Критерий дарбина уотсона может принимать значения. Методы определения автокорреляции остатков. Критерий Дарбина-Уотсона для панельных данных
Критерий Дарбина - Уотсона
Одним из самых простых, а потому широко применяемых на практике критериев проверки на наличие (отсутствие) автокорреляции является критерий Дарбина - Уотсона
и .
Критерий h Дарбина применяется для выявления автокорреляции остатков в модели с распределёнными лагами:

где n - число наблюдений в модели;
V - стандартная ошибка лаговой результативной переменной.
При увеличении объёма выборки распределение h -статистики стремится к нормальному с нулевым математическим ожиданием и дисперсией, равной 1. Поэтому гипотеза об отсутствии автокорреляции остатков отвергается, если фактическое значение h -статистики оказывается больше, чем критическое значение нормального распределения.
Критерий Дарбина-Уотсона для панельных данных
Для панельных данных используется немного видоизменённый критерий Дарбина-Уотсона:

В отличие от критерия Дарбина-Уотсона для временных рядов в этом случае область неопределенности является очень узкой, в особенности, для панелей с большим количеством индивидуумов.
- Методы исключения автокорреляции (отклонений от тренда, последовательных разностей, включения фактора времени).
Сущность всех методов исключения тенденции заключается в том, чтобы устранить воздействие фактора времени на формирование уравнений временного ряда. Основные методы делят на 2 группы:
Основанные на преобразовании уровней ряда в новые переменные, не содержащие тенденции. Полученные переменные используем далее для анализа взаимосвязи изучаемых временных рядов. Эти методы предполагают устранение трендовой компоненты Т из каждого уровня временного ряда. 1.Метод последовательных разностей. 2.Метод отклонения от трендов.
Основанные на изучении взаимосвязей исходных уровней временных рядов при исключении воздействия фактора времени на зависимую и независимые переменные модели: включение в модель регрессии фактора времени.
Критерий Дарбина-Уотсона (или статистика DW).
Это наиболее известный критерий обнаружения автокорреляции первого порядка. Статистика Дарбина - Уотсона приводится во всех специальных компьютерных программах как одна из важнейших характеристик качества регрессионной модели.
Сначала по построенному эмпирическому уравнению регрессии
определяются значения отклонений Рассчитывается
статистика

0 положительная автокорреляция;
d t зона неопределенности;
d u - d u - автокорреляция отсутствует;
- 4 - d u
- 4 - d/ отрицательная автокорреляция.
Можно показать, что статистика (2.64) тесно связана с коэффициентом автокорреляции первого порядка:

Связь выражается формулой:
![]()
Отсюда вытекает смысл статистического анализа автокорреляции. Поскольку значения г изменяются от -1 до + 1, DW изменяется от 0 до 4. Когда автокорреляция отсутствует, коэффициент автокорреляции равен нулю, и статистика DW равна 2. Статистика DW, равная 0, соответствует положительной автокорреляции, когда выражение в скобках равно нулю (г= +1). При отрицательной автокорреляции (г= - 1), DW= 4 и выражение в скобках равно двум.
Ограничения критерия Дарбина - Уотсона следующие.
- 1. Статистика DW применяется лишь для тех моделей, которые содержат свободный член.
- 2. Предполагается, что случайные отклонения определяются по итерационной схеме
- 3. Статистические данные должны иметь одинаковую периодичность (не должно быть пропусков в наблюдениях).
- 4. Критерий Дарбина - Уотсона неприменим к авторегрессионным моделям вида
Для моделей (2.66) предлагается /г-статистика Дарбина:

где р - оценка р первого порядка (2.65);
D(c) - выборочная дисперсия коэффициента при лаговой переменной у, _ ь п - число наблюдений.
При большом п
и справедливости нуль-гипотезы Н 0:
р = 0 И-
статистика имеет стандартное распределение h ~ N{
0, 1). Поэтому при заданном уровне значимости определяется критическая точка из условия:

и Л-статистика сравнивается с иар.. Если И > иа/ 2 , то нуль-гипотеза об отсутствии автокорреляции должна быть отклонена. В противном случае она не отклоняется.
Обычно значение р рассчитывается в первом приближении по формуле р&1- DIV /2, a D(c) равна квадрату стандартной ошибки т с оценки коэффициента с. Следует отметить, что вычисление /г-статистики невозможно при nD(c) > 1.
Автокорреляция чаще всего вызывается неправильной спецификацией модели. Поэтому следует попытаться скорректировать саму модель, в частности ввести какой-нибудь неучтенный фактор или изменить форму модели, например, с линейной на полулогарифмическую или гиперболическую. Если все эти способы не помогают и автокорреляция вызвана какими-то внутренними свойствами ряда {е,}, можно воспользоваться преобразованием, которое называется авторегрессионной схемой первого порядка AR{ 1).
Рассмотрим /Щ1) на примере парной регрессии:
Тогда соседним наблюдениям согласно (2.68) соответствуют формулы:
Если случайные отклонения определяются выражением (2.65), где коэффициент р известен, то преобразования формул (2.69) и (2.70) дает:
Сделаем в (2.71) замены переменных: получим с учетом выражения (2.65):
Поскольку случайные отклонения у, удовлетворяют предпосылкам МНК, оценки а и b уравнения (2.73) будут обладать свойствами наилучших линейных несмещенных оценок. По преобразованным значениям всех переменных с помощью обычного МНК вычисляются оценки параметров а и Ь, которые затем можно использовать в регрессии (2.68).
Однако способ вычисления преобразованных переменных (2.72) приводит к потере первого наблюдения, если нет информации о предшествующих наблюдениях. Это уменьшает на единицу число степеней свободы, что при больших выборках не очень существенно, однако при малых выборках приводит к потере эффективности. Тогда первое наблюдение восстанавливается с помощью поправки Прайса- Уинстена:

Для преобразования /Щ1), а также при введении поправок (2.74) важно оценить коэффициент авторегрессии р. Это делается несколькими способами. Самое простое - оценить р на основе статистики
где г берется в качестве оценки р.
Формула (2.75) хорошо работает при большом числе наблюдений.
Существуют и другие методы оценивания р: метод Кокрена- Оркатта и метод Хилдрета-Лу. Рассмотрим метод Кокрена-Оркатта пошагово:
- 1. Сначала к непреобразованным исходным данным применяется обычный МНК, для которого рассчитываются остатки.
- 2. Затем в качестве приближенного значения коэффициента авторегрессии р берется его МНК-оценка в регрессии (2.65).
- 3. Проводится преобразование исходных переменных по формулам (2.72), и к преобразованным данным применяется МНК для определения новых оценок параметров а и Ь.
- 4. Процедура повторяется, начиная с п. 2.
Процесс обычно заканчивается, когда очередное приближение р мало отличается от предыдущего. Иногда просто фиксируется количество итераций. Такая процедура реализована в большинстве эконометрических компьютерных программ.
где Ду, = у, - у 1, Дх, = х, - х,_ 1 - так называемые первые разности (назад).
Из уравнения (2.76) по МНК оценивается коэффициент Ь. Параметр а здесь не определяется непосредственно, однако из МНК известно, что а = у -Ьх.
В случае р = -1, сложив (2.69) и (2.70) с учетом (2.65), получаем уравнение регрессии.
Истинные значения отклонений Et,t = 1,2, ...,T неизвестны. Поэтому выводы об их независимости осуществляются на основе оценок et,t = 1,2, ...,T, полученных из эмпирического уравнениярегрессии. Рассмотрим возможные методы определения автокорреляции.
Обычно проверяется некоррелированность отклонений et,t = 1, 2, ... , T, являющаяся необходимым, но недостаточным условием независимости. Причем проверяется некоррелированность соседних величин et. Соседними обычно считаются соседние во времени (при рассмотрении временных рядов) или по возрастанию объясняющей переменной X (в случае перекрестной выборки) значения et. Для них несложно рассчитать коэффициент корреляции, называемый в этом случае коэффициентом автокорреляции первого порядка:
При этом учитывается, что математическое ожидание остатков M (et) = 0.
На практике для анализа коррелированности отклонений вместо коэффициента корреляции используют тесно связанную с ним
статистику Ларбина-Уотсона (DW) рассчитываемую по формуле1

Очевидно, что при больших T

Нетрудно заметить, что если et=et-1, то rete- 1=1 и DW=0 (положительная автокорреляция). Если et=-et-1, то re^t 1=-1 и DW=4 (отрицательная автокорреляция). Во всех других случаях 0 lt; DW lt; 4 . При случайном поведении отклонений rete- 1=0 и DW=2. Таким
образом, необходимым условием независимости случайных отклонений является близость к двойке значения статистики Дарбина- Уотсона. Тогда, если DW ~ 2, мы считаем отклонения от регрессии случайными (хотя они в действительности могут и не быть таковыми). Это означает, что построенная линейная регрессия, вероятно, отражает реальную зависимость. Скорее всего, не осталось неучтенных существенных факторов, влияющих на зависимую переменную. Какая-либо другая нелинейная формула не превосходит по статистическим характеристикам предложенную линейную модель. В этом случае, даже когда R2 невелико, вполне вероятно, что необъясненная дисперсия вызвана влиянием на зависимую переменную большого числа различных факторов, индивидуально слабо влияющих на исследуемую переменную, и может быть описана как случайная нормальная ошибка.
Возникает вопрос, какие значения DW можно считать статистически близкими к 2? Для ответа на этот вопрос разработаны специальные таблицы критических точек статистики Дарбина-Уотсона, позволяющие при данном числе наблюдений T (или в прежних обозначениях n), количестве объясняющих переменных m и заданном уровне значимости а определять границы приемлемости (критические точки) наблюдаемой статистики DW. Для заданных а,Т, m в таблице указываются два числа: di - нижняя граница и du - верхняя граница.
Общая схема критерия Дарбина-Уотсона следующая:
- По построенному эмпирическому уравнению регрессии
определяются значения отклонений et = У, - У, для каждого наблюдения t, t = 1,..., Т.
- По формуле (4.4) рассчитывается статистика DW.
- По таблице критических точек Дарбина-Уотсона определяются два числа di и du и осуществляют выводы по правилу:
(dі lt; DW lt; du) - вывод о наличии автокорреляции не определен, (ku lt; DW lt; 4 - du) - автокорреляция отсутствует, (4 - du lt; DW lt; 4 - di) - вывод о наличии автокорреляции не определен,
(4 - di lt; DW lt; 4) - существует отрицательная автокорреляция.
Не обращаясь к таблице критических точек Дарбина-Уотсона, можно пользоваться «грубым» правилом и считать, что автокорреляция остатков отсутствует, если 1,5lt; DW lt; 2,5. Для более надежного вывода целесообразно обращаться к табличным значениям. При наличии автокорреляции остатков полученное уравнение регрессии обычно считается неудовлетворительным.
Отметим, что при использовании критерия Дарбина-Уотсона необходимо учитывать следующие ограничения:
- Критерий DW применяется лишь для тех моделей, которые содержат свободный член.
- Предполагается, что случайные отклонения Et определяются по итерационной схеме: Et = PEt-1 + vt, называемой авторегрессионной схемой первого порядка HR(1). Здесь vt - случайный член, для которого условия Гаусса-Маркова выполняются.
- Статистические данные должны иметь одинаковую периодичность (не должно быть пропусков в наблюдениях).
- Критерий Дарбина-Уотсона не применим для регрессионных моделей, содержащих в составе объясняющих переменных зависимую переменную с временным лагом в один период, т. е. для так называемых авторегрессионных моделей вида:
В этом случае имеется систематическая связь между одной из объясняющих переменных и одним из компонентов случайного члена. Не выполняется одна из основных предпосылок МНК - объясняющие переменные не должны быть случайными (не иметь случайной составляющей). Значение любой объясняющей переменной должно быть экзогенным (заданным вне модели), полностью определенным. В противном случае оценки будут смещенными даже при больших объемах выборок.
Для авторегрессионных моделей разработаны специальные тесты обнаружения автокорреляции, в частности h-статистика Дарби- на, которая определяется по формуле:
где р - оценка коэффициента р авторегрессии первого порядка?t = PCt-1 + vt (vt - случайный член), D(g) - выборочная дисперсия коэффициента Y при лаговой переменной yt-1, п - число наблюдений.
При большом объеме выборки h распределяется как ф(0,1), т. е. как нормальная переменная со средним значением 0 и дисперсией, равной 1 по нулевой гипотезе отсутствия автокорреляции. Следовательно, гипотеза отсутствия автокорреляции может быть отклонена при уровне значимости 5%, если абсолютное значение h больше, чем 1,96, и при уровне значимости 1%, если оно больше, чем 2,58, при применении двухстороннего критерия и большой выборке. В противном случае она не отклоняется.
Отметим, что обычно значение р рассчитывается по формуле:
р = 1- 0,5DW, а D(g) равна квадрату стандартной ошибки Sg
оценки g коэффициента Y. Поэтому h легко вычисляется на основе данных оцененной регрессии.
Основная проблема при использовании этого теста заключается в невозможности вычисления h при nD (g) gt; 1.
Пример 4.1. Пусть имеются следующие условные данные (X - объясняющая переменная, Y - зависимая переменная, табл. 4.1).
Таблица 4.1
Исходные данные (условные, ден. ед.)
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| X | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| Y | 3 | 8 | 6 | 12 | 11 | 17 | 15 | 20 | 16 | 24 | 22 | 28 | 26 | 34 | 31 |
Линейное уравнение регрессии имеет вид: Y = 2,09 + 2,014X .
Рассчитаем статистику Дарбина-Уотсона (табл. 4.2):
 Могильники Чернобыля: радиоактивные отходы зоны отчуждения Где находится техника чернобыля
Могильники Чернобыля: радиоактивные отходы зоны отчуждения Где находится техника чернобыля Девочка заговорила на иностранном языке после комы
Девочка заговорила на иностранном языке после комы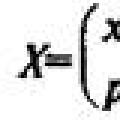 Сравнение законов распределения вероятностей
Сравнение законов распределения вероятностей