Вычислить определитель 4 порядка двумя способами. Определители. Вычисление определителей. Вычисление определителя матрицы методом Гаусса
В зависимости от признака, положенного в основу образования ряда распределения, различают атрибутивные и вариационные ряды распределения .
Наличие общего признака является основой для образования статистической совокупности, которая представляет собой результаты описания или измерения общих признаков объектов исследования.
Предметом изучения в статистике являются изменяющиеся (варьирующие) признаки или статистические признаками.
Виды статистических признаков .
Атрибутивными называют ряды распределения
, построенные по качественным признакам. Атрибутивный
– это признак, имеющий наименование, (например профессия: швея, учитель и т.д.).
Ряд распределения принято оформлять в виде таблиц. В табл. 2.8 приведён атрибутивный ряд распределения.
Таблица 2.8 - Распределение видов юридической помощи, оказанной адвокатами гражданам одного из регионов РФ.
Вариационными рядами называют ряды распределения , построенные по количественному признаку. Любой вариационный ряд состоит из двух элементов: вариантов и частот.
Вариантами считаются отдельные значения признака, которые он принимает в вариационном ряду.
Частоты – это численности отдельных вариантов или каждой группы вариационного ряда, т.е. это числа, показывающие, как часто встречаются те или иные варианты в ряду распределения. Сумма всех частот определяет численность всей совокупности, её объём.
Частостями называются частоты, выраженные в долях единицы или в процентах к итогу. Соответственно сумма частостей равна 1 или 100 %. Вариационный ряд позволяет по фактическим данным оценить форму закона распределения.
В зависимости от характера вариации признака различают дискретные и интервальные вариационные ряды
.
Пример дискретного вариационного ряда приведен в табл. 2.9.
Таблица 2.9 - Распределение семей по числу занимаемых комнат в отдельных квартирах в 1989 г. в РФ.
Вариационный ряд
В генеральной совокупности исследуется некоторый количественный признак. Из нее случайным образом извлекается выборка объема n , то есть число элементов выборки равно n . На первом этапе статистической обработки производят ранжирование выборки, т.е. упорядочивание чисел x 1 , x 2 , …, x n по возрастанию. Каждое наблюдаемое значение x i называется вариантой . Частота m i – это число наблюдений значения x i в выборке. Относительная частота (частость) w i – это отношение частоты m i к объему выборкиn : .При изучении вариационного ряда также используют понятия накопленной частоты и накопленной частости. Пусть x некоторое число. Тогда количество вариантов, значения которых меньше x , называется накопленной частотой: для x i
Признак называется дискретно варьируемым, если его отдельные значения (варианты) отличаются друг от друга на некоторую конечную величину (обычно целое число). Вариационный ряд такого признака называется дискретным вариационным рядом.
Таблица 1. Общий вид дискретного вариационного ряда частот
| Значения признака | x i | x 1 | x 2 | … | x n |
| Частоты | m i | m 1 | m 2 | … | m n |
Признак называется непрерывно варьирующим, если его значения отличаются друг от друга на сколь угодно малую величину, т.е. признак может принимать любые значения в некотором интервале. Непрерывный вариационный ряд для такого признака называется интервальным.
Таблица 2. Общий вид интервального вариационного ряда частот
Таблица 3. Графические изображения вариационного ряда
| Ряд | Полигон или гистограмма | Эмпирическая функция распределения | |
| Дискретный |  |  |  |
| Интервальный |  |  |  |
Для графического изображения вариационных рядов наиболее часто используются полигон, гистограмма, кумулятивная кривая и эмпирическая функция распределения.
В табл. 2.3 (Группировка населения России по размеру среднедушевого дохода в апреле 1994г.) представлен интервальный вариационный ряд
.
Удобно ряды распределения анализировать при помощи графического изображения, позволяющего судить и о форме распределения. Наглядное представление о характере изменения частот вариационного ряда дают полигон и гистограмма
.
Полигон используется при изображении дискретных вариационных рядов
.
