Вашего опроса.
Применить правило сравнения и вычислить статистическую значимость в ответах можно в том случае, если в схеме опроса Вы используете один из следующих типов вопросов:
Необходимо убедиться в том, что предлагаемые варианты ответа можно разделить на полноценные группы. Варианты ответа, выбираемые Вами для сравнения при создании правила сравнения, будут использованы для организации данных в перекрестные таблицы в рамках всего опроса.
2. Соберите ответы
После завершения составления опроса создайте коллектор для его рассылки. Существует несколько способов .
Вам необходимо получить не менее 30 ответов по каждому варианту ответа, который Вы планируете использовать в своем правиле сравнения, чтобы активировать и просмотреть статистическую значимость.
Пример опроса
Вы хотите узнать, довольны ли мужчины Вашей продукцией значительно больше, чем женщины.
- Добавьте в опрос два вопроса с множественными вариантами ответа:
Какой Ваш пол? (мужской, женский)
Довольны ли Вы или недовольны нашим продуктом? (доволен(-льна), недоволен(-льна)) - Убедитесь, что не менее 30 респондентов выбрали вариант ответа «мужской» на вопрос о поле, А ТАКЖЕ не менее 30 респондентов в качестве своего пола выбрали вариант «женский».
- Добавьте правило сравнения к вопросу "Какой Ваш пол?" и выберите оба варианта ответа как Ваши группы.
- Используйте таблицу данных ниже диаграммы вопроса "Довольны ли Вы или недовольны нашим продуктом?" , чтобы узнать, показывают ли какие-нибудь варианты ответа статистически значимое отличие
Что такое статистически значимое отличие?
Статистически значимое отличие означает, что с помощью статистического анализа установлено наличие существенных отличий между ответами одной группы респондентов и ответами другой группы. Статистическая значимость означает, что полученные цифры достоверно отличаются. Такие знания в значительной мере помогут Вам при анализе данных. Тем не менее, важность полученных результатов определяете Вы. Именно Вы решаете, как толковать результаты опросов и какие меры следует принять на их основе.
Например, Вы получаете больше претензий от покупателей женского пола, чем от покупателей-мужчин. Как определить, является ли такое отличие реальным и требуется ли в связи с этим принять меры? Одним из отличных способов проверить Ваши наблюдения является проведение опроса, который покажет Вам, действительно ли Вашим товаром в значительно большей мере довольны покупатели-мужчины. С помощью статистической формулы предлагаемая нами функция статистической значимости предоставит Вам возможность определить, действительно ли Ваш товар гораздо больше нравится мужчинам, чем женщинам. Это позволит Вам принять меры, основываясь на факты, а не на догадки.
Статистически значимое отличие
Если полученные Вами результаты выделены в таблице данных, это означает, что две группы респондентов значительно отличаются друг от друга. Термин «значительно» не означает, что полученные цифры имеют какую-то особую важность или значение, а лишь то, что между ними есть статистическая разница.
Отсутствие статистически значимого отличия
Если полученные Вами результаты не выделены в соответствующей таблице данных, это означает, что, несмотря на возможную разницу в двух сравниваемых цифрах, между ними нет статистической разницы.
Ответы без статистически значимых отличий демонстрируют, что между двумя сравниваемыми элементами нет значительной разницы при используемом Вами объеме выборки, однако это не обязательно означает, что они не имеют значения. Возможно, увеличив объем выборки, Вы сможете выявить статистически значимое отличие.
Объем выборки
Если у Вас очень малый объем выборки, значительными будут только очень большие отличия между двумя группами. Если у Вас очень большой объем выборки, как небольшие, так и большие отличия будут учтены как значительные.
Тем не менее, если две цифры являются статистически различными, это не означает, что разница между результатами имеет для Вас какое-либо практическое значение. Вам придется самим решить, какие именно отличия значимы для Вашего опроса.
Вычисление статистической значимости
Мы вычисляем статистическую значимость, используя стандартный уровень доверия 95 %. Если вариант ответа отображается как статистически значимый, это означает, что только благодаря случайности либо из-за ошибки выборки отличие между двумя группами имеет место с вероятностью менее 5 % (часто отображается в виде: p<0,05).
