Какая из функций реализует алгоритм кластеризации. Кластерный анализ — это алгоритм исследования данных, разбитых на группы по схожим признакам. Автоматизированная кластеризация ся
Приветствую!
В своей дипломной работе я проводил обзор и сравнительный анализ алгоритмов кластеризации данных. Подумал, что уже собранный и проработанный материал может оказаться кому-то интересен и полезен.
О том, что такое кластеризация, рассказал в статье . Я частично повторю слова Александра, частично дополню. Также в конце этой статьи интересующиеся могут почитать материалы по ссылкам в списке литературы.
Так же я постарался привести сухой «дипломный» стиль изложения к более публицистическому.
Понятие кластеризации
Кластеризация (или кластерный анализ) - это задача разбиения множества объектов на группы, называемые кластерами. Внутри каждой группы должны оказаться «похожие» объекты, а объекты разных группы должны быть как можно более отличны. Главное отличие кластеризации от классификации состоит в том, что перечень групп четко не задан и определяется в процессе работы алгоритма.Применение кластерного анализа в общем виде сводится к следующим этапам:
- Отбор выборки объектов для кластеризации.
- Определение множества переменных, по которым будут оцениваться объекты в выборке. При необходимости – нормализация значений переменных.
- Вычисление значений меры сходства между объектами.
- Применение метода кластерного анализа для создания групп сходных объектов (кластеров).
- Представление результатов анализа.
Меры расстояний
Итак, как же определять «похожесть» объектов? Для начала нужно составить вектор характеристик для каждого объекта - как правило, это набор числовых значений, например, рост-вес человека. Однако существуют также алгоритмы, работающие с качественными (т.н. категорийными) характеристиками.После того, как мы определили вектор характеристик, можно провести нормализацию, чтобы все компоненты давали одинаковый вклад при расчете «расстояния». В процессе нормализации все значения приводятся к некоторому диапазону, например, [-1, -1] или .
Наконец, для каждой пары объектов измеряется «расстояние» между ними - степень похожести. Существует множество метрик, вот лишь основные из них:
Выбор метрики полностью лежит на исследователе, поскольку результаты кластеризации могут существенно отличаться при использовании разных мер.
Классификация алгоритмов
Для себя я выделил две основные классификации алгоритмов кластеризации.- Иерархические и плоские.
Иерархические алгоритмы (также называемые алгоритмами таксономии) строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. Т.о. на выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями - наиболее мелкие кластера.
Плоские алгоритмы строят одно разбиение объектов на кластеры. - Четкие и нечеткие.
Четкие (или непересекающиеся) алгоритмы каждому объекту выборки ставят в соответствие номер кластера, т.е. каждый объект принадлежит только одному кластеру. Нечеткие (или пересекающиеся) алгоритмы каждому объекту ставят в соответствие набор вещественных значений, показывающих степень отношения объекта к кластерам. Т.е. каждый объект относится к каждому кластеру с некоторой вероятностью.
Объединение кластеров
В случае использования иерархических алгоритмов встает вопрос, как объединять между собой кластера, как вычислять «расстояния» между ними. Существует несколько метрик:- Одиночная связь (расстояния ближайшего соседа)
В этом методе расстояние между двумя кластерами определяется расстоянием между двумя наиболее близкими объектами (ближайшими соседями) в различных кластерах. Результирующие кластеры имеют тенденцию объединяться в цепочки. - Полная связь (расстояние наиболее удаленных соседей)
В этом методе расстояния между кластерами определяются наибольшим расстоянием между любыми двумя объектами в различных кластерах (т.е. наиболее удаленными соседями). Этот метод обычно работает очень хорошо, когда объекты происходят из отдельных групп. Если же кластеры имеют удлиненную форму или их естественный тип является «цепочечным», то этот метод непригоден. - Невзвешенное попарное среднее
В этом методе расстояние между двумя различными кластерами вычисляется как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты формируют различные группы, однако он работает одинаково хорошо и в случаях протяженных («цепочечного» типа) кластеров. - Взвешенное попарное среднее
Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях размер соответствующих кластеров (т.е. число объектов, содержащихся в них) используется в качестве весового коэффициента. Поэтому данный метод должен быть использован, когда предполагаются неравные размеры кластеров. - Невзвешенный центроидный метод
В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести. - Взвешенный центроидный метод (медиана)
Этот метод идентичен предыдущему, за исключением того, что при вычислениях используются веса для учета разницы между размерами кластеров. Поэтому, если имеются или подозреваются значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
Обзор алгоритмов
Алгоритмы иерархической кластеризации
Среди алгоритмов иерархической кластеризации выделяются два основных типа: восходящие и нисходящие алгоритмы. Нисходящие алгоритмы работают по принципу «сверху-вниз»: в начале все объекты помещаются в один кластер, который затем разбивается на все более мелкие кластеры. Более распространены восходящие алгоритмы, которые в начале работы помещают каждый объект в отдельный кластер, а затем объединяют кластеры во все более крупные, пока все объекты выборки не будут содержаться в одном кластере. Таким образом строится система вложенных разбиений. Результаты таких алгоритмов обычно представляют в виде дерева – дендрограммы. Классический пример такого дерева – классификация животных и растений.Для вычисления расстояний между кластерами чаще все пользуются двумя расстояниями: одиночной связью или полной связью (см. обзор мер расстояний между кластерами).