Изобразим, например графически распределение жилого фонда по типу квартир, (табл. 2.10).
Таблица 2.10 - Распределение жилого фонда городского района по типу квартир (цифры условные).

Рис. Полигон распределения жилого фонда
На оси ординат могут наноситься не только значения частот, но и частостей вариационного ряда.
Гистограмма принимается для изображения интервального вариационного ряда . При построении гистограммы на оси абсцисс откладываются величины интервалов, а частоты изображаются прямоугольниками, построенными на соответствующих интервалах. Высота столбиков в случае равных интервалов должна быть пропорциональна частотам. Гистограмма – график, на котором ряд изображен в виде смежных друг с другом столбиков.
Изобразим графически интервальный ряд распределения, приведённый в табл. 2.11.
Таблица 2.11 - Распределение семей по размеру жилой площади, приходящейся на одного человека (цифры условные).
| N п/п | Группы семей по размеру жилой площади, приходящейся на одного человека | Число семей с данным размером жилой площади | Накопленное число семей |
| 1 | 3 – 5 | 10 | 10 |
| 2 | 5 – 7 | 20 | 30 |
| 3 | 7 – 9 | 40 | 70 |
| 4 | 9 – 11 | 30 | 100 |
| 5 | 11 – 13 | 15 | 115 |
| ВСЕГО | 115 | ---- | |

Рис. 2.2. Гистограмма распределения семей по размеру жилой площади, приходящейся на одного человека
Используя данные накопленного ряда (табл. 2.11), построим кумуляту распределения.

Рис. 2.3. Кумулята распределения семей по размеру жилой площади, приходящейся на одного человека
Изображение вариационного ряда в виде кумуляты особенно эффективно для вариационных рядов, частоты которых выражены в долях или процентах к сумме частот ряда.
Если при графическом изображении вариационного ряда в виде кумуляты оси поменять, то мы получим огиву . На рис. 2.4 приведена огива, построенная на основе данных табл. 2.11.
Гистограмма может быть преобразована в полигон распределения, если найти середины сторон прямоугольников и затем эти точки соединить прямыми линиями. Полученный полигон распределения изображён на рис. 2.2 пунктирной линией.
При построении гистограммы распределения вариационного ряда с неравными интервалами по оси ординат наносят не частоты, а плотность распределения признака в соответствующих интервалах.
Плотность распределения – это частота, рассчитанная на единицу ширины интервала, т.е. сколько единиц в каждой группе приходится на единицу величины интервала. Пример расчета плотности распределения представлен в табл. 2.12.
Таблица 2.12 - Распределение предприятий по числу занятых (цифры условные)
| N п/п | Группы предприятий по числу занятых, чел. | Число предприятий | Величина интервала, чел. | Плотность распределения |
| А | 1 | 2 | 3=1/2 | |
| 1 | До 20 | 15 | 20 | 0,75 |
| 2 | 20 – 80 | 27 | 60 | 0,25 |
| 3 | 80 – 150 | 35 | 70 | 0,5 |
| 4 | 150 – 300 | 60 | 150 | 0,4 |
| 5 | 300 – 500 | 10 | 200 | 0,05 |
| ВСЕГО | 147 | ---- | ---- |
Для графического изображения вариационных рядов может также использоваться кумулятивная кривая . При помощи кумуляты (кривой сумм) изображается ряд накопленных частот. Накопленные частоты определяются путём последовательно суммирования частот по группам и показывают, сколько единиц совокупности имеют значения признака не больше, чем рассматриваемое значение.

Рис. 2.4. Огива распределения семей по размеру жилой площади, приходящейся на одного человека
При построении кумуляты интервального вариационного ряда по оси абсцисс откладываются варианты ряда, а по оси ординат накопленные частоты.
Предмет математической статистики. Генеральная и выборочная совокупность.
Математическая статистика – раздел математики, который изучает способы отбора, группировки, систематизации и анализа статистических данных, для получения научно обоснованных выводов.