Для вычисления статистически значимых отличий между группами мы используем следующие формулы:
|
Параметр |
Описание | |
|---|---|---|
| a1 | Доля участников из первой группы, ответивших на вопрос определенным образом, умноженная на объем выборки данной группы. | |
| b1 | Доля участников из второй группы, ответивших на вопрос определенным образом, умноженная на объем выборки данной группы. | |
| Доля объединенной выборки (p) | Совокупность двух долей из обеих групп. | |
| Стандартная ошибка (SE) | Показатель того, насколько Ваша доля отличается от действительной доли. Меньшее значение означает, что доля близка к действительной доле, большее значение означает, что доля существенно отличается от действительной доли. | |
| Тестовый статистический показатель (t) | Тестовый статистический показатель. Количество значений стандартного отклонения, на которое данное значение отличается от среднего значения. | |
| Статистическая значимость | Если абсолютная величина тестового статистического показателя превышает 1,96* стандартных отклонений от среднего значения, это считается статистически значимым отличием. |
*1,96 является значением, применяемым для уровня доверия 95 %, поскольку 95 % диапазона, обрабатываемого функцией t-распределения Стьюдента, лежит в пределах 1,96 стандартного отклонения от среднего значения.
Пример вычислений
Продолжая пример, используемый выше, давайте выясним, действительно ли процент мужчин, заявляющих о том, что они довольны Вашим товаром, значительно выше процента женщин.
Допустим, в Вашем опросе приняло участие 1000 мужчин и 1000 женщин, и в результате опроса оказалось, что 70 % мужчин и 65 % женщин утверждают, что они довольны Вашим товаром. Является ли показатель на уровне 70 % значительно выше показателя на уровне 65 %?
Подставьте следующие данные из опроса в предлагаемые формулы:
- p1 (% мужчин, довольных продуктом) = 0,7
- p2 (% женщин, довольных продуктом) = 0,65
- n1 (количество опрошенных мужчин) = 1000
- n2 (количество опрошенных женщин) = 1000
Поскольку абсолютная величина тестового статистического показателя больше чем 1,96, это означает, что отличие между мужчинами и женщинами является значительным. По сравнению с женщинами мужчины с большей долей вероятности будут довольны Вашим продуктом.
Скрытие статистической значимости
Как скрыть статистическую значимость для всех вопросов
- Нажмите стрелку «вниз» справа от правила сравнения на левой боковой панели.
- Выберите пункт Редактировать правило .
- Отключите функцию Показать статистическую значимость с помощью переключателя.
- Нажмите кнопку Применить .
Чтобы скрыть статистическую значимость для одного вопроса, необходимо:
- Нажмите кнопку Настроить над диаграммой данного вопроса.
- Откройте вкладку Параметры отображения .
- Снимите флажок напротив пункта Статистическая значимость .
- Нажмите кнопку Сохранить .
Параметр отображения автоматически активируется при включении отображения статистической значимости. Если снять флажок этого параметра отображения, отображение статистической значимости также будет отключено.
Включите функцию статистической значимости при добавлении правила сравнения к вопросу в Вашем опросе. Изучите таблицы с данными по вопросам Вашего опроса, чтобы выявить наличие статистически значимых отличий в ответах, полученных от различных групп респондентов.
Статистика давно уже стала неотъемлемой частью жизни. С ней люди сталкиваются всюду. На основе статистики делаются выводы о том, где и какие заболевания распространены, что более востребовано в конкретном регионе или среди определенного слоя населения. На основываются даже построения политических программ кандидатов в органы власти. Ими же пользуются и торговые сети при закупке товаров, а производители руководствуются этими данными в своих предложениях.
Статистика играет важную роль в жизни общества и влияет на каждого его отдельного члена даже в мелочах. Например, если по , большинство людей предпочитают темные цвета в одежде в конкретном городе или регионе, то найти яркий желтый плащ с цветочным принтом в местных торговых точках будет крайне затруднительно. Но из каких величин складываются эти данные, оказывающие такое влияние? К примеру, что представляет собой «статистическая значимость»? Что именно понимается под этим определением?
Что это?
Статистика как наука складывается из сочетания разных величин и понятий. Одним из них и является понятие «статистическая значимость». Так называется значение переменных величин, вероятность появления других показателей в которых ничтожно мала.
К примеру, 9 из 10 человек надевают на ноги резиновую обувь во время утренней прогулки за грибами в осенний лес после дождливой ночи. Вероятность того что в какой-то момент 8 из них обуются в парусиновые мокасины - ничтожно мала. Таким образом, в данном конкретном примере число 9 является величиной, которая и называется «статистическая значимость».