К недостатку иерархических алгоритмов можно отнести систему полных разбиений, которая может являться излишней в контексте решаемой задачи.
Алгоритмы квадратичной ошибки
Задачу кластеризации можно рассматривать как построение оптимального разбиения объектов на группы. При этом оптимальность может быть определена как требование минимизации среднеквадратической ошибки разбиения:
Где c j - «центр масс» кластера j (точка со средними значениями характеристик для данного кластера).
Алгоритмы квадратичной ошибки относятся к типу плоских алгоритмов. Самым распространенным алгоритмом этой категории является метод k-средних. Этот алгоритм строит заданное число кластеров, расположенных как можно дальше друг от друга. Работа алгоритма делится на несколько этапов:
- Случайно выбрать k точек, являющихся начальными «центрами масс» кластеров.
- Отнести каждый объект к кластеру с ближайшим «центром масс».
- Пересчитать «центры масс» кластеров согласно их текущему составу.
- Если критерий остановки алгоритма не удовлетворен, вернуться к п. 2.
К недостаткам данного алгоритма можно отнести необходимость задавать количество кластеров для разбиения.
Нечеткие алгоритмы
Наиболее популярным алгоритмом нечеткой кластеризации является алгоритм c-средних (c-means). Он представляет собой модификацию метода k-средних. Шаги работы алгоритма:
Этот алгоритм может не подойти, если заранее неизвестно число кластеров, либо необходимо однозначно отнести каждый объект к одному кластеру.
Алгоритмы, основанные на теории графов
Суть таких алгоритмов заключается в том, что выборка объектов представляется в виде графа G=(V, E) , вершинам которого соответствуют объекты, а ребра имеют вес, равный «расстоянию» между объектами. Достоинством графовых алгоритмов кластеризации являются наглядность, относительная простота реализации и возможность вносения различных усовершенствований, основанные на геометрических соображениях. Основными алгоритмам являются алгоритм выделения связных компонент, алгоритм построения минимального покрывающего (остовного) дерева и алгоритм послойной кластеризации.Алгоритм выделения связных компонент
В алгоритме выделения связных компонент задается входной параметр R и в графе удаляются все ребра, для которых «расстояния» больше R . Соединенными остаются только наиболее близкие пары объектов. Смысл алгоритма заключается в том, чтобы подобрать такое значение R , лежащее в диапазон всех «расстояний», при котором граф «развалится» на несколько связных компонент. Полученные компоненты и есть кластеры.Для подбора параметра R обычно строится гистограмма распределений попарных расстояний. В задачах с хорошо выраженной кластерной структурой данных на гистограмме будет два пика – один соответствует внутрикластерным расстояниям, второй – межкластерным расстояния. Параметр R подбирается из зоны минимума между этими пиками. При этом управлять количеством кластеров при помощи порога расстояния довольно затруднительно.
Алгоритм минимального покрывающего дерева
Алгоритм минимального покрывающего дерева сначала строит на графе минимальное покрывающее дерево, а затем последовательно удаляет ребра с наибольшим весом. На рисунке изображено минимальное покрывающее дерево, полученное для девяти объектов.
Путём удаления связи, помеченной CD, с длиной равной 6 единицам (ребро с максимальным расстоянием), получаем два кластера: {A, B, C} и {D, E, F, G, H, I}. Второй кластер в дальнейшем может быть разделён ещё на два кластера путём удаления ребра EF, которое имеет длину, равную 4,5 единицам.