Статистические данные – числовые значения рассматриваемого признака изучаемых объектов, полученные как результат случайного эксперимента.
Математическая статистика тесно связана с теорией вероятностей, но в отличие от теории вероятностей, математическая модель эксперимента неизвестна. В математической статистике по статистическим данным необходимо установить неизвестное распределение вероятностей или объективно оценить параметры распределения.
Методы математической статистики позволяют строить оптимальные математические модели массовых, повторяющихся явлений. Связующим звеном между теорией вероятностей и математической статистикой являются предельные теоремы теории вероятностей.
В настоящее время статистические методы используются практически во всех отраслях народного хозяйства.
Генеральная совокупность – статистические данные всех изучаемых объектов (иногда – сами объекты). Часто генеральную совокупность рассматривают как СВ Х.
Выборка (выборочная совокупность) – статистические данные объектов, выбранных случайно из генеральной совокупности.
Объём выборки n (объём генеральной совокупности N ) – количество объектов, выбранных для изучения из генеральной совокупности (количество объектов в генеральной совокупности).
Примеры .
а) Статистическими данными могут быть: рост студентов; количество глаголов (или других частей речи) в отрывке текста определённой длины; средний балл аттестата; уровень интеллекта; число ошибок, допущенных диспетчером и т. п.
б) Генеральной совокупностью может быть: рост всех людей, разряды всех рабочих завода, частота употребления определённой части речи во всех произведениях изучаемого автора, средний балл аттестата всех выпускников и т. п.
в)Выборкой может быть: – рост 20 студентов, количество глаголов в выбранных произвольно 50 однородных отрывках текста длиной 500 словоупотреблений, средний балл аттестата 100 выпускников, выбранных случайно из школ города и т.п.
Выборка называется репрезентативной, если она верно отражает свойство генеральной совокупности. Репрезентативность выборки достигается случайностью отбора, когда все объекты генеральной совокупности имеют одинаковую вероятность быть отобранными.
Для того чтобы выборка была репрезентативной применяют различные способы отбора объектов изучения.
Виды отбора : простой, механический, серийный, типический.
Простой . Произвольно отбираются элементы из всей генеральной совокупности.
Механический отбор . Выбирают каждый 10 (25, 30 и т.п.) объект из генеральной совокупности.
Серийный . Проводится исследование в каждой серии (например, из текста выбирают 10 отрывков по 500 словоупотреблений- 10 серий).
Типический . Генеральную совокупность по определённому признаку разделяют на типические группы. Количество серий, извлекаемых из каждой такой группы, определяется удельным весом этой группы в генеральной совокупности.
Статистическое распределение выборки и его графическое изображение.
Пусть изучается СВ Х (генеральная совокупность) относительно некоторого признака. Проводится ряд независимых испытаний. В результате опытов СВ Х принимает некоторые значения. Совокупность полученных значений представляет собой выборку, а сами значения являются статистическими данными.
Первоначально проводят ранжирование выборки - расположение статистических данных выборки по неубыванию. Получаем вариационный ряд.
Вариационный ряд - проранжированная выборка.
Дискретный статистический ряд
Если генеральная совокупность является дискретной СВ, строится дискретный статистический ряд (статистическое распределение).
Пусть значение появилось в выборке раз,
Разa , …, - раз.
I-тая варианта выборки; - частота i-той варианты Частота показывает, сколько раз данная варианта появилась в выборке.
- относительная частота i-той варианты
(показывает какую часть выборки составляет ).
Статистическое распределение – это соответствие между вариантами выборки и их частотами или относительными частотами.
Для ДСВ статистическое распределение можно представить в виде таблицы – статистического ряда частот или статистического ряда относительных частот.
Статистический ряд частот Статистический ряд
относительных частот
| ........ | ||||
| ........ |
| ........ | ||||
| ........ |
Для наглядности представления статистического распределения выборки строят «графики» статистического распределения: полигон и гистограмму.
Полигон частот (относительных частот) – графическое изображение дискретного статистического ряда - ломаная линия, последовательно соединяющая точки [ для полигона относительных частот].