Соответственно, если развивать далее приведенный практический пример, обувные магазины закупают к концу летнего сезона резиновые сапожки в большом количестве, чем в другое время года. Так, величина статистического значения оказывает влияние на обычную жизнь.
Разумеется, в сложных подсчетах, допустим, при прогнозе распространения вирусов, учитывается большое число переменных. Но сама суть определения значимого показателя статистических данных - аналогична, вне зависимости от сложности подсчетов и количества непостоянных величин.
Как вычисляют?
Используются при вычислении значения показателя «статистическая значимость» уравнения. То есть можно утверждать, что в этом случае все решает математика. Самым простым вариантом вычисления является цепь математических действий, в которой участвуют следующие параметры:
- два типа результатов, полученных при опросах или изучении объективных данных, к примеру, сумм на которые совершаются покупки, обозначаемые а и b;
- показатель для обеих групп - n;
- значение доли объединенной выборки - p;
- понятие «стандартная ошибка» - SE.
Следующим этапом определяется общий тестовый показатель - t, его значение сравнивается с числом 1,96. 1,96 - это усредненное значение, передающее диапазон в 95 %, согласно функции t-распределения Стьюдента.
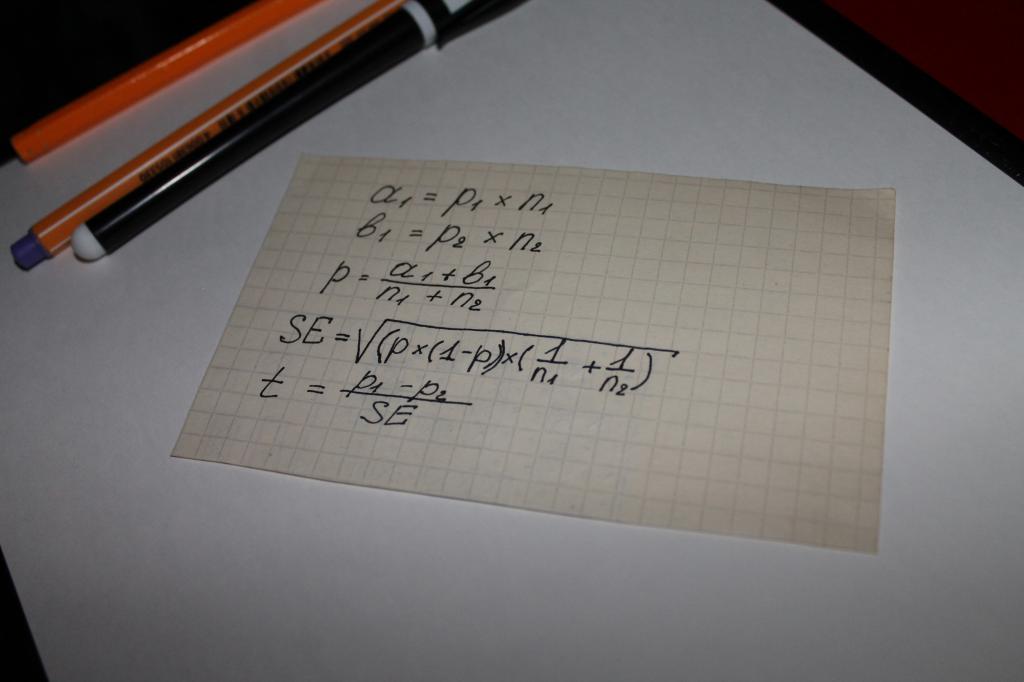
Часто возникает вопрос о том, в чем отличие значений n и p. Этот нюанс просто прояснить при помощи примера. Допустим, вычисляется статистическая значимость лояльности к какому-либо товару или бренду мужчин и женщин.
В этом случае за буквенными обозначениями будет стоять следующее:
- n - число опрошенных;
- p - число довольных продуктом.
Численность опрошенных женщин в этом случае будет обозначено, как n1. Соответственно, мужчин - n2. То же значение будут иметь цифры «1» и «2» у символа p.
Сравнение тестового показателя с усредненными значениями расчетных таблиц Стьюдента и становится тем, что называется «статистическая значимость».
Что понимается под проверкой?
Результаты любого математического вычисления всегда можно проверить, этому учат детей еще в начальных классах. Логично предположить, что раз статистические показатели определяются при помощи цепи вычислений, то и проверяются.