Послойная кластеризация
Алгоритм послойной кластеризации основан на выделении связных компонент графа на некотором уровне расстояний между объектами (вершинами). Уровень расстояния задается порогом расстояния c . Например, если расстояние между объектамиАлгоритм послойной кластеризации формирует последовательность подграфов графа G , которые отражают иерархические связи между кластерами:
![]() ,
,
Где G t = (V, E t)
- граф на уровне с t
,![]() ,
,
с t
– t-ый порог расстояния,
m – количество уровней иерархии,
G 0 = (V, o)
, o – пустое множество ребер графа, получаемое при t 0
= 1,
G m = G
, то есть граф объектов без ограничений на расстояние (длину ребер графа), поскольку t m
= 1.
Посредством изменения порогов расстояния {с 0 , …, с m }, где 0 = с 0 < с 1 < …< с m = 1, возможно контролировать глубину иерархии получаемых кластеров. Таким образом, алгоритм послойной кластеризации способен создавать как плоское разбиение данных, так и иерархическое.
Сравнение алгоритмов
Вычислительная сложность алгоритмовСравнительная таблица алгоритмов
| Алгоритм кластеризации | Форма кластеров | Входные данные | Результаты |
| Иерархический | Произвольная | Число кластеров или порог расстояния для усечения иерархии | Бинарное дерево кластеров |
| k-средних | Гиперсфера | Число кластеров | Центры кластеров |
| c-средних | Гиперсфера | Число кластеров, степень нечеткости | Центры кластеров, матрица принадлежности |
| Выделение связных компонент | Произвольная | Порог расстояния R | |
| Минимальное покрывающее дерево | Произвольная | Число кластеров или порог расстояния для удаления ребер | Древовидная структура кластеров |
| Послойная кластеризация | Произвольная | Последовательность порогов расстояния | Древовидная структура кластеров с разными уровнями иерархии |
Немного о применении
В своей работе мне нужно было из иерархических структур (деревьев) выделять отдельные области. Т.е. по сути необходимо было разрезать исходное дерево на несколько более мелких деревьев. Поскольку ориентированное дерево – это частный случай графа, то естественным образом подходят алгоритмы, основанными на теории графов.В отличие от полносвязного графа, в ориентированном дереве не все вершины соединены ребрами, при этом общее количество ребер равно n–1, где n – число вершин. Т.е. применительно к узлам дерева, работа алгоритма выделения связных компонент упростится, поскольку удаление любого количества ребер «развалит» дерево на связные компоненты (отдельные деревья). Алгоритм минимального покрывающего дерева в данном случае будет совпадать с алгоритмом выделения связных компонент – путем удаления самых длинных ребер исходное дерево разбивается на несколько деревьев. При этом очевидно, что фаза построения самого минимального покрывающего дерева пропускается.
В случае использования других алгоритмов в них пришлось бы отдельно учитывать наличие связей между объектами, что усложняет алгоритм.
Отдельно хочу сказать, что для достижения наилучшего результата необходимо экспериментировать с выбором мер расстояний, а иногда даже менять алгоритм. Никакого единого решения не существует.
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».

Кластеризация семантического ядра - это разделение множества разнородных запросов на группы по смыслу.
Больше видео на нашем канале - изучайте интернет-маркетинг с SEMANTICA
![]()
Чтобы лучше понять, что такое кластеризация , можно представить подготовку белья перед стиркой. Чтобы стирка прошла быстро и продуктивно, вещи разделяют на несколько групп по цветам. А опытные хозяйки проводят сортировку белья с более подробной детализацией. В каждой цветовой группе найдутся вещи, которые нуждаются в особом температурном режиме. Их выделяют в отдельные группы. Нечто подобное происходит и при кластеризации ключевых слов. Это процесс, который превращает сотни и тысячи пользовательских запросов в упорядоченную структуру.
В идеале кластеризация ключей должна осуществляться на базе перечня свойств объектов, которые характеризуют данные ключи, а также контекста их применения. Однако на данный момент не существует открытых баз, хранящих такие сведения. По этой причине группировка ключевых слов проводится на основе поисковой выдачи.
Этапы кластеризации:
- Получение выборки объектов для группировки.
- Задание перечня критериев оценки объектов в выборке.
- Определение степени сходства между анализируемыми объектами.
