Статистика для психологов онлайн статистические расчеты. Нахождение моды и медианы. Данные и их разновидности
Математические методы в психологии используются для обработки данных исследований и установления закономерностей между изучаемыми явлениями. Даже простейшее исследование не обходится без математической обработки данных.
Обработка данных может осуществляться вручную, а может - с применением специального программного обеспечения. Итоговый результат может выглядеть как таблица; методы в психологии позволяют и графически отображать полученные данные. Для разных (количественных, качественных и порядковых) применяются разные инструменты оценки.
Математические методы в психологии включают в себя как позволяющие установить числовые зависимости, так и методы статистической обработки. Остановимся подробнее на наиболее распространенных из них.
Для того чтобы измерить данные, прежде всего, необходимо определиться со шкалой измерений. И здесь используются такие математические методы в психологии, как регистрация и шкалирование , заключающиеся в выражении исследуемых явлений в числовых показателях. Выделяют несколько типов шкал. Однако для математической обработки пригодны лишь некоторые из них. Это, главным образом, количественная шкала, которая позволяет измерять степень выраженности конкретных свойств у исследуемых объектов и в числовом отношении выражать разницу между ними. Простейший пример - измерение коэффициента интеллекта. Количественная шкала позволяет проводить операцию ранжирования данных (см. далее). При ранжировании данные из количественной шкалы переводятся в номинальную (например, низкое, среднее или высокое значение показателя), при этом обратный переход уже невозможен.
Ранжирование - это распределение данных в порядке убывания (возрастания) признака, который оценивается. При этом используется количественная шкала. Каждому значению присваивается определенный ранг (показателю с минимальным значением - ранг 1, следующему значению - ранг 2, и так далее), после чего становится возможным перевод значений из количественной шкалы в номинальную. Например, измеряемый показатель - уровень тревожности. Было протестировано 100 человек, полученные результаты проранжированы, и исследователь видит, сколько человек имеют низкий (высокий или средний) показатель. Однако такой способ представления данных влечет за собой частичную утрату информации по каждому респонденту.
Корреляционный анализ - это установление взаимосвязи между явлениями. При этом измеряется, как изменится одного показателя при изменении показателя, во взаимосвязи с которым он находится. Корреляция рассматривается в двух аспектах: по силе и по направлению. Она может быть положительной (при возрастании одного показателя возрастает и второй) и отрицательной (при возрастании первого второй показатель убывает: например, чем выше уровень тревожности у индивида, тем меньше вероятность, что он займет лидирующее положение в группе). Зависимость может быть линейной, или, что бывает чаще, выражаться кривой. Связи, которые помогают установить могут быть неочевидны на первый взгляд, если применяются иные методы математической обработки в психологии. В этом его главное достоинство. К недостаткам можно отнести большую трудоемкость в связи с необходимостью использования немалого числа формул и тщательных вычислений.
Факторный анализ - это еще один который позволяет прогнозировать вероятное влияние различных факторов на исследуемый процесс. При этом все факторы воздействия изначально принимаются как имеющие равное значение, а степень их влияния вычисляется математически. Такой анализ позволяет установить общую причину изменчивости нескольких явлений сразу.
Для отображения полученных данных могут применяться методы табулирования (создания таблиц) и графического построения (диаграммы и графики, которые не только дают наглядное представление о полученных результатах, но и позволяют прогнозировать ход процесса).
Главным условиями, при которых вышеперечисленные математические методы в психологии обеспечивают достоверность исследования, являются наличие достаточной выборки, точность измерений и правильность производимых вычислений.
Статистика в психологии (statistics in psychology)
Первое применение С. в психологии часто связывают с именем сэра Фрэнсиса Гальтона. В психологии под «статистикой» понимается применение количественных мер и методов для описания и анализа результатов психол. исслед. Психологии как науке С. необходима. Регистрация, описание и анализ количественных данных позволяют проводить обоснованные сравнения, опирающиеся на объективные критерии. Применяемая в психологии С. обычно состоит из двух разделов: описательной (дескриптивной) статистики и теории статистического вывода.
Описательная статистика.
Описательная С. включает в себя методы орг-ции, суммирования и описания данных. Дескриптивные показатели позволяют быстро и эффективно представлять большие совокупности данных. К наиболее часто используемым описательным методам относятся частотные распределения, меры центральной тенденции и меры относительного положения. Регрессия и корреляции применяются для описания связей между переменными.
Частотнее распределение показывает, сколько раз каждый качественный или количественный показатель (либо интервал таких показателей) встречается в массиве данных. Кроме того, нередко приводятся относительные частоты - процент ответов каждого типа. Частотное распределение обеспечивает быстрое проникновение в структуру данных, к-рого было бы трудно достичь, работая непосредственно с первичными данными. Для наглядного представления частотных данных часто используются разнообразные виды графиков.
Меры центральной тенденции - это итоговые С., описывающие то, что яв-ся типичным для распределения. Мода определяется как наиболее часто встречающееся наблюдение (значение, категория и т. д.). Медиана - это значение, к-рое делит распределение пополам, так что одна его половина включает все значения выше медианы, а другая - все значения ниже медианы. Среднее вычисляется как среднее арифметическое всех наблюденных значений. Какая из мер - мода, медиана или среднее - будет лучше всего описывать распределение, зависит от его формы. Если распределение симметричное и унимодальное (имеющее одну моду), среднее медиана и мода будут просто совпадать. На среднее особенно влияют «выбросы», сдвигая его величину в сторону крайних значений распределения, что делает среднее арифметическое наименее полезной мерой сильно скошенных (асимметричных) распределений.
Др. полезными описательными характеристиками распределений служат меры изменчивости, т. е. того, в какой степени различаются значения переменной в вариационном ряду. Два распределения могут иметь одинаковые средние, медианы и моды, но существенно различаться по степени изменчивости значений. Изменчивость оценивается двумя С.: дисперсией и стандартным отклонением.
Меры относительного положения включают в себя процентили и нормированные оценки, используемые для описания местоположения конкретного значения переменной относительно остальных ее значений, входящих в данное распределение. Велковиц с соавторами определяют процентиль как «число, показывающее процент случаев в определенной референтной группе с равными или меньшими оценками». Т. о., процентиль дает более точную информ., чем просто сообщение о том, что в данном распределении некое значение переменной попадает выше или ниже среднего, медианы или моды.
Нормированные оценки (обычно называемые z-оценками) выражают отклонение от среднего в единицах стандартного отклонения (σ). Нормированные оценки полезны тем, что их можно интерпретировать относительно стандартизованного нормального распределения (z-распределения) - симметричной колоколообразной кривой с известными свойствами: средним, равным 0, и стандартным отклонением, равным 1. Так как z-оценка имеет знак (+ или -), она сразу показывает, лежит ли наблюденное значение переменной выше или ниже среднего (m). А поскольку нормированная оценка выражает значения переменной в единицах стандартного отклонения, она показывает, насколько редким яв-ся каждое значение: примерно 34% всех значений попадает в интервал от т до т + 1σ и 34% - в интервал от т до т - 1σ; по 14% - в интервалы от т + 1σ до т + 2σ и от т - 1σ до т - 2σ; и по 2% - в интервалы от т + 2σ до т + 3σ и от т - 2σ до т - 3σ.
Связи между переменными. Регрессия и корреляция относятся к тем способам, к-рые чаще всего используются для описания связей между переменными. Два разных измерения, полученных по каждому элементу выборки, можно отобразить в виде точек в декартовой системе координат (х, у) - диаграммы рассеяния, являющейся графическим представлением связи между этими измерениями. Часто эти точки образуют почти прямую линию, свидетельствующую о линейной связи между переменными. Для получения линии регрессии - мат. уравнения линии наилучшего соответствия множеству точек диаграммы рассеяния - используются численные методы. После выведения линии регрессии появляется возможность предсказывать значения одной переменной по известным значениям другой и, к тому же, оценивать точность предсказания.
Коэффициент корреляции (r) - это количественный показатель тесноты линейной связи между двумя переменными. Методики вычисления коэффициентов корреляции исключают проблему сравнения разных единиц измерения переменных. Значения r изменяются в пределах от -1 до +1. Знак отражает направление связи. Отрицательная корреляция означает наличие обратной зависимости, когда с увеличением значений одной переменной значения др. переменной уменьшаются. Положительная корреляция свидетельствует о прямой зависимости, когда при увеличении значений одной переменной увеличиваются значения др. переменной. Абсолютная величина r показывает силу (тесноту) связи: r = ±1 означает прямолинейную зависимость, а r = 0 указывает на отсутствие линейной связи. Величина r2 показывает процент дисперсии одной переменной, к-рый можно объяснить вариацией др. переменной. Психологи используют r2, чтобы оценить полезность конкретной меры для предсказания.
Коэффициент корреляции Пирсона (r) предназначен для интервальных данных, полученных в отношении предположительно нормально распределенных переменных. Для обработки др. типов данных имеется целый ряд др. корреляционных мер, напр. точечно-бисериальный коэффициент корреляции, коэффициент j и коэффициент ранговой корреляции (r) Спирмена. Корреляции часто используются в психологии как источник информ. для формулирования гипотез эксперим. исслед. Множественная регрессия, факторный анализ и каноническая корреляция образуют родственную группу более современных методов, ставших доступными практикам благодаря прогрессу в области вычислительной техники. Эти методы позволяют анализировать связи между большим числом переменных.
Теория статистического вывода
Этот раздел С. включает систему методов получения выводов о больших группах (фактически, генеральных совокупностях) на основе наблюдений, проведенных в группах меньшего размера, называемых выборками. В психологии статистический вывод служит двум главным целям: 1) оценить параметры генеральной совокупности по выборочным статистикам; 2) оценить шансы получения определенного паттерна результатов исследования при заданных характеристиках выборочных данных.
Среднее является наиболее часто оцениваемым параметром генеральной совокупности. В силу самого способа вычисления стандартной ошибки, выборки большего объема обычно дают меньшие стандартные ошибки, что делает статистики, вычисленные по большим выборкам, несколько более точными оценками параметров генеральной совокупности. Пользуясь стандартной ошибкой среднего и нормированными (стандартизованными) распределениями вероятностей (такими как t-распределение), можно построить доверительные интервалы - области значений с известными шансами попадания в них истинного генерального среднего.
Оценивание результатов исследования. Теорию статистического вывода можно использовать для оценки вероятности того, что частные выборки принадлежат известной генеральной совокупности. Процесс статистического вывода начинается с формулирования нулевой гипотезы (H0), состоящей в предположении, что выборочные статистики получены из определенной совокупности. Нулевая гипотеза сохраняется или отвергается в зависимости от того, насколько вероятным яв-ся полученный результат. Если наблюдаемые различия велики относительно величины изменчивости выборочных данных, исследователь обычно отвергает нулевую гипотезу и делает вывод о крайне малых шансах того, что наблюдаемые различия обязаны своим происхождением случаю: результат является статистически значимым. Вычисляемые критериальные статистики с известными распределениями вероятностей выражают отношение между наблюдаемыми различиями и изменчивостью (вариабельностью).
Параметрические статистики. Параметрические С. могут использоваться в тех случаях, когда удовлетворяются два требования: 1) в отношении изучаемой переменной известно или, по крайней мере, можно предположить, что она имеет нормальное распределение; 2) данные представляют собой интервальные измерения или измерения отношений.
Если среднее и стандартное отклонение генеральной совокупности известно (хотя бы предположительно), можно определить точное значение вероятности получения наблюдаемого различия между известным генеральным параметром и выборочной статистикой. Нормированное отклонение (z-оценку) можно найти путем сравнения со стандартизованной нормальной кривой (называемой также z-распределением).
Поскольку исследователи часто работают с малыми выборками и поскольку параметры генеральной совокупности редко известны, стандартизованные t-распределения Стьюдента обычно используются чаще нормального распределения. Точная форма t-распределения варьирует в зависимости от объема выборки (точнее, от числа степеней свободы, т. е. числа значений, к-рые можно свободно изменять в данной выборке). Семейство t-распределений можно использовать для проверки нулевой гипотезы, состоящей в том, что две выборки были извлечены из одной и той же совокупности. Такая нулевая гипотеза типична для исследований с двумя группами испытуемых, напр. эксперим. и контрольной.
Когда в исслед. задействовано больше двух групп, можно применить дисперсионный анализ (F-критерий). F - это универсальный критерий, оценивающий различия между всеми возможными парами исследуемых групп одновременно. При этом сравниваются величины дисперсии внутри групп и между группами. Существует множество post hoc методик выявления парного источника значимости F-критерия.
Непараметрические статистики. Когда не удается соблюсти требования адекватного применения параметрических критериев или когда собираемые данные являются порядковыми (ранговыми) или номинальными (категориальными), используют непараметрические методы. Эти методы параллельны параметрическим в том, что касается их применения и назначения. Непараметрические альтернативы t-критерию включают U-критерий Манна-Уитни, критерий Уилкоксона (W) и критерий с2 для номинальных данных. К непараметрическим альтернативам дисперсионного анализа относятся критерии Краскела - Уоллеса, Фридмана и с2. Логика применения каждого непараметрического критерия остается той же самой: соответствующая нулевая гипотеза отвергается в том случае, если расчетное значение критериальной статистики выходит за пределы заданной критической области (т. е. оказывается менее вероятным, чем предполагалось).
Так как все статистические выводы основаны на оценках вероятности, возможны два ошибочных исхода: ошибки I рода, при к-рых отвергается истинная нулевая гипотеза, и ошибки II рода, при к-рых сохраняется ложная нулевая гипотеза. Первые имеют следствием ошибочное подтверждение гипотезы исслед., а последние - неспособность распознать статистически значимый результат.
См. также Дисперсионный анализ, Меры центральной тенденции, Факторный анализ, Измерение, Методы многомерного анализа, Проверка нулевой гипотезы, Вероятность, Статистический вывод
А. Майерс
Смотреть что такое "Статистика в психологии (statistics in psychology)" в других словарях:
Содержание 1 Биомедицина и науки о жизни (Biomedical and Life Sciences) 2 З … Википедия
Эта статья содержит незавершённый перевод с иностранного языка. Вы можете помочь проекту, переведя её до конца. Если вы знаете, на каком языке написан фрагмент, укажите его в этом шаблоне … Википедия
Математическая статистика - Наука о том, как систематизировать и использовать статистические данные для научных и прикладных целей.
Математическая статистика в психологии
В психологии как науке математическая статистика применяется очень широко. С помощью тех или иных способов, например тестирования, разным особенностям поведения человека сопоставляются числа (шкалируются), и с этими числами уже работают методами математической статистики. После применения этих методов получаются новые данные, которые следует осмыслить.
Без применения математической статистики психология была бы довольно плоской и малоинформативной наукой, основанной на домыслах и спекуляциях (как это, например, имеет место быть в психоанализе). Разумеется, использование математической статистики не является "противоядием" против домыслов и спекуляций, однако предмет рассуждений становится значительно богаче.
Рассмотрим типичный и простой случай использования математической статистики. Допустим, кто-то провел исследование группы школьников. В числе прочих были найдены такие параметры, как экстраверсия-интроверсия и уровень интеллекта. Психолога-исследователя заинтересовало, а как связаны эти параметры между собой. Правда ли, что интроверты в среднем умнее экстравертов? Для этого группу испытуемых (выборку) можно поделить на две подгруппы: экстравертов и интровертов. Далее по каждой подгруппе находится среднее арифметическое по уровню интеллекта. Если, скажем, у интровертов в среднем IQ выше, значит, они умнее экстравертов. Это один подход. Другой может состоять в том, чтобы разделить испытуемых на подгруппу с высоким IQ (более 100) и низким (менее 100), а потом посчитать среднее по экстраверсии-интроверсии в каждой группе. Третий подход может состоять в том, чтобы вместо деления на подгруппы и высчитывания в них средних задействовать более сложный метод – корреляционный анализ. Все эти три методы по-разному, но покажут одну и ту же связь.
Математическая статистика позволяет делать интересные, иногда удивительные открытия. Продолжим наш гипотетический пример. Предположим, что психолог нашел парадоксальный результат, который противоречит с его прошлым опытом, знаниями. Скажем, он установил, что в одной школе экстраверты умнее интровертов, хотя во всех других школах было наоборот. Почему так? Дотошный психолог может начать свое расследование и установит, что, к примеру, это связано с тем, что в этой школе экстраверты ходят на факультатив по физике (потому что там «заводной учитель») и развивают свой интеллект, а интроверты ходят на факультатив по литературе (потому что там «душевный учитель»), где развивают другие качества своей души. Может ли, например, психоаналитик дойти до такого открытия? Крайне маловероятно.
В психологических исследованиях в расчет берутся не только такие чисто психологические параметры, как, скажем, интеллект, экстравертированность или тревожность. Могут использоваться и такие данные, как возраст, пол, уровень образования, рост, вес, физическая сила, политические взгляды, стаж работы и многое другое. Часто бывает, что именно без таких непсихологических показателей исследования оказываются неполными, малоинформативными. Также часто бывает, что представители других наук (например, социологии или биологии) тоже используют психологические параметры в своих исследованиях.
Математическая статистика позволяет много вещей:
Практические психологи в своей работе обычно ограничиваются нахождением средней арифметической, с разделением на подгруппы (как в примере выше). Ученые-психологи используют самый разнообразный арсенал методов математической статистики. Рассмотрим основные.
Нахождение средней арифметической
Самый банальный и простой метод. Показатели (например, рост испытуемых) складываются, затем делятся на число испытуемых. Несмотря на простоту, метод, конечно, очень информативный и наглядный. Наглядность – важное качество метода для практического психолога. Когда он представляет результаты своих исследований заказчику (например, директору школы), тот далеко не всегда способен понять сущность корреляционного или дисперсионного анализа. Разделение испытуемых на подгруппы по произвольному основанию усиливает потенциал средней арифметической, позволяя закрыть большинство потребностей исследователя.
Нахождение моды и медианы
Предположим, мы обследовали 1000 студентов – измеряли их рост с точностью до сантиметра. Эти данные заносили в таблицу. Если в таблице чаще всего встречается значение, скажем, 172 сантиметра, это и есть мода нашей выборки. Аналогичным, кстати, образом слово "мода" используется и в быту: если в этом сезоне чаще всего можно встретить шапочки красного цвета, значит это мода, хотя на долю этих шапочек может приходиться всего лишь 20 или 30 процентов.
В психологических исследованиях обычно мода находится где-то рядом со средней арифметической. Если мода 172 см, то и средняя будет около того. Чем больше выборка, тем ближе мода и среднее арифметическое.
Далее. Предположим, мы поделили своих студентов на две равные группы: в первой группе 500 низких студентов, во второй группе 500 высоких студентов. Значение роста, которое приходится на 500-го или 501-го студента и есть медиана . Медиана обычно тоже находится рядом со средней арифметической.
Выявление рассеяния значений
Как известно, средняя температура по больнице не так уж важна. И в хорошей больнице, где лечат хорошо, средняя температура может быть 36,6°C; и в плохой может быть такая же: просто у кого-то жар в 40 °C, а кто-то уже умер, и у него 18°C.
Самый простой способ оценить рассеяние выборки – найти ее размах (иначе – разброс). Если в нашей выборке самый низкий студент имеет рост 148 см, а самый высокий 205 см, значит размах выборки составит 205-148=57 см. Это величина важна в первую очередь для того, чтобы оценить, в каких рамках вообще меняется данный параметр.
Далее. Предположим такую ситуацию. Лет через двадцать по прихоти какого-нибудь богатого человека у него появятся дети-клоны. Ещё через двадцать лет они поступят в университет. И будет в университете выборка студентов объемом 1000 человек, из которых 998 имеют рост 177 см, один – 148 см, один – 205 см. По основным параметрам – средней арифметической, моде, медиане, размаху – эта выборка может не отличаться от другой выборки студентов (там будут такие же значения). Но при этом во второй (нормальной) выборке будет какое-то количество студентов с ростом 150-160 см, какое-то с ростом 180-190 см и т.д. Так что же, получается, что с точки зрения математической статистики эти группы одинаковые?

Одного взгляда на этот рисунок достаточно, чтобы понять, что группы различаются по рассеянию значений. Поэтому в статистике есть более точный инструмент для оценки рассеивания – дисперсия . Дисперсию исчисляют так: находят среднее арифметическое, потом для каждого случая находят отклонение от среднего, возводят это значение в квадрат, в конце делят на общее количество случаев. Из значения дисперсии легко получить стандартное отклонение : оно есть квадратный корень из дисперсии. Стандартное отклонение обозначает, что понятно, стандартное отклонение: то есть мера того, насколько в среднем значения вообще отклоняются.
Стандартное отклонение измеряется в тех же самых единицах, что и сам параметр. В первой нашей гипотетической группе, где почти все студенты одинаковы, стандартное отклонение будет крайне малым (менее 1 см). Во второй группе будет значительно больше – сантиметров 10-15. Если нам скажут, что средний рост студентов составляет 175 см при стандартном отклонении 12 см, мы будем знать, что большинство студентов (примерно 2/3) находится в диапазоне от 163 до 187 см.
t-критерий Стьюдента
Предположим, мы решили провести эксперимент такого рода. Мы взяли группу испытуемых. Перед началом эксперимента протестировали их, скажем, на уровень креативности. Далее они целый месяц занимались по часу в день рисованием. В конце эксперимента мы опять проверили их на уровень креативности. Был замечен результат, но довольно малый, и скептики стали нам заявлять, что уровень креативности не повысился, небольшое повышение средней арифметической это всего лишь случайность.Для таких ситуаций придумали разные критерии. Один из них – наиболее популярный – это t-критерий Стьюдента. В числителе у него разница средних арифметических. В знаменателе – корень из суммы квадратов дисперсий (имеется в виду первый и второй случай тестирования). Чем больше разница между средними арифметическими, тем лучше (наш труд не остался напрасным), и чем меньше разброс значений в обоих случаях диагностики, тем тоже лучше: когда разброс значений больше, тогда и случайные колебания тоже больше.
Для применения данного критерия есть существенное ограничение – распределение показателей должно быть близко к так называемому нормальному
(колоколообразному).

Существуют специальные критерии для определения степени нормальности распределения.
Корреляция
В психологии, как наверное ни в одной другой науке, любят находить коэффициенты корреляции. Существует несколько разных подходов, в том числе и для нормального, и для не нормального распределения. Все они показывают степень зависимости одного параметра от другого. Если один параметр (например, вес человека) сильно зависит от другого параметра (например, рост человека), тогда коэффициент корреляции будет близок к +1. Если зависимость обратная (например, чем человек выше, тем менее ловок он), тогда коэффициент корреляции будет стремиться к -1. Если зависимости нет (скажем, удачливость при игре в карты не зависит от роста человека), тогда коэффициент корреляции будет около 0.
Если взять группу испытуемых, зафиксировать их рост и вес, а потом результаты перенести на двухмерный график, то получится примерно следующая картина, которая свидетельствует о том, что корреляция положительная, примерно на уровне +0.5.

Факторный анализ
Наиболее, пожалуй, таинственный анализ. Некоторая загадочность его объясняется тем, что сам он предназначен для того, чтобы найти новый параметр, который многое объясняет, но при этом непосредственно в ходе эксперимента не исследовался. Как правило, в ходе факторного анализа находятся наиболее влиятельные параметры, от которых зависят более мелкие, частные.Допустим, мы проводили исследование со школьниками. В числе прочих фиксировались следующие параметры: общая успеваемость, успеваемость по точным предметам, успеваемость по гуманитарным предметам, объем кратковременной памяти, объем и распределение внимания, активность мышления, пространственное воображение, общая осведомленность, общительность, тревожность. Если применить корреляционный анализ и составить так называемую матрицу корреляций (где отражена связь каждого параметра с каждым), то можно увидеть, что большинство этих параметров между собой хорошо коррелирует. Исключение составляет последние два, которые с другими связаны слабо. Уже глядя на эту матрицу можно предположить, что за большинством параметров стоит некий один общий (сверх-параметр), который на них на всех влияет. Мы проводим процедуру факторного анализа, и после этого в нашей матрице появляется еще один столбец – столбец без названия. Этот загадочный параметр очень хорошо коррелирует со всеми (кроме общительности и тревожности). После некоторого творческого раздумья психолог приходит к единственно возможной здесь интерпретации – загадочный параметр это есть интеллект. Он и влияет на все остальное, влияние его сильное, хотя и не стопроцентное.
Существуют методы факторного анализа, которые помогают выявить не один, а несколько факторов, которые влияют на другие параметры. Часто так бывает, конечно, что загадочный параметр оказывается не таким уж и загадочным, а полностью совпадает с одним из тех параметров, которые фиксировались. Но иногда бывает и так, что придется долго поломать голову прежде, чем удастся интерпретировать этот секретный фактор.
Факторный анализ применяется в основном учеными для глубокого понимания предмета исследования. При этом следует учитывать, что для точности результата необходимо довольно большое количество испытуемых: желательно, чтобы количество испытуемых в разы превышало количество параметров.
С помощью факторного анализа можно изучать качество психологических тестов. Если взять, например, какой-нибудь личностный опросник с несколькими параметрами, подвергнуть эти параметры факторному анализу, то может всплыть некий странный общий фактор, влияющий на все параметры. Значимого психологического смысла он может не иметь – это просто тенденция испытуемого отвечать так или иначе по формальному признаку (кто-то отвечает вдумчиво, кто-то склонен выбирать первые пункты из вариантов, кто-то последние). Большое влияние этого общего фактора может говорить о недостаточно качественной проработке заданий.
Литература
Ермолаев О. Ю. Математическая статистика для психологов: Учебник. - 2-е изд. испр. - М.: МПСИ, Флинта, 2003. - 336 с.Математические методы в психологии используются для обработки данных исследований и установления закономерностей между изучаемыми явлениями. Даже простейшее психологическое или педагогическое исследование не обходится без математической обработки данных, которая может осуществляться вручную, а чаще – с применением специального программного обеспечения (MS Excel или статистические пакеты).
При решении задач математической статистики в психологии затрагиваются как стандартные темы (см. примеры), так и некоторые дополнительные : выявление различий в уровне признака, оценка достоверности сдвига значсений, многофункциональные критерии. Ниже мы рассмотрим примеры и по тем, и по другим темам.
Если вы испытываете трудности с решением заданий по математической статистике или обработкой данных проведенных исследований, обращайтесь, мы готовы помочь . Стоимость задачи от 100 рублей, срок от 1 дня, оформление в Word.
Полезная страница? Сохрани или расскажи друзьям
Примеры решений: математические методы в психологии
Исследование выборки
Задача 1.
В данной выборке найти моду, медиану, среднее арифметическое, разброс, дисперсию:
3, 2, 15, 5, 10, 8, 6, 3, 10, 8, 15, 5, 10, 8, 5, 3.
Непараметрические критерии выявления различий
Задача 2.
У 26 юношей – студентов физического и психологического факультетов был измерен уровень вербального интеллекта по методике Векслера. Можно ли утверждать, что одна из групп превосходит другую по уровню вербального интеллекта?
Физики 132, 134, 124, 132, 135, 132, 131, 132, 121, 127, 136, 129, 136, 136
Психологи 126, 127, 132, 120, 119, 126, 120, 123, 120, 116, 123, 115
Задача 3.
Были протестированы две группы студентов. Тест содержал 50 вопросов. Указано число правильных ответов каждого участника теста. Можно ли утверждать, что одна из групп превзошла другую группу по результатам теста?
Группа 1 45, 40, 44, 38
Группа 2 44, 43, 40, 37, 36
Задача 4.
Четыре группы испытуемых выполняли тест Бурдона в разных экспериментальных условиях.
№ испытуемых 1 группа 2 группа 3 группа 4 группа
1 28 49 38 23
2 20 15 27 27
3 37 36 33 29
4 31 12 45 33
Необходимо установить: наблюдается ли тенденция к увеличению ошибок при выполнении теста Бурдона разными испытуемыми в зависимости от условий его выполнения?
Задача 5.
При измерении пространственных порогов тактильной чувствительности получены следующие величины порогов тактильной чувствительности
«Мужчины» «Женщины»
39 32
36 30
31 28
35 30
29 33
34 37
38 28
27
Отличаются ли между собой пороги мужчин и женщин?
Задача 6.
В исследовании было установлено, что испытуемые по разному относятся к наказаниям, которые совершают к их детям разные люди. Можно ли говорить о тенденции в изменении оценок наказаний разными людьми? Указать название сдвига. Представить данные в виде гистограммы.
Оценки степени согласия с утверждениями о допустимости телесных наказаний в группе испытуемых даны в файле.
Ранговая корреляция
Задача 7. Психолог просит супругов проранжировать семь личностных черт, имеющих определяющее значение для семейного благополучия. Задача заключается в том, чтобы определить, в какой степени совпадают оценки супругов по отношению к ранжируемым качествам. Заполните таблицу и, посчитав коэффициент ранговой корреляции Спирмена, ответьте на поставленный вопрос.
Задача 8. Проранжируйте качества личности так, чтобы наиболее значимому для вас качеству приписывался 1-й ранг, менее значимому 2-й и т.д. Это будет первый столбик, теперь проранжируйте эти качества по значимости на работе. Коррелируют ли данные между собой.
Критерий согласия $\chi^2$
Задача 9. В исследовании порогов социального атома студентов – психологов просили определить, с какой частотой встречаются в записной книжке их мобильного телефона мужские и женские имена. Определите, отличается ли распределение, полученное по Вашей записной книжке, от равномерного распределения.
Задача 10. Различаются ли учащиеся 1 и 2 класса по уровню овладения внутренним планом действия (ВПД)
Задача 11. В исследовании изучалась проблема психологического состояния детей в полных и неполных семьях. Результаты исследования приведены в таблице. Даны высокие уровни показателей в классах «Тревожность» и «Агрессивность» и низкий уровень показателей в классе «Благоприятная семейная обстановка» Полные семьи (47 чел.): Тревожность - 16, Агрессивность – 22, Благоприятная семейная ситуация - 28 Неполные семьи (13 чел.): Тревожность – 7, Агрессивность – 5, Благоприятная семейная ситуация - 6 Вопрос: Достоверно ли отличаются доли детей с высоким уровнем показателей «Тревожность» и «Агрессивность» и низким уровнем показателей «Благоприятная семейная обстановка» в полных и неполных семьях?
Критерий достоверности сдвига
Задача 12. Со школьниками проводится коррекционная работа по формированию навыков внимания. Будет ли уменьшаться количество ошибок внимания у школьников после специальных коррекционных упражнений? В таблице приведено количество ошибок при выполнении корректурной пробы до и после коррекционных упражнений.
Другие темы
Задача 13. В двух пятых классах проводилось тестирование умственного развития по тесту ТУРМШ десяти учащихся. Есть ли различия в степени однородности показателей умственного развития между классами?
Задача 14. Существуют ли различия в успешности решения двух различных по сложности мыслительных задач? Группа из 100 учащихся решала оба типа задач.
Задача 15. У 8 подростков сравниваются баллы по третьему, математическому субтесту Векслера (переменная X) и оценки по алгебре (переменная Y). На сколько баллов повысится успешность решения третьего субтеста Векслера, если оценка по алгебре повысится на 1 балл?
Задача 16. Девочкам и мальчикам 13 лет предлагали опросник «Я-концепция» Пирс-Харриса. На вопрос «Когда я вырасту, я стану важным лицом» ответили из 12 девочек «да» - 11, а из 10 мальчиков – 6. Остальные ответили «нет». Можно ли судить о половых различиях при ответе на данный вопрос? Можно ли утверждать, что девочки в этом возрасте на данный вопрос отвечают чаще «да» чем «нет», а у мальчиков такой тенденции не выявлено.
Глава 1. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ СЛУЧАЙНЫХ СОБЫТИЙ
1.1. СОБЫТИЕ И МЕРЫ ВОЗМОЖНОСТИ ЕГО ПОЯВЛЕНИЯ
1.1.1. Понятие о событии
1.1.2. Случайные и неслучайные события
1.1.3. Частота частость и вероятность
1.1.4. Статистическое определение вероятности
1.1.5. Геометрическое определение вероятности
1.2. СИСТЕМА СЛУЧАЙНЫХ СОБЫТИЙ
1.2.1. Понятие о системе событий
1.2.2. Совместное появление событий
1.2.3. Зависимость между событиями
1.2.4. Преобразования событий
1.2.5. Уровни количественного определения событий
1.3. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ КЛАССИФИЦИРОВАННЫХ СОБЫТИЙ
1.3.1. Распределения вероятностей событий
1.3.2. Ранжирование событий в системе по вероятностям
1.3.3. Меры связи между классифицированными событиями
1.3.4. Последовательности событий
1.4. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ СИСТЕМЫ УПОРЯДОЧЕННЫХ СОБЫТИЙ
1.4.1. Ранжирование событий по величине
1.4.2. Распределение вероятностей ранжированной системы упорядоченных событий
1.4.3. Количественные характеристики распределения вероятностей системы упорядоченных событий
1.4.4. Меры корреляции рангов
Глава 2. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ СЛУЧАЙНОЙ ВЕЛИЧИНЫ
2.1. СЛУЧАЙНАЯ ВЕЛИЧИНА И ЕЕ РАСПРЕДЕЛЕНИЕ
2.1.1. Случайная величина
2.1.2. Распределение вероятностей значений случайной величины
2.1.3. Основные свойства распределений
2.2. ЧИСЛОВЫЕ ХАРАКТЕРИСТИКИ РАСПРЕДЕЛЕНИЯ
2.2.1. Меры положения
2.2.2. Меры асимметрии и эксцесса
2.3. ОПРЕДЕЛЕНИЕ ЧИСЛОВЫХ ХАРАКТЕРИСТИК ПО ЭКСПЕРИМЕНТАЛЬНЫМ ДАННЫМ
2.3.1. Исходные положения
2.3.2. Вычисление мер положения рассеивания асимметрии и эксцесса по несгруппированным данным
2.3.3. Группировка данных и получение эмпирических распределений
2.3.4. Вычисление мер положения рассеивания асимметрии и эксцесса по эмпирическому распределению
2.4. ВИДЫ ЗАКОНОВ РАСПРЕДЕЛЕНИЯ СЛУЧАЙНОЙ ВЕЛИЧИНЫ
2.4.1. Общие положения
2.4.2. Нормальный закон
2.4.3. Нормализация распределений
2.4.4. Некоторые другие законы распределения важные для психологии
Глава 3. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ ДВУМЕРНОЙ СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
3.1. РАСПРЕДЕЛЕНИЯ В СИСТЕМЕ ИЗ ДВУХ СЛУЧАЙНЫХ ВЕЛИЧИН
3.1.1. Система из двух случайных величин
3.1.2. Совместное распределение двух случайных величин
3.1.3. Частные безусловные и условные эмпирические распределения и взаимосвязь случайных величин в двумерной системе
3.2. ХАРАКТЕРИСТИКИ ПОЛОЖЕНИЯ РАССЕИВАНИЯ И СВЯЗИ
3.2.1. Числовые характеристики положения и рассеивания
3.2.2. Простые регрессии
3.2.3. Меры корреляции
3.2.4. Совокупные характеристики положения рассеивания и связи
3.3. ОПРЕДЕЛЕНИЕ КОЛИЧЕСТВЕННЫХ ХАРАКТЕРИСТИК ДВУМЕРНОЙ СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН ПО ДАННЫМ ЭКСПЕРИМЕНТА
3.3.1. Аппроксимация простой регрессии
3.3.2. Определение числовых характеристик при небольшом количестве экспериментальных данных
3.3.3. Полный расчет количественных характеристик двумерной системы
3.3.4. Расчет совокупных характеристик двумерной системы
Глава 4. КОЛИЧЕСТВЕННЫЕ ХАРАКТЕРИСТИКИ МНОГОМЕРНОЙ СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН
4.1. МНОГОМЕРНЫЕ СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН И ИХ ХАРАКТЕРИСТИКИ
4.1.1. Понятие о многомерной системе
4.1.2. Разновидности многомерных систем
4.1.3. Распределения в многомерной системе
4.1.4. Числовые характеристики в многомерной системе
4.2. НЕСЛУЧАЙНЫЕ ФУНКЦИИ ОТ СЛУЧАЙНЫХ АРГУМЕНТОВ
4.2.1. Числовые характеристики суммы и произведения случайных величин
4.2.2. Законы распределения линейной функции от случайных аргументов
4.2.3. Множественные линейные регрессии
4.3. ОПРЕДЕЛЕНИЕ ЧИСЛОВЫХ ХАРАКТЕРИСТИК МНОГОМЕРНОЙ СИСТЕМЫ СЛУЧАЙНЫХ ВЕЛИЧИН ПО ДАННЫМ ЭКСПЕРИМЕНТА
4.3.1. Оценка вероятностей многомерного распределения
4.3.2. Определение множественных регрессий и связанных с ними числовых характеристик
4.4. СЛУЧАЙНЫЕ ФУНКЦИИ
4.4.1. Свойства и количественные характеристики случайных функций
4.4.2. Некоторые классы случайных функций важные для психологии
4.4.3. Определение характеристик случайной функции из эксперимента
Глава 5. СТАТИСТИЧЕСКАЯ ПРОВЕРКА ГИПОТЕЗ
5.1. ЗАДАЧИ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ
5.1.1. Генеральная совокупность и выборка
5.1.2. Количественные характеристики генеральной совокупности и выборки
5.1.3. Погрешности статистических оценок
5.1.4. Задачи статистической проверки гипотез в психологических исследованиях
5.2. СТАТИСТИЧЕСКИЕ КРИТЕРИИ ОЦЕНИВАНИЯ И ПРОВЕРКИ ГИПОТЕЗ
5.2.1. Понятие о статистических критериях
5.2.2. х-критерий Пирсона
5.2.3. Основные параметрические критерии
5.3. ОСНОВНЫЕ МЕТОДЫ СТАТИСТИЧЕСКОЙ ПРОВЕРКИ ГИПОТЕЗ
5.3.1. Метод максимального правдоподобия
5.3.2. Метод Бейеса
5.3.3. Классический метод определения параметра функции с заданной точностью
5.3.4. Метод проектирования репрезентативной выборки по модели совокупности
5.3.5. Метод последовательной проверки статистических гипотез
Глава 6. ОСНОВЫ ДИСПЕРСИОННОГО АНАЛИЗА И МАТЕМАТИЧЕСКОГО ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА
6.1. ПОНЯТИЕ О ДИСПЕРСИОННОМ АНАЛИЗЕ
6.1.1. Сущность дисперсионного анализа
6.1.2. Предпосылки дисперсионного анализа
6.1.3. Задачи дисперсионного анализа
6.1.4. Виды дисперсионного анализа
6.2. ОДНОФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ
6.2.1. Схема расчета при одинаковом количестве повторных испытаний
6.2.2. Схема расчета при разном количестве повторных испытаний
6.3. ДВУХФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ
6.3.1. Схема расчета при отсутствии повторных испытаний
6.3.2. Схема расчета при наличии повторных испытаний
6.4. Трехфакторный дисперсионный анализ
6.5. ОСНОВЫ МАТЕМАТИЧЕСКОГО ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА
6.5.1. Понятие о математическом планировании эксперимента
6.5.2. Построение полного ортогонального плана эксперимента
6.5.3. Обработка результатов математически спланированного эксперимента
Глава 7. ОСНОВЫ ФАКТОРНОГО АНАЛИЗА
7.1. ПОНЯТИЕ О ФАКТОРНОМ АНАЛИЗЕ
7.1.1. Сущность факторного анализа
7.1.2. Разновидности методов факторного анализа
7.1.3. Задачи факторного анализа в психологии
7.2. ОДНОФАКТОРНЫЙ АНАЛИЗ
7.3. МУЛЬТИФАКТОРНЫЙ АНАЛИЗ
7.3.1. Геометрическая интерпретация корреляционной и факторной матриц
7.3.2. Центроидный метод факторизации
7.3.3. Простая латентная структура и ротация
7.3.4. Пример мультифакторного анализа с ортогональной ротацией
Приложение 1. ПОЛЕЗНЫЕ СВЕДЕНИЯ О МАТРИЦАХ И ДЕЙСТВИЯХ С НИМИ
Приложение 2. МАТЕМАТИКО-СТАТИСТИЧЕСКИЕ ТАБЛИЦЫ
РЕКОМЕНДУЕМАЯ ЛИТЕРАТУРА
 Могильники Чернобыля: радиоактивные отходы зоны отчуждения Где находится техника чернобыля
Могильники Чернобыля: радиоактивные отходы зоны отчуждения Где находится техника чернобыля Девочка заговорила на иностранном языке после комы
Девочка заговорила на иностранном языке после комы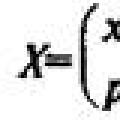 Сравнение законов распределения вероятностей
Сравнение законов распределения вероятностей