Пример. Исследователя интересуют знания абитуриентов по математике. Выбирают 10 абитуриентов и записывают их школьные оценки по этому предмету. Получена следующая выборка: 5;4;4;3;2;5;4;3;4;5.
а) Представить выборку в виде вариационного ряда;
б) построить статистический ряд частот и относительных частот;
в) изобразить полигон относительных частот для полученного ряда.
а) Проведем ранжирование выборки, т.е. расположим члены выборки по неубыванию. Получаем вариационный ряд: 2; 3; 3; 4; 4; 4; 4; 5; 5;5.
б) Построим статистический ряд частот (соответствие между вариантами выборки и их частотами) и статистический ряд относительных частот (соответствие между вариантами выборки и их относительными частотами)
| 0,1 | 0,2 | 0,4 | 0,3 |
Статистический ряд частот статистический ряд отн. частот
1+2+4+3=10=n 0,1+0,2+0,4+0,3=1.
Полигон относительных частот.
Наиболее простым способом обобщения статистического материала является построение рядов. Результатом сводки статистического исследования могут быть ряды распределения.
После определения группировочного признака, количества групп и интервалов группировки данные сводки и группировки представляются в виде рядов распределения и оформляются в виде статистических таблиц.
Ряд распределния является одним из видов группировок.
Рядом распределения в статистике называется упорядоченное распределение единиц совокупности на группы по какому-либо одному признаку: по качественному или количественному.
Виды рядов распределения
В зависимости от признака, положенного в основу образования ряда распределения различают атрибутивные и вариационные ряды распределения:
атрибутивными называют ряды распределения, построенные по качественными признакам;
вариационными называют ряды распределения, построенные в порядке возрастания или убывания значений количественного признака.
Вариационный ряд распределения состоит из двух столбцов. В первом столбце приводятся количественные значения варьирующегося признака, которые называются вариантами и обозначаются. Дискретная варианта - выражается целым числом. Интервальная варианта находится в пределах от и до. В зависимости от типа варианты можно построить дискретный или интервальный вариационный ряд. Во втором столбце содержится количество конкретных вариант, выраженное через частоты или частости:
частоты - это абсолютные числа, показывающие столько раз в совокупности встречается данное значение признака; сумма всех частот должна быть равна численности единиц всей совокупности;
частости - это частоты выраженные в процентах к итогу; сумма всех частостей выраженных в процентах должна быть равна 100% в долях единице.
Вариационный ряд характеризуется двумя элементами: вариантой (Х) и частотой (f). Варианта – это отдельное значение признака отдельной единицы или группы совокупности. Число, показывающее, сколько раз встречается то или иное значение признака, называется частотой. Если частота выражена относительным числом, то она называется частостью.
Вариационный ряд может быть:
интервальным, когда определены границы «от» и «до», интервальные ряды распределения можно представить графически в виде гистограммы;
дискретным, когда изучаемый признак характеризуется определенным числом.
Графическое изображение рядов распределения
Наглядно ряды распределения представляются при помощи графических изображений.
Ряды распределения изображаются в виде:
полигона;
гистограммы;
кумуляты;
При построении полигона на горизонтальной оси (ось абсцисс) откладывают значения варьирующего признака, а на вертикальной оси (ось ординат) - частоты или частости.
Для построения гистограммы по оси абсцисс указывают значения границ интервалов и на их основании строят прямоугольники, высота которых пропорциональна частотам (или частостям).
Распределение признака в вариационном ряду по накопленным частотам (частостям) изображается с помощью кумуляты.
Кумулята или кумулятивная кривая в отличие от полигона строится по накопленным частотам или частостям. При этом на оси абсцисс помещают значения признака, а на оси ординат - накопленные частоты или частости.
Огива строится аналогично кумуляте с той лишь разницей, что накопленные частоты помещают на оси абсцисс, а значения признака - на оси ординат.
Разновидностью кумуляты является кривая концентрации или график Лоренца. Для построения кривой концентрации на обе оси прямоугольной системы координат наносится масштабная шкала в процентах от 0 до 100. При этом на оси абсцисс указывают накопленные частости, а на оси ординат - накопленные значения доли (в процентах) по объему признака.
Лабораторная работа №1
По математической статистике
Тема: Первичная обработка экспериментальных данных
3. Оценка в баллах. 1
5. Контрольные вопросы.. 2
6. Методика выполнения лабораторной работы.. 3
Цель работы
Приобретение навыков первичной обработки эмпирических данных методами математической статистики.
На основе совокупности опытных данных выполнить следующие задания:
Задание 1. Построить интервальный вариационный ряд распределения.
Задание 2. Построить гистограмму частот интервального вариационного ряда.
Задание 3. Составить эмпирическую функцию распределения и построить график.
а) моду и медиану;
б) условные начальные моменты;
в) выборочную среднюю;
г) выборочную дисперсию, исправленную дисперсию генеральной совокупности, исправленное среднее квадратичное отклонение;
д) коэффициент вариации;
е) асимметрию;
ж) эксцесс;
Задание 5. Определить границы истинных значений числовых характеристик, изучаемой случайной величины с заданной надёжностью.
Задание 6. Содержательная интерпретация результатов первичной обработки по условию задачи.
Оценка в баллах
Задания 1-5 – 6 баллов
Задание 6 – 2 балла
Защита лабораторной работы (устное собеседование по контрольным вопросам и лабораторной работе) - 2 балла
Работа сдается в письменной форме на листах формата А4 и включает:
1) Титульный лист (Приложение 1)
2) Исходные данные.
3) Представление работы по указанному образцу.
4) Результаты расчетов (выполненные вручную и/или с помощью MS Excel) в указанном порядке.
5) Выводы - содержательная интерпретация результатов первичной обработки по условию задачи.
6) Устное собеседование по работе и контрольным вопросам.
5. Контрольные вопросы
Методика выполнения лабораторной работы
Задание 1. Построить интервальный вариационный ряд распределения
Для того, чтобы статистические данные представить в виде вариационного ряда с равноотстоящими вариантами необходимо:
1.В исходной таблице данных найти наименьшее и наибольшее значения.
2.Определить размах варьирования :
3. Определить длину интервала h, если в выборке до 1000 данных, используют формулу: ![]() , где n – объем выборки – количество данных в выборке; для вычислений берут lgn).
, где n – объем выборки – количество данных в выборке; для вычислений берут lgn).
Вычисленное отношение округляют до удобногоцелого значения .
4. Определить начало первого интервала для четного числа интервалов рекомендуют брать величину ; а для нечетного числа интервалов .
5. Записать интервалы группировок и расположить их в порядке возрастания границ
, ![]() ,………., ,
,………., ,
где - нижняя граница первого интервала. За берется удобное число не большее , верхняя граница последнего интервала должна быть не меньше . Рекомендуется, чтобы интервалы содержали в себе исходные значения случайной величины и выделять от 5 до 20 интервалов.
6. Записать исходные данные по интервалам группировок, т.е. подсчитать по исходной таблице число значений случайной величины, попадающих в указанные интервалы. Если некоторые значения совпадают с границами интервалов, то их относят либо только к предыдущему, либо только к последующему интервалу.
Замечание 1. Интервалы необязательно брать равными по длине. На участках, где значения располагаются гуще, удобнее брать более мелкие короткие интервалы, а там где реже - более крупные.
Замечание 2 .Если для некоторых значений получены “нулевые”, либо малые значения частот , то необходимо перегруппировать данные, укрупняя интервалы (увеличивая шаг ).
При обработке больших массивов информации, что особенно актуально при проведении современных научных разработок, перед исследователем стоит серьезная задача правильной группировки исходных данных. Если данные имеют дискретный характер, то проблем, как мы видели, не возникает – необходимо просто подсчитать частотукаждого признака. Если же исследуемый признак имеет непрерывный характер (что имеет большее распространение на практике), то выбор оптимального числа интервалов группировки признака является отнюдь не тривиальной задачей.
Для группировки непрерывных случайных величин весь вариационный размах признакаразбивают на некоторое количество интервалов к.
Сгруппированным интервальным (непрерывным ) вариационным рядом называют ранжированные по значению признака интервалы (), гдеуказанные вместе с соответствующими частотами () числа наблюдений, попавших в г"-й интервал, или относительными частотами ():
|
Интервалы значений признака |
||||||
|
Частота mi |
Гистограмма и кумулята {огива), уже подробно рассмотренные нами, являются прекрасным средством визуализации данных, позволяющим получить первичное представление о структуре данных. Такие графики (рис. 1.15) строятся для непрерывных данных так же, как и для дискретных, только с учетом того, что непрерывные данные сплошь заполняют область своих возможных значений, принимая любые значения.

Рис. 1.15.
Поэтому столбцы на гистограмме и кумуляте должны соприкасаться, не иметь участков, куда не попадают значения признака в пределах всех возможных (т.е. гистограмма и кумулята не должны иметь "дырок" по оси абсцисс, в которые не попадают значения изучаемой переменной, как на рис. 1.16). Высота столбика соответствует частоте– числу наблюдений, попавших в данный интервал, или относительной частоте– доле наблюдений. Интервалы не должны пересекаться и имеют, как правило, одинаковую ширину.

Рис. 1.16.
Гистограмма и полигон являются аппроксимациями кривой плотности вероятности (дифференциальной функции) f(x) теоретического распределения, рассматриваемой в курсе теории вероятностей . Поэтому их построение имеет такое важное значение при первичной статистической обработке количественных непрерывных данных – по их виду можно судить о гипотетическом законе распределения.
Кумулята – кривая накопленных частот (частостей) интервального вариационного ряда. С кумулятой сопоставляется график интегральной функции распределения F(x) , также рассматриваемой в курсе теории вероятностей.
В основном понятия гистограммы и кумуляты связывают именно с непрерывными данными и их интервальными вариационными рядами, так как их графики являются эмпирическими оценками функции плотности вероятности и функции распределения соответственно.
Построение интервального вариационного ряда начинают с определения числа интервалов k. И эта задача, пожалуй, является самой сложной, важной и неоднозначной в изучаемом вопросе.
Число интервалов не должно быть слишком малым, так как при этом гистограмма получается слишком сглаженной (oversmoothed), теряет все особенности изменчивости исходных данных – на рис. 1.17 можно увидеть, как те же данные, по которым построены графики рис. 1.15, использованы для построения гистограммы с меньшим числом интервалов (левый график).
В то же время число интервалов не должно быть слишком велико – иначе мы не сможем оценить плотность распределения изучаемых данных по числовой оси: гистограмма получится недосглажепная (undersmoothed), с незаполненными интервалами, неравномерная (см. рис. 1.17, правый график).

Рис. 1.17.
Как же определить наиболее предпочтительное число интервалов?
Еще в 1926 г. Герберт Стерджес (Herbert Sturges) предложил формулу для вычисления количества интервалов, на которые необходимо разбить исходное множество значений изучаемого признака . Эта формула поистине стала сверхпопулярной – большинство статистических учебников предлагают именно ее, по умолчанию ее используют и множество статистических пакетов. Насколько это оправдано и во всех ли случаях – является весьма серьезным вопросом.
Итак, на чем основана формула Стерджеса?
Рассмотрим биномиальное распределение }
 Могильники Чернобыля: радиоактивные отходы зоны отчуждения Где находится техника чернобыля
Могильники Чернобыля: радиоактивные отходы зоны отчуждения Где находится техника чернобыля Девочка заговорила на иностранном языке после комы
Девочка заговорила на иностранном языке после комы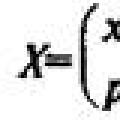 Сравнение законов распределения вероятностей
Сравнение законов распределения вероятностей