- Проведение кластерного анализа для формирования групп объектов.
- Представление результатов кластеризации.
Зачем нужно проводить кластеризацию СЯ
С помощью грамотных инструментов можно в минимальные сроки и группировать большие семантические ядра. Если в прошлом на создание ядра уходили целые месяцы, то сейчас эта работа занимает всего пару часов. Одним из преимуществ кластеризации является распределение поисковых запросов по страницам таким образом, чтобы их продвижение происходило одновременно.
Кластеризация семантического ядра позволяет получить:
- Существенную экономию времени за счет сокращения рутинной работы.
- Информационный гид по темам, популярным среди пользователей.
- План продвижения.
- Представление структуры разрабатываемого сайта.
- Объективную оценку популярности продукцию в указанной нише.
- Перечень ключей для оптимизации ресурса.
- Осуществление корректной переадресации веб-страниц.
- Создание большого хвоста поисковых запросов.
Что происходит, если не проводить кластеризацию
Если пренебречь разбиением семантического ядра сайта на кластеры, то его владелец не получит полной картины продвижения своего ресурса. Подобный результат можно получить и вследствие неправильного распределения поисковых фраз.
Вот перечень проблем, которые возникнут после некорректной группировки ключей:
- Теряется позиция в ТОПе поисковой выдачи;
- Происходит каннибализация и, как следствие, в индексах поисковиков возникает множество дублей;
- Происходит дезориентация поведенческих факторов, мешающая продвижению ресурса;
- Расходуются большие средства на создание "лишнего" контента.
Устранение и предупреждение подобных проблем - это главный ответ на вопрос: "зачем делать кластеризацию ся".
Алгоритмы кластеризации
SEO-специалисты выделяют два типа классификации алгоритмов кластеризации:
Иерархические и плоские
Иерархические алгоритмы (еще их называют алгоритмами-таксонами) формируют не одно разделение множества на пересекающиеся кластеры, а многоуровневую структуру вложенных разбиений. В результате формируется дерево кластеров. В качестве его корня выступает общая выборка, а в качестве листьев - самые мелкие группы.
Плоские алгоритмы формируют одно разделение объектов на группы.
Четкие и нечеткие
Четкие алгоритмы связывают каждый элемент выборки с номером кластера. Нечеткие алгоритмы связывают каждый элемент выборки с комбинацией вещественных значений, отражающих меру принадлежности элемента к кластерам. Таким образом каждый элемент выборки относится к каждой группе с определенной долей вероятности.
Как провести кластеризацию запросов вручную
Для ручной кластеризации семантического ядра сайта достаточно самостоятельно проанализировать ключевики и разделить их на группы. Эту работу можно облегчить с помощью инструментов Excel, LibreOffice, OpenOffice. Эти приложения позволяют работать с таблицами данных, выполнять сортировку и фильтрование по определенным параметрам.
Представленные инструменты имеют ряд достоинств:
- Универсальность - производят группировку с учетом множества разных критериев;
- Высокая точность обработки;
- LibreOffice, OpenOffice - бесплатные.
В числе их недостатков:
- Необходимость периодических бекапов;
- Низкая скорость обработки;
- Лицензионный Excel - платный.
Ручная кластеризация семантического ядра сайта более сложная и длительная по сравнению с автоматизированной. Зато можно лично проконтролировать весь процесс. Если этому уделить должное внимание, то результат качественно превзойдет автоматическую кластеризацию ся.
Автоматизированная кластеризация ся
Разделение семантического ядра на группы происходит автоматически.
Вебмастеру достаточно оценить полученные результаты. Единственным минусом такого подхода является периодически возникающее несоответствие машинной логики представлениям пользователя.
Обойти эту проблему может полуавтоматический способ группировки поисковых запросов. Для этого специалисту необходимо самостоятельно подобрать группы по полученным запросам. А автоматизированная система сама разделит запросы по указанным пользователем группам. Такой подход позволяет существенно минимизировать ошибки машинного алгоритма.
Как провести кластеризацию запросов с помощью Key Collector
Одним из лучших приложений для проведения кластеризации считается Key Collector. Программа позволяет быстро получить ключи, на основании которых будет сформировано семантическое ядро. Система может оценить конкурентность, эффективность и стоимость ключей, а также проанализировать ресурс на соответствие его контента полученному ядру.