Однако проверка статистической значимости - не только математика. Статистика имеет дело с большим количеством переменных величин и различных вероятностей, далеко не всегда поддающихся расчету. То есть если вернутся к приведенному в начале статьи примеру с резиновой обувью, то логичное построение статистических данных, на которые станут опираться закупщики товаров для магазинов, может быть нарушено сухой и жаркой погодой, которая не типична для осени. В результате этого явления число людей, приобретающих резиновые сапоги, снизится, а торговые точки потерпят убытки. Предусмотреть погодную аномалию математическая формула, разумеется, не в состоянии. Этот момент называется - «ошибка».

Вот как раз вероятность таких ошибок и учитывает проверка уровня вычисленной значимости. В ней учитываются как вычисленные показатели, так и принятые уровни значимости, а также величины, условно называемые гипотезами.
Что такое уровень значимости?
Понятие «уровень» входит в основные критерии статистической значимости. Используется оно в прикладной и практической статистике. Это своего рода величина, учитывающая вероятность возможных отклонений или ошибок.
Уровень основывается на выявлении различий в готовых выборках, позволяет установить их существенность либо же, наоборот, случайность. У этого понятия есть не только цифровые значения, но и их своеобразные расшифровки. Они объясняют то, как нужно понимать значение, а сам уровень определяется сравнением результата с усредненным индексом, это и выявляет степень достоверности различий.

Таким образом, можно представить понятие уровня просто - это показатель допустимой, вероятной погрешности или же ошибки в сделанных из полученных статистических данных выводах.
Какие уровни значимости используются?
Статистическая значимость коэффициентов вероятности допущенной ошибки на практике отталкивается от трех базовых уровней.
Первым уровнем считается порог, при котором значение равно 5 %. То есть вероятность погрешности не превышает уровня значимости в 5 %. Это означает, что уверенность в безупречности и безошибочности выводов, сделанных на основе данных статистических исследований, составляет 95 %.
Вторым уровнем является порог в 1 %. Соответственно, эта цифра означает, что руководствоваться полученными при статистических расчетах данными можно с уверенностью в 99 %.
Третий уровень - 0,1 %. При таком значении вероятность наличия ошибки равна доле процента, то есть погрешности практически исключаются.
Что такое гипотеза в статистике?
Ошибки как понятие разделяются по двум направлениям, касающимся принятия или же отклонения нулевой гипотезы. Гипотеза - это понятие, за которым скрывается, согласно определению, набор иных данных или же утверждений. То есть описание вероятностного распределения чего-либо, относящегося к предмету статистического учета.

Гипотез при простых расчетах бывает две - нулевая и альтернативная. Разница между ними в том, что нулевая гипотеза берет за основу представление об отсутствии принципиальных отличий между участвующими в определении статистической значимости выборками, а альтернативная ей полностью противоположна. То есть альтернативная гипотеза основана на наличии весомой разницы в данных выборок.
Какими бывают ошибки?
Ошибки как понятие в статистике находятся в прямой зависимости от принятия за истинную той или иной гипотезы. Их можно разделить на два направления или же типа:
- первый тип обусловлен принятием нулевой гипотезы, оказавшейся неверной;
- второй - вызван следованием альтернативной.

Первый тип ошибок называется ложноположительным и встречается достаточно часто во всех сферах, где используются статистические данные. Соответственно, ошибка второго типа называется ложноотрицательной.
Для чего нужна регрессия в статистике?
Статистическая значимость регрессии в том, что с ее помощью можно установить, насколько соответствует реальности вычисленная на основе данных модель различных зависимостей; позволяет выявить достаточность или же нехватку факторов для учета и выводов.
Определяется регрессивное значение с помощью сравнения результатов с перечисленными в таблицах Фишера данными. Или же при помощи дисперсионного анализа. Важное значение показатели регрессии имеют при сложных статистических исследованиях и расчетах, в которых участвует большое количество переменных величин, случайных данных и вероятных изменений.
 Education in Great Britain - Образование в Великобритании (5), устная тема по английскому языку с переводом
Education in Great Britain - Образование в Великобритании (5), устная тема по английскому языку с переводом Иван петрович павлов, открытия
Иван петрович павлов, открытия Мария значение имени - характер и судьба
Мария значение имени - характер и судьба