Схема работы Key Collector достаточно проста. Чтобы разделить все полученные запросы, необходимо воспользоваться опцией «Анализ групп». При этом системе нужно указать режим кластеризации ("по отдельным словам", "по составу фраз", "по поисковой выдаче", "по составу фраз и поисковой выдаче"). Режим "по отдельным словам" группирует поисковые запросы, у которых присутствует совпадение даже по одному слову. Режим "по составу фраз" ориентируется на строение ключевых фраз. Это наиболее подходящий способ разбиения большого количества запросов. Режим "по поисковой выдаче" группирует ключевые фразы по количеству совпавших ссылок в результатах поиска. Режим "по составу фраз и поисковой выдаче" сочетает в себе два предыдущих критерия.
Пример кластеризации семантического ядра в системе Key Collector:

Чтобы оценить группы, которые получились, их можно выгрузить в табличный редактор (например в Excel).

Мы знаем, что Земля – это одна из 8 планет, которые вращаются вокруг Солнца. Солнце – это всего лишь звезда среди порядка 200 миллиардов звезд в галактике Млечный Путь. Очень тяжело осознать это число. Зная это, можно сделать предположение о количестве звезд во вселенной – приблизительно 4X10^22. Мы можем видеть около миллиона звезд на небе, хотя это всего лишь малая часть от всего фактического количества звезд. Итак, у нас появилось два вопроса:
- Что такое галактика?
- И какая связь между галактиками и темой статьи (кластерный анализ)
Галактика – это скопление звезд, газа, пыли, планет и межзвездных облаков. Обычно галактики напоминают спиральную или эдептическую фигуру. В пространстве галактики отделены друг от друга. Огромные черные дыры чаще всего являются центрами большинства галактик.
Как мы будем обсуждать в следующем разделе, есть много общего между галактиками и кластерным анализом. Галактики существуют в трехмерном пространстве, кластерный анализ – это многомерный анализ, проводимый в n-мерном пространстве.
Заметка: Черная дыра – это центр галактики. Мы будем использовать похожую идею в отношении центроидов для кластерного анализа.
Кластерный анализ
Предположим вы глава отдела по маркетингу и взаимодействию с потребителями в телекоммуникационной компании. Вы понимаете, что все потребители разные, и что вам необходимы различные стратегии для привлечения различных потребителей. Вы оцените мощь такого инструмента как сегментация клиентов для оптимизации затрат. Для того, чтобы освежить ваши знания кластерного анализа, рассмотрим следующий пример, иллюстрирующий 8 потребителей и среднюю продолжительность их разговоров (локальных и международных). Ниже данные:
Для лучшего восприятия нарисуем график, где по оси x будет откладываться средняя продолжительность международных разговоров, а по оси y - средняя продолжительность локальных разговоров. Ниже график:

Заметка: Это похоже на анализ расположения звезд на ночном небе (здесь звезды заменены потребителями). В дополнение, вместо трехмерного пространства у нас двумерное, заданное продолжительностью локальных и международных разговоров, в качестве осей x и y.
Сейчас, разговаривая в терминах галактик, задача формулируется так – найти положение черных дыр; в кластерном анализе они называются центроидами. Для обнаружения центроидов мы начнем с того, что возьмем произвольные точки в качестве положения центроидов.
Евклидово расстояние для нахождения Центроидов для Кластеров
В нашем случае два центроида (C1 и C2) мы произвольным образом поместим в точки с координатами (1, 1) и (3, 4). Почему мы выбрали именно эти два центроида? Визуальное отображение точек на графике показывает нам, что есть два кластера, которые мы будем анализировать. Однако, впоследствии мы увидим, что ответ на этот вопрос будет не таким уж простым для большого набора данных.Далее, мы измерим расстояние между центроидами (C1 и C2) и всеми точками на графике использую формулу Евклида для нахождения расстояния между двумя точками.
Примечание: Расстояние может быть вычислено и по другим формулам, например,
- квадрат евклидова расстояния – для придания веса более отдаленным друг от друга объектам
- манхэттенское расстояние – для уменьшения влияния выбросов
- степенное расстояние – для увеличения/уменьшения влияния по конкретным координатам
- процент несогласия – для категориальных данных
- и др.
Принадлежность к центроидам (последняя колонка) вычисляется по принципу близости к центроидам (C1 и C2). Первый потребитель ближе к центроиду №1 (1.41 по сравнению с 2.24) следовательно, принадлежит к кластеру с центроидом C1.

Ниже график, иллюстрирующий центроиды C1 и C2 (изображенные в виде голубого и оранжевого ромбика). Потребители изображены цветом соответствующего центроида, к кластеру которого они были отнесены.

Так как мы произвольным образом выбрали центроиды, вторым шагом мы сделать этот выбор итеративным. Новая позиция центроидов выбирается как средняя для точек соответствующего кластера. Так, например, для первого центроида (это потребители 1, 2 и 3). Следовательно, новая координата x для центроида C1 э то средняя координат x этих потребителей (2+1+1)/3 = 1.33. Мы получим новые координаты для C1 (1.33, 2.33) и C2 (4.4, 4.2).Новый график ниже:

В конце концов, мы поместим центроиды в центр соответствующего кластера. График ниже:

Позиции наших черных дыр (центров кластеров) в нашем примере C1 (1.75, 2.25) и C2(4.75, 4.75). Два кластера выше подобны двум галактикам, разделенным в пространстве друг от друга.
Итак, рассмотрим примеры дальше. Пусть перед нами стоит задача по сегментации потребителей по двум параметрам: возраст и доход. Предположим, что у нас есть 2 потребителя с возрастом 37 и 44 лет и доходом в $90,000 и $62,000 соответственно. Если мы хотим измерить Евклидово расстояние между точками (37, 90000) и (44, 62000), мы увидим, что в данном случае переменная доход «доминирует» над переменной возраст и ее изменение сильно сказывается на расстоянии. Нам необходима какая-нибудь стратегия для решения данной проблемы, иначе наш анализ даст неверный результат. Решение данной проблемы это приведение наших значений к сравнимым шкалам. Нормализация – вот решение нашей проблемы.
Нормализация данных
Существует много подходов для нормализации данных. Например, нормализация минимума-максимума. Для данной нормализации используется следующая формулав данном случае X* - это нормализованное значение, min и max – минимальная и максимальная координата по всему множеству X
(Примечание, данная формула располагает все координаты на отрезке )
Рассмотрим наш пример, пусть максимальный доход $130000, а минимальный - $45000. Нормализованное значение дохода для потребителя A равно
![]()
Мы сделаем это упражнение для всех точек для каждых переменных (координат). Доход для второго потребителя (62000) станет 0.2 после процедуры нормализации. Дополнительно, пусть минимальный и максимальный возрасты 23 и 58 соответственно. После нормализации возрасты двух наших потребителей составит 0.4 и 0.6.
Легко увидеть, что теперь все наши данные расположены между значениями 0 и 1. Следовательно, у нас теперь есть нормализованные наборы данных в сравнимых шкалах.
Запомните, перед процедурой кластерного анализа необходимо произвести нормализацию.
С понятием кластеризации мы познакомились в первом разделе курса. В этой лекции мы опишем понятие " кластер " с математической точки зрения, а также рассмотрим методы решения задач кластеризации - методы кластерного анализа.
Термин кластерный анализ , впервые введенный Трионом (Tryon) в 1939 году, включает в себя более 100 различных алгоритмов.
В отличие от задач классификации, кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных (интервальным данным, частотам, бинарным данным). При этом необходимо помнить, что переменные должны измеряться в сравнимых шкалах.
Кластерный анализ позволяет сокращать размерность данных, делать ее наглядной.
Кластерный анализ может применяться к совокупностям временных рядов, здесь могут выделяться периоды схожести некоторых показателей и определяться группы временных рядов со схожей динамикой.
Кластерный анализ параллельно развивался в нескольких направлениях, таких как биология, психология, др., поэтому у большинства методов существует по два и более названий. Это существенно затрудняет работу при использовании кластерного анализа.
Задачи кластерного анализа можно объединить в следующие группы:
- Разработка типологии или классификации.
- Исследование полезных концептуальных схем группирования объектов.
- Представление гипотез на основе исследования данных.
- Проверка гипотез или исследований для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Как правило, при практическом использовании кластерного анализа одновременно решается несколько из указанных задач.
Рассмотрим пример процедуры кластерного анализа.
Допустим, мы имеем набор данных А, состоящий из 14-ти примеров, у которых имеется по два признака X и Y. Данные по ним приведены в таблице 13.1 .
| № примера | признак X | признак Y |
|---|---|---|
| 1 | 27 | 19 |
| 2 | 11 | 46 |
| 3 | 25 | 15 |
| 4 | 36 | 27 |
| 5 | 35 | 25 |
| 6 | 10 | 43 |
| 7 | 11 | 44 |
| 8 | 36 | 24 |
| 9 | 26 | 14 |
| 10 | 26 | 14 |
| 11 | 9 | 45 |
| 12 | 33 | 23 |
| 13 | 27 | 16 |
| 14 | 10 | 47 |
Данные в табличной форме не носят информативный характер. Представим переменные X и Y в виде диаграммы рассеивания, изображенной на рис. 13.1 .
Рис.
13.1.
На рисунке мы видим несколько групп "похожих" примеров. Примеры (объекты), которые по значениям X и Y "похожи" друг на друга, принадлежат к одной группе (кластеру); объекты из разных кластеров не похожи друг на друга.
Критерием для определения схожести и различия кластеров является расстояние между точками на диаграмме рассеивания. Это сходство можно "измерить", оно равно расстоянию между точками на графике. Способов определения меры расстояния между кластерами, называемой еще мерой близости, существует несколько. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда известны их координаты X и Y:
Примечание: чтобы узнать расстояние между двумя точками, надо взять разницу их координат по каждой оси, возвести ее в квадрат, сложить полученные значения для всех осей и извлечь квадратный корень из суммы.
Когда осей больше, чем две, расстояние рассчитывается таким образом: сумма квадратов разницы координат состоит из стольких слагаемых, сколько осей (измерений) присутствует в нашем пространстве. Например, если нам нужно найти расстояние между двумя точками в пространстве трех измерений (такая ситуация представлена на рис. 13.2), формула (13.1) приобретает вид:

Рис. 13.2.
Кластер имеет следующие математические характеристики : центр , радиус , среднеквадратическое отклонение , размер кластера .
Центр кластера - это среднее геометрическое место точек в пространстве переменных.
Радиус кластера - максимальное расстояние точек от центра кластера .
Как было отмечено в одной из предыдущих лекций, кластеры могут быть перекрывающимися. Такая ситуация возникает, когда обнаруживается перекрытие кластеров. В этом случае невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров. Такие объекты называют спорными .
Спорный объект - это объект , который по мере сходства может быть отнесен к нескольким кластерам.
Размер кластера может быть определен либо по радиусу кластера , либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера . Если это условие выполняется для двух и более кластеров, объект является спорным .
Неоднозначность данной задачи может быть устранена экспертом или аналитиком.
Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые признаки объекта в принципе допускают желательное разбиение пула (совокупности) объектов на кластеры. В начале лекции мы уже упоминали о сравнимости шкал, это и есть второе предположение - правильность выбора масштаба или единиц измерения признаков.
Выбор масштаба в кластерном анализе имеет большое значение . Рассмотрим пример. Представим себе, что данные признака х в наборе данных А на два порядка больше данных признака у: значения переменной х находятся в диапазоне от 100 до 700, а значения переменной у - в диапазоне от 0 до 1.
Тогда, при расчете величины расстояния между точками, отражающими положение объектов в пространстве их свойств,
В ходе экспериментов возможно сравнение результатов, полученных с учетом экспертных оценок и без них, и выбор лучшего из них.
Типы входных данных
- Признаковое описание объектов. Каждый объект описывается набором своих характеристик, называемых признаками . Признаки могут быть числовыми или нечисловыми.
- Матрица расстояний между объектами. Каждый объект описывается расстояниями до всех остальных объектов обучающей выборки.
Матрица расстояний может быть вычислена по матрице признаковых описаний объектов бесконечным числом способов, в зависимости от того, как ввести функцию расстояния (метрику) между признаковыми описаниями. Часто используется евклидова метрика , однако этот выбор в большинстве случаев является эвристикой и обусловлен лишь соображениями удобства.
Обратная задача - восстановление признаковых описаний по матрице попарных расстояний между объектами - в общем случае не имеет решения, а приближённое решение не единственно и может иметь существенную погрешность. Эта задача решается методами многомерного шкалирования .
Таким образом, постановка задачи кластеризации по матрице расстояний является более общей. С другой стороны, при наличии признаковых описаний часто удаётся строить более эффективные методы кластеризации.
Цели кластеризации
- Понимание данных путём выявления кластерной структуры. Разбиение выборки на группы схожих объектов позволяет упростить дальнейшую обработку данных и принятия решений, применяя к каждому кластеру свой метод анализа (стратегия «разделяй и властвуй »).
- Сжатие данных . Если исходная выборка избыточно большая, то можно сократить её, оставив по одному наиболее типичному представителю от каждого кластера.
- Обнаружение новизны (novelty detection). Выделяются нетипичные объекты, которые не удаётся присоединить ни к одному из кластеров.
В первом случае число кластеров стараются сделать поменьше. Во втором случае важнее обеспечить высокую (или фиксированную) степень сходства объектов внутри каждого кластера, а кластеров может быть сколько угодно. В третьем случае наибольший интерес представляют отдельные объекты, не вписывающиеся ни в один из кластеров.
Во всех этих случаях может применяться иерархическая кластеризация , когда крупные кластеры дробятся на более мелкие, те в свою очередь дробятся ещё мельче, и т. д. Такие задачи называются задачами таксономии .
Результатом таксономии является древообразная иерархическая структура. При этом каждый объект характеризуется перечислением всех кластеров, которым он принадлежит, обычно от крупного к мелкому. Визуально таксономия представляется в виде графика, называемого дендрограммой .
Классическим примером таксономии на основе сходства является биноминальная номенклатура живых существ , предложенная Карлом Линнеем в середине XVIII века. Аналогичные систематизации строятся во многих областях знания, чтобы упорядочить информацию о большом количестве объектов.
Функции расстояния
Методы кластеризации
- Статистические алгоритмы кластеризации
- Иерархическая кластеризация или таксономия
Формальная постановка задачи кластеризации
Пусть - множество объектов, - множество номеров (имён, меток) кластеров. Задана функция расстояния между объектами . Имеется конечная обучающая выборка объектов . Требуется разбить выборку на непересекающиеся подмножества, называемые кластерами , так, чтобы каждый кластер состоял из объектов, близких по метрике , а объекты разных кластеров существенно отличались. При этом каждому объекту приписывается номер кластера .
Алгоритм кластеризации - это функция , которая любому объекту ставит в соответствие номер кластера . Множество в некоторых случаях известно заранее, однако чаще ставится задача определить оптимальное число кластеров, с точки зрения того или иного критерия качества кластеризации.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки исходных объектов изначально не заданы, и даже может быть неизвестно само множество .
Решение задачи кластеризации принципиально неоднозначно, и тому есть несколько причин:
- Не существует однозначно наилучшего критерия качества кластеризации. Известен целый ряд эвристических критериев, а также ряд алгоритмов, не имеющих чётко выраженного критерия, но осуществляющих достаточно разумную кластеризацию «по построению». Все они могут давать разные результаты.
- Число кластеров, как правило, неизвестно заранее и устанавливается в соответствии с некоторым субъективным критерием.
- Результат кластеризации существенно зависит от метрики, выбор которой, как правило, также субъективен и определяется экспертом.
Ссылки
- Воронцов К.В. Математические методы обучения по прецедентам . МФТИ (2004), ВМиК МГУ (2007).
- Сергей Николенко. Слайды лекций «Алгоритмы кластеризации 1» и «Алгоритмы кластеризации 2» . Курс «Самообучающиеся системы» .
Литература
- Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная статистика: классификация и снижение размерности. - М.: Финансы и статистика, 1989.
- Журавлев Ю. И., Рязанов В. В., Сенько О. В. «Распознавание». Математические методы. Программная система. Практические применения. - М.: Фазис, 2006. .
- Загоруйко Н. Г. Прикладные методы анализа данных и знаний. - Новосибирск: ИМ СО РАН, 1999. .
- Мандель И. Д. Кластерный анализ. - М.: Финансы и статистика, 1988. .
- Шлезингер М., Главач В. Десять лекций по статистическому и структурному распознаванию. - Киев: Наукова думка, 2004. .
- Hastie T., Tibshirani R., Friedman J. The Elements of Statistical Learning. - Springer, 2001. .
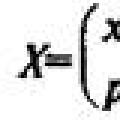 Сравнение законов распределения вероятностей
Сравнение законов распределения вероятностей Советский поэт Асадов Эдуард Аркадьевич: личная жизнь, творчество
Советский поэт Асадов Эдуард Аркадьевич: личная жизнь, творчество Лондон против всех Конфликт мирона и лсп
Лондон против всех Конфликт мирона и